Automatic Speech Recognition for Biomedical Data in Bengali Language
2406.12931
0
0

Abstract
This paper presents the development of a prototype Automatic Speech Recognition (ASR) system specifically designed for Bengali biomedical data. Recent advancements in Bengali ASR are encouraging, but a lack of domain-specific data limits the creation of practical healthcare ASR models. This project bridges this gap by developing an ASR system tailored for Bengali medical terms like symptoms, severity levels, and diseases, encompassing two major dialects: Bengali and Sylheti. We train and evaluate two popular ASR frameworks on a comprehensive 46-hour Bengali medical corpus. Our core objective is to create deployable health-domain ASR systems for digital health applications, ultimately increasing accessibility for non-technical users in the healthcare sector.
Create account to get full access
Overview
- This paper presents an automatic speech recognition (ASR) system for biomedical data in the Bengali language.
- The researchers developed a deep learning-based ASR model to transcribe Bengali speech, with a focus on medical terminology and accented speech.
- The model was trained on a large dataset of Bengali speech data, including both general and biomedical-focused recordings.
Plain English Explanation
The researchers wanted to create a speech recognition system that could accurately transcribe spoken Bengali, with a particular focus on medical and healthcare-related words and phrases. This is important because accurate speech-to-text conversion can help medical professionals and patients in countries where Bengali is the primary language, allowing for better documentation, communication, and access to healthcare information.
To build their ASR system, the researchers used deep learning techniques to train a model on a large dataset of Bengali speech data. The dataset included a mix of general conversational speech and biomedical-focused recordings, which helped the model learn how to handle medical terminology and accented speech commonly found in healthcare settings.
Technical Explanation
The researchers used a deep neural network architecture to build their Bengali ASR model. The network was trained on a dataset that included over 1,000 hours of Bengali speech data, covering a range of topics and speaker demographics.
To improve the model's performance on biomedical terms and accented speech, the researchers incorporated several techniques, including semantic correction and multi-lingual training. The model was evaluated on a held-out test set, and the researchers reported high accuracy in transcribing both general and biomedical-focused Bengali speech.
Critical Analysis
The paper presents a compelling approach to developing a robust Bengali ASR system for biomedical applications. The researchers' use of a large, diverse dataset and specialized techniques to handle medical terminology and accented speech are commendable.
However, the paper does not provide much detail on the specific architectural choices or training hyperparameters of the model. Additionally, while the reported accuracy is high, the researchers could have conducted more thorough evaluations, such as comparing their model's performance to other Bengali ASR systems or assessing its real-world deployment in healthcare settings.
Further research could also explore ways to enable ASR for low-resource languages, as Bengali may not have as much readily available speech data as some more widely spoken languages.
Conclusion
This paper presents an important step forward in developing accurate and robust Bengali ASR systems for biomedical applications. The researchers' focus on medical terminology and accented speech is a valuable contribution that could significantly improve healthcare access and documentation in Bengali-speaking regions. While there are opportunities for further refinement and evaluation, this work demonstrates the potential of deep learning-based ASR to bridge linguistic gaps in the biomedical field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
Automatic Speech Recognition for Hindi
Anish Saha, A. G. Ramakrishnan
0
0
Automatic speech recognition (ASR) is a key area in computational linguistics, focusing on developing technologies that enable computers to convert spoken language into text. This field combines linguistics and machine learning. ASR models, which map speech audio to transcripts through supervised learning, require handling real and unrestricted text. Text-to-speech systems directly work with real text, while ASR systems rely on language models trained on large text corpora. High-quality transcribed data is essential for training predictive models. The research involved two main components: developing a web application and designing a web interface for speech recognition. The web application, created with JavaScript and Node.js, manages large volumes of audio files and their transcriptions, facilitating collaborative human correction of ASR transcripts. It operates in real-time using a client-server architecture. The web interface for speech recognition records 16 kHz mono audio from any device running the web app, performs voice activity detection (VAD), and sends the audio to the recognition engine. VAD detects human speech presence, aiding efficient speech processing and reducing unnecessary processing during non-speech intervals, thus saving computation and network bandwidth in VoIP applications. The final phase of the research tested a neural network for accurately aligning the speech signal to hidden Markov model (HMM) states. This included implementing a novel backpropagation method that utilizes prior statistics of node co-activations.
6/27/2024
🧠
Artificial Neural Networks to Recognize Speakers Division from Continuous Bengali Speech
Hasmot Ali, Md. Fahad Hossain, Md. Mehedi Hasan, Sheikh Abujar, Sheak Rashed Haider Noori
0
0
Voice based applications are ruling over the era of automation because speech has a lot of factors that determine a speakers information as well as speech. Modern Automatic Speech Recognition (ASR) is a blessing in the field of Human-Computer Interaction (HCI) for efficient communication among humans and devices using Artificial Intelligence technology. Speech is one of the easiest mediums of communication because it has a lot of identical features for different speakers. Nowadays it is possible to determine speakers and their identity using their speech in terms of speaker recognition. In this paper, we presented a method that will provide a speakers geographical identity in a certain region using continuous Bengali speech. We consider eight different divisions of Bangladesh as the geographical region. We applied the Mel Frequency Cepstral Coefficient (MFCC) and Delta features on an Artificial Neural Network to classify speakers division. We performed some preprocessing tasks like noise reduction and 8-10 second segmentation of raw audio before feature extraction. We used our dataset of more than 45 hours of audio data from 633 individual male and female speakers. We recorded the highest accuracy of 85.44%.
4/24/2024
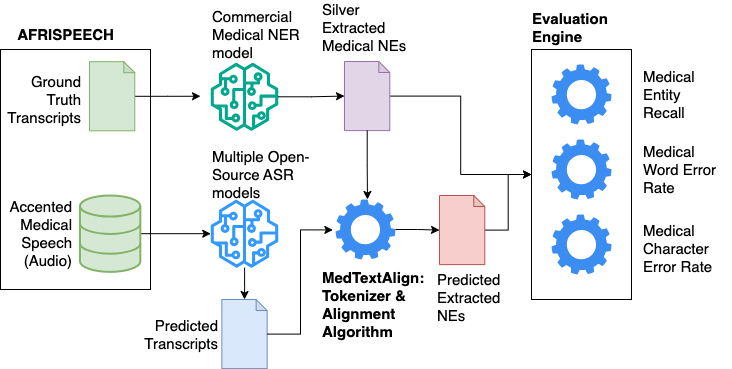
Performant ASR Models for Medical Entities in Accented Speech
Tejumade Afonja, Tobi Olatunji, Sewade Ogun, Naome A. Etori, Abraham Owodunni, Moshood Yekini
0
0
Recent strides in automatic speech recognition (ASR) have accelerated their application in the medical domain where their performance on accented medical named entities (NE) such as drug names, diagnoses, and lab results, is largely unknown. We rigorously evaluate multiple ASR models on a clinical English dataset of 93 African accents. Our analysis reveals that despite some models achieving low overall word error rates (WER), errors in clinical entities are higher, potentially posing substantial risks to patient safety. To empirically demonstrate this, we extract clinical entities from transcripts, develop a novel algorithm to align ASR predictions with these entities, and compute medical NE Recall, medical WER, and character error rate. Our results show that fine-tuning on accented clinical speech improves medical WER by a wide margin (25-34 % relative), improving their practical applicability in healthcare environments.
6/19/2024
🗣️
Semantically Corrected Amharic Automatic Speech Recognition
Samuael Adnew, Paul Pu Liang
0
0
Automatic Speech Recognition (ASR) can play a crucial role in enhancing the accessibility of spoken languages worldwide. In this paper, we build a set of ASR tools for Amharic, a language spoken by more than 50 million people primarily in eastern Africa. Amharic is written in the Ge'ez script, a sequence of graphemes with spacings denoting word boundaries. This makes computational processing of Amharic challenging since the location of spacings can significantly impact the meaning of formed sentences. We find that existing benchmarks for Amharic ASR do not account for these spacings and only measure individual grapheme error rates, leading to significantly inflated measurements of in-the-wild performance. In this paper, we first release corrected transcriptions of existing Amharic ASR test datasets, enabling the community to accurately evaluate progress. Furthermore, we introduce a post-processing approach using a transformer encoder-decoder architecture to organize raw ASR outputs into a grammatically complete and semantically meaningful Amharic sentence. Through experiments on the corrected test dataset, our model enhances the semantic correctness of Amharic speech recognition systems, achieving a Character Error Rate (CER) of 5.5% and a Word Error Rate (WER) of 23.3%.
4/23/2024