Imagination Augmented Generation: Learning to Imagine Richer Context for Question Answering over Large Language Models

0
Sign in to get full access
Overview
- This paper presents a method called "Imagination Augmented Generation" that aims to improve question answering performance of large language models by learning to imagine richer context.
- The key idea is to train a model to generate additional contextual information that can enhance the language model's understanding and response to a given question.
- The approach is evaluated on two question answering benchmarks, demonstrating improved performance compared to baseline language models.
Plain English Explanation
Large language models like GPT-3 are impressive at tasks like question answering, but their responses can sometimes lack important context or details. The Imagination Augmented Generation method tries to address this by training a model to "imagine" additional relevant information that can enrich the language model's understanding.
The way it works is that the model is trained to generate extra context around a given question. This generated context is then combined with the original question and passed to the language model, which can then use the richer information to provide a more complete and accurate answer.
For example, if the question is "Who was the first president of the United States?", the model might generate some additional context like "The United States was founded in 1776 after gaining independence from Great Britain. George Washington was elected as the first president in 1789 and served two terms until 1797."
Providing this extra background information can help the language model better understand the question and formulate a more thorough response.
The researchers tested this approach on two standard question answering benchmarks and found that it improved performance compared to using the language model alone. This suggests that "imagining" richer context is a promising way to enhance the capabilities of large language models for tasks like question answering.
Technical Explanation
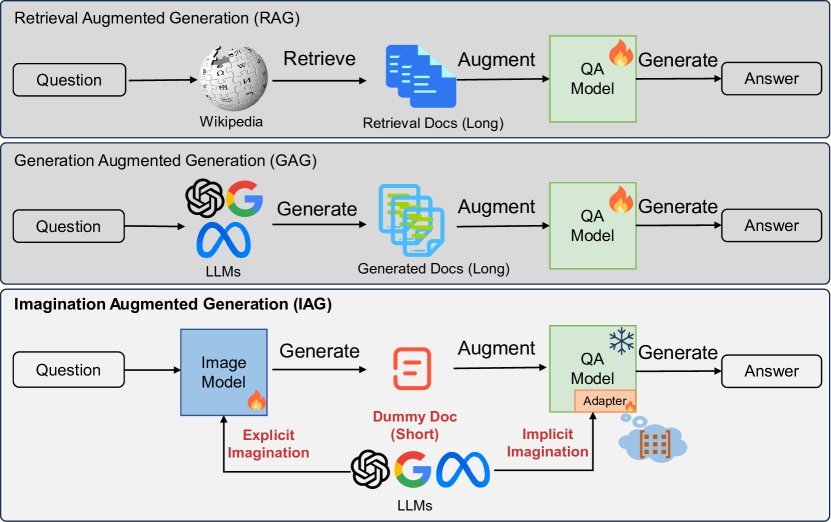
The core of the Imagination Augmented Generation method is a generator model that is trained to produce additional contextual information relevant to a given question. This "imagined" context is then concatenated with the original question and passed to a pre-trained language model, which can then use the richer input to provide a better answer.
The generator model is trained in a supervised way, using pairs of questions and their corresponding "imagined" context from a dataset. The generator takes the question as input and outputs a sequence of tokens representing the additional context. This context is then combined with the original question and fed into the language model, which outputs the final answer.
The researchers evaluate their approach on two popular question answering benchmarks - Natural Questions and TriviaQA. They compare the performance of the language model alone to the language model enhanced with the imagined context, and find statistically significant improvements on both datasets.
The intuition is that by learning to generate relevant additional context, the model can provide the language model with a richer understanding of the question, allowing it to formulate more informative and accurate responses. This "imagination" of supplementary information is a novel approach to enhance the capabilities of large language models.
Critical Analysis
The Imagination Augmented Generation method represents an interesting and promising step towards improving the performance of large language models on complex tasks like question answering. The key innovation - training a generator to produce relevant contextual information - is a creative approach that seems to yield tangible benefits.
However, the paper does acknowledge some limitations. The generator model is trained in a supervised fashion, which means it requires access to a dataset of questions paired with their corresponding "imagined" context. Collecting such datasets at scale could be challenging, and the quality of the generator's output may be heavily dependent on the breadth and diversity of the training data.
Additionally, the paper does not explore the interpretability or transparency of the generated context. It would be valuable to understand how the generator model decides what additional information to produce, and whether the augmented context is truly relevant and helpful for the language model, or if it introduces irrelevant or potentially misleading information.
Further research could also investigate the generalization of this approach to other language tasks beyond question answering, as well as its robustness to distribution shift or adversarial attacks. Exploring these areas could help solidify the Imagination Augmented Generation method as a valuable tool for enhancing the capabilities of large language models.
Conclusion
The Imagination Augmented Generation paper presents an innovative approach to improving question answering performance by training a model to generate relevant contextual information that can enrich the understanding of a pre-trained language model.
The key insight - that "imagining" additional context can boost language model capabilities - is a creative and promising direction for the field of natural language processing. While the current implementation has some limitations, the overall concept represents an exciting step towards building more capable and contextualized language AI systems.
As the field of large language models continues to evolve, techniques like Imagination Augmented Generation will likely play an important role in expanding their abilities and making them more robust and reliable for real-world applications. Further research in this area could yield valuable insights and advancements in the quest to develop truly intelligent and versatile language understanding systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Imagination Augmented Generation: Learning to Imagine Richer Context for Question Answering over Large Language Models
Huanxuan Liao, Shizhu He, Yao Xu, Yuanzhe Zhang, Kang Liu, Shengping Liu, Jun Zhao
Retrieval-Augmented-Generation and Generation-Augmented-Generation have been proposed to enhance the knowledge required for question answering with Large Language Models (LLMs) by leveraging richer context. However, the former relies on external resources, and both require incorporating explicit documents into the context, which increases execution costs and susceptibility to noise data during inference. Recent works indicate that LLMs model rich knowledge, but it is often not effectively activated and awakened. Inspired by this, we propose a novel knowledge-augmented framework, $textbf{Awakening-Augmented-Generation}$ (AAG), which mimics the human ability to answer questions using only thinking and recalling to compensate for knowledge gaps, thereby awaking relevant knowledge in LLMs without relying on external resources. AAG consists of two key components for awakening richer context. Explicit awakening fine-tunes a context generator to create a synthetic, compressed document that functions as symbolic context. Implicit awakening utilizes a hypernetwork to generate adapters based on the question and synthetic document, which are inserted into LLMs to serve as parameter context. Experimental results on three datasets demonstrate that AAG exhibits significant advantages in both open-domain and closed-book settings, as well as in out-of-distribution generalization. Our code will be available at url{https://github.com/Xnhyacinth/IAG}.
Read more9/23/2024

0
KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation
Lei Liang, Mengshu Sun, Zhengke Gui, Zhongshu Zhu, Zhouyu Jiang, Ling Zhong, Yuan Qu, Peilong Zhao, Zhongpu Bo, Jin Yang, Huaidong Xiong, Lin Yuan, Jun Xu, Zaoyang Wang, Zhiqiang Zhang, Wen Zhang, Huajun Chen, Wenguang Chen, Jun Zhou
The recently developed retrieval-augmented generation (RAG) technology has enabled the efficient construction of domain-specific applications. However, it also has limitations, including the gap between vector similarity and the relevance of knowledge reasoning, as well as insensitivity to knowledge logic, such as numerical values, temporal relations, expert rules, and others, which hinder the effectiveness of professional knowledge services. In this work, we introduce a professional domain knowledge service framework called Knowledge Augmented Generation (KAG). KAG is designed to address the aforementioned challenges with the motivation of making full use of the advantages of knowledge graph(KG) and vector retrieval, and to improve generation and reasoning performance by bidirectionally enhancing large language models (LLMs) and KGs through five key aspects: (1) LLM-friendly knowledge representation, (2) mutual-indexing between knowledge graphs and original chunks, (3) logical-form-guided hybrid reasoning engine, (4) knowledge alignment with semantic reasoning, and (5) model capability enhancement for KAG. We compared KAG with existing RAG methods in multihop question answering and found that it significantly outperforms state-of-theart methods, achieving a relative improvement of 19.6% on 2wiki and 33.5% on hotpotQA in terms of F1 score. We have successfully applied KAG to two professional knowledge Q&A tasks of Ant Group, including E-Government Q&A and E-Health Q&A, achieving significant improvement in professionalism compared to RAG methods.
Read more9/27/2024
2
Context-augmented Retrieval: A Novel Framework for Fast Information Retrieval based Response Generation using Large Language Model
Sai Ganesh, Anupam Purwar, Gautam B
Generating high-quality answers consistently by providing contextual information embedded in the prompt passed to the Large Language Model (LLM) is dependent on the quality of information retrieval. As the corpus of contextual information grows, the answer/inference quality of Retrieval Augmented Generation (RAG) based Question Answering (QA) systems declines. This work solves this problem by combining classical text classification with the Large Language Model (LLM) to enable quick information retrieval from the vector store and ensure the relevancy of retrieved information. For the same, this work proposes a new approach Context Augmented retrieval (CAR), where partitioning of vector database by real-time classification of information flowing into the corpus is done. CAR demonstrates good quality answer generation along with significant reduction in information retrieval and answer generation time.
Read more8/1/2024
🛸
0
Retrieval Augmented Generation for Domain-specific Question Answering
Sanat Sharma, David Seunghyun Yoon, Franck Dernoncourt, Dewang Sultania, Karishma Bagga, Mengjiao Zhang, Trung Bui, Varun Kotte
Question answering (QA) has become an important application in the advanced development of large language models. General pre-trained large language models for question-answering are not trained to properly understand the knowledge or terminology for a specific domain, such as finance, healthcare, education, and customer service for a product. To better cater to domain-specific understanding, we build an in-house question-answering system for Adobe products. We propose a novel framework to compile a large question-answer database and develop the approach for retrieval-aware finetuning of a Large Language model. We showcase that fine-tuning the retriever leads to major improvements in the final generation. Our overall approach reduces hallucinations during generation while keeping in context the latest retrieval information for contextual grounding.
Read more5/30/2024