Automatic Speech Recognition for Hindi
2406.18135
0
0
🗣️
Abstract
Automatic speech recognition (ASR) is a key area in computational linguistics, focusing on developing technologies that enable computers to convert spoken language into text. This field combines linguistics and machine learning. ASR models, which map speech audio to transcripts through supervised learning, require handling real and unrestricted text. Text-to-speech systems directly work with real text, while ASR systems rely on language models trained on large text corpora. High-quality transcribed data is essential for training predictive models. The research involved two main components: developing a web application and designing a web interface for speech recognition. The web application, created with JavaScript and Node.js, manages large volumes of audio files and their transcriptions, facilitating collaborative human correction of ASR transcripts. It operates in real-time using a client-server architecture. The web interface for speech recognition records 16 kHz mono audio from any device running the web app, performs voice activity detection (VAD), and sends the audio to the recognition engine. VAD detects human speech presence, aiding efficient speech processing and reducing unnecessary processing during non-speech intervals, thus saving computation and network bandwidth in VoIP applications. The final phase of the research tested a neural network for accurately aligning the speech signal to hidden Markov model (HMM) states. This included implementing a novel backpropagation method that utilizes prior statistics of node co-activations.
Create account to get full access
Overview
- Automatic speech recognition (ASR) is a field of computational linguistics that aims to develop technologies for converting spoken language into text.
- ASR combines linguistics and machine learning, relying on language models trained on large text corpora to map speech audio to transcripts.
- The research described in the paper focused on developing a web application and a web interface for speech recognition, with the goal of facilitating collaborative human correction of ASR transcripts.
Plain English Explanation
Automatic speech recognition (ASR) is a technology that allows computers to understand and convert spoken language into written text. This field combines linguistics and machine learning. ASR models are trained on large text datasets to learn how to map audio of people speaking to written transcripts of what they said.
The research described in this paper aimed to create a web application and interface to help improve the accuracy of ASR systems. The web application, built with JavaScript and Node.js, can handle large volumes of audio files and their transcriptions. It allows people to work together to correct any mistakes in the transcripts generated by the ASR system.
The web interface for the speech recognition system records audio from any device and sends it to the recognition engine. It uses a technique called voice activity detection (VAD) to identify when a person is actually speaking, which helps the system process the audio more efficiently and save on computing power and network bandwidth.
Finally, the researchers tested a machine learning model called a neural network to better align the speech audio with the underlying patterns in the language model, improving the accuracy of the ASR system.
Technical Explanation
The research involved developing a web application and a web interface for speech recognition. The web application, created with JavaScript and Node.js, manages large volumes of audio files and their transcriptions. It operates in real-time using a client-server architecture, allowing for collaborative human correction of ASR transcripts.
The web interface for speech recognition records 16 kHz mono audio from any device running the web app. It performs voice activity detection (VAD), which detects the presence of human speech, enabling efficient speech processing and reducing unnecessary processing during non-speech intervals. This saves computation and network bandwidth, which is particularly important for VoIP applications.
The final phase of the research tested a neural network for accurately aligning the speech signal to hidden Markov model (HMM) states. This included implementing a novel backpropagation method that utilizes prior statistics of node co-activations, which helped improve the accuracy of the ASR system.
Critical Analysis
The paper provides a comprehensive overview of the development of the web application and web interface for speech recognition, addressing key technical challenges such as handling large audio files, enabling collaborative transcript correction, and improving the alignment of speech signals to language models.
However, the paper does not discuss any potential limitations or caveats of the proposed approach. For example, it does not explore the performance of the system on low-resource languages or specialized domains, which are common challenges in the field of industrial-scale multilingual ASR.
Additionally, the paper does not address potential privacy and security concerns related to the web-based nature of the application, or the ethical implications of deploying such a system in real-world scenarios.
Conclusion
This research represents an important step forward in the development of user-friendly and collaborative tools for improving the accuracy of automatic speech recognition systems. By creating a web-based platform that allows for the correction of ASR transcripts, the researchers have demonstrated the potential for crowdsourcing and human-in-the-loop approaches to enhance the performance of these technologies.
The novel techniques employed, such as the use of voice activity detection and the improved alignment of speech signals to language models, have the potential to contribute to advancements in the broader field of computational linguistics and speech processing. As the research continues, it will be important to address the limitations and explore the real-world implications of these systems, ensuring they are developed and deployed in an ethical and responsible manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Error-preserving Automatic Speech Recognition of Young English Learners' Language
Janick Michot, Manuela Hurlimann, Jan Deriu, Luzia Sauer, Katsiaryna Mlynchyk, Mark Cieliebak
0
0
One of the central skills that language learners need to practice is speaking the language. Currently, students in school do not get enough speaking opportunities and lack conversational practice. Recent advances in speech technology and natural language processing allow for the creation of novel tools to practice their speaking skills. In this work, we tackle the first component of such a pipeline, namely, the automated speech recognition module (ASR), which faces a number of challenges: first, state-of-the-art ASR models are often trained on adult read-aloud data by native speakers and do not transfer well to young language learners' speech. Second, most ASR systems contain a powerful language model, which smooths out errors made by the speakers. To give corrective feedback, which is a crucial part of language learning, the ASR systems in our setting need to preserve the errors made by the language learners. In this work, we build an ASR system that satisfies these requirements: it works on spontaneous speech by young language learners and preserves their errors. For this, we collected a corpus containing around 85 hours of English audio spoken by learners in Switzerland from grades 4 to 6 on different language learning tasks, which we used to train an ASR model. Our experiments show that our model benefits from direct fine-tuning on children's voices and has a much higher error preservation rate than other models.
6/6/2024

Automatic Speech Recognition for Biomedical Data in Bengali Language
Shariar Kabir, Nazmun Nahar, Shyamasree Saha, Mamunur Rashid
0
0
This paper presents the development of a prototype Automatic Speech Recognition (ASR) system specifically designed for Bengali biomedical data. Recent advancements in Bengali ASR are encouraging, but a lack of domain-specific data limits the creation of practical healthcare ASR models. This project bridges this gap by developing an ASR system tailored for Bengali medical terms like symptoms, severity levels, and diseases, encompassing two major dialects: Bengali and Sylheti. We train and evaluate two popular ASR frameworks on a comprehensive 46-hour Bengali medical corpus. Our core objective is to create deployable health-domain ASR systems for digital health applications, ultimately increasing accessibility for non-technical users in the healthcare sector.
6/21/2024
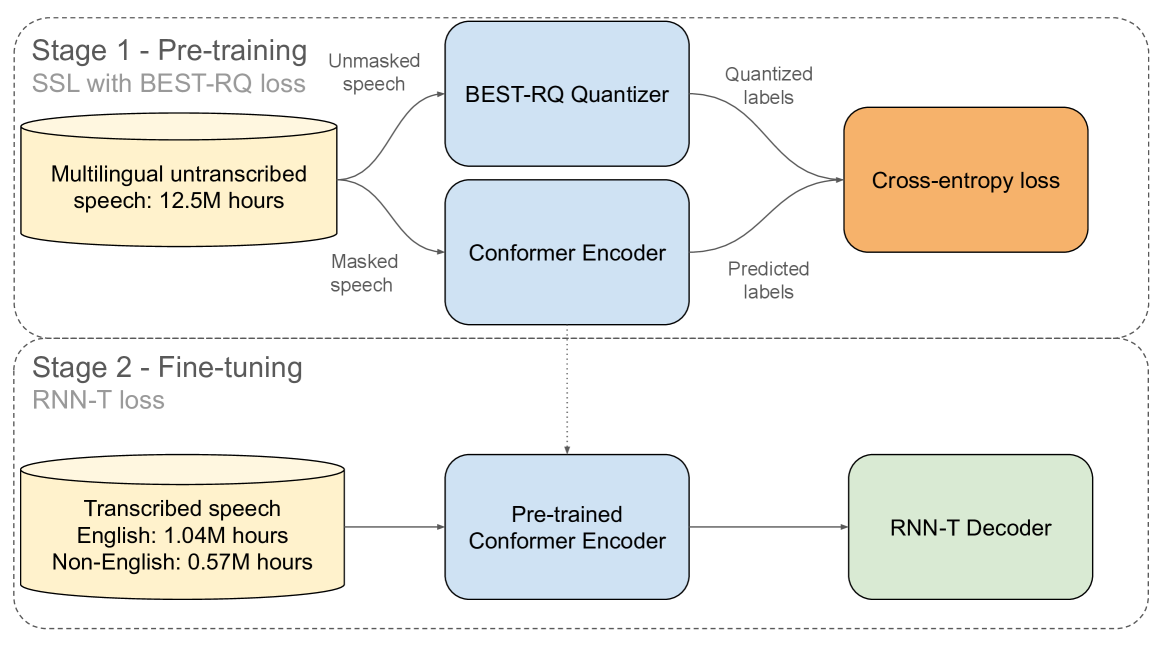
Anatomy of Industrial Scale Multilingual ASR
Francis McCann Ramirez, Luka Chkhetiani, Andrew Ehrenberg, Robert McHardy, Rami Botros, Yash Khare, Andrea Vanzo, Taufiquzzaman Peyash, Gabriel Oexle, Michael Liang, Ilya Sklyar, Enver Fakhan, Ahmed Etefy, Daniel McCrystal, Sam Flamini, Domenic Donato, Takuya Yoshioka
0
0
This paper describes AssemblyAI's industrial-scale automatic speech recognition (ASR) system, designed to meet the requirements of large-scale, multilingual ASR serving various application needs. Our system leverages a diverse training dataset comprising unsupervised (12.5M hours), supervised (188k hours), and pseudo-labeled (1.6M hours) data across four languages. We provide a detailed description of our model architecture, consisting of a full-context 600M-parameter Conformer encoder pre-trained with BEST-RQ and an RNN-T decoder fine-tuned jointly with the encoder. Our extensive evaluation demonstrates competitive word error rates (WERs) against larger and more computationally expensive models, such as Whisper large and Canary-1B. Furthermore, our architectural choices yield several key advantages, including an improved code-switching capability, a 5x inference speedup compared to an optimized Whisper baseline, a 30% reduction in hallucination rate on speech data, and a 90% reduction in ambient noise compared to Whisper, along with significantly improved time-stamp accuracy. Throughout this work, we adopt a system-centric approach to analyzing various aspects of fully-fledged ASR models to gain practically relevant insights useful for real-world services operating at scale.
4/17/2024
🗣️
Semantically Corrected Amharic Automatic Speech Recognition
Samuael Adnew, Paul Pu Liang
0
0
Automatic Speech Recognition (ASR) can play a crucial role in enhancing the accessibility of spoken languages worldwide. In this paper, we build a set of ASR tools for Amharic, a language spoken by more than 50 million people primarily in eastern Africa. Amharic is written in the Ge'ez script, a sequence of graphemes with spacings denoting word boundaries. This makes computational processing of Amharic challenging since the location of spacings can significantly impact the meaning of formed sentences. We find that existing benchmarks for Amharic ASR do not account for these spacings and only measure individual grapheme error rates, leading to significantly inflated measurements of in-the-wild performance. In this paper, we first release corrected transcriptions of existing Amharic ASR test datasets, enabling the community to accurately evaluate progress. Furthermore, we introduce a post-processing approach using a transformer encoder-decoder architecture to organize raw ASR outputs into a grammatically complete and semantically meaningful Amharic sentence. Through experiments on the corrected test dataset, our model enhances the semantic correctness of Amharic speech recognition systems, achieving a Character Error Rate (CER) of 5.5% and a Word Error Rate (WER) of 23.3%.
4/23/2024