Background Noise Reduction of Attention Map for Weakly Supervised Semantic Segmentation
2404.03394
0
0

Abstract
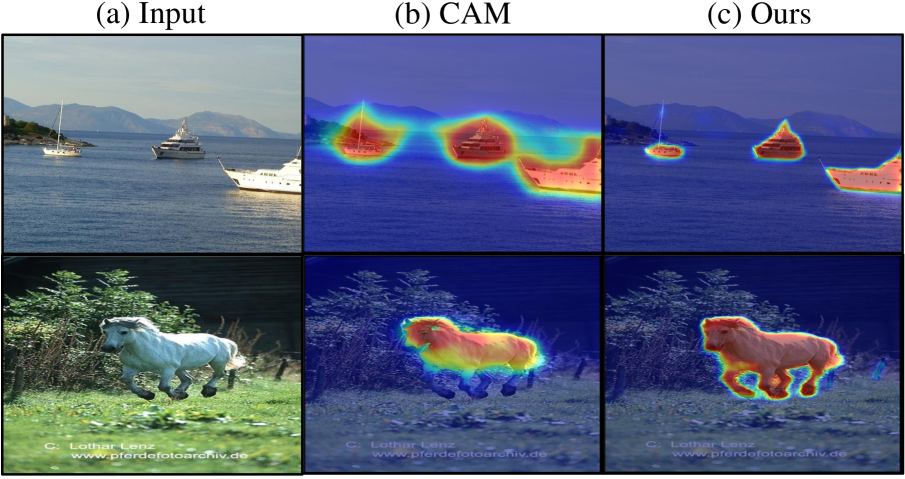
In weakly-supervised semantic segmentation (WSSS) using only image-level class labels, a problem with CNN-based Class Activation Maps (CAM) is that they tend to activate the most discriminative local regions of objects. On the other hand, methods based on Transformers learn global features but suffer from the issue of background noise contamination. This paper focuses on addressing the issue of background noise in attention weights within the existing WSSS method based on Conformer, known as TransCAM. The proposed method successfully reduces background noise, leading to improved accuracy of pseudo labels. Experimental results demonstrate that our model achieves segmentation performance of 70.5% on the PASCAL VOC 2012 validation data, 71.1% on the test data, and 45.9% on MS COCO 2014 data, outperforming TransCAM in terms of segmentation performance.
Create account to get full access
Overview
- This paper proposes a novel approach to reducing background noise in attention maps for weakly supervised semantic segmentation.
- The key idea is to leverage a pre-trained network to identify and suppress irrelevant regions in the attention map, which can improve the performance of weakly supervised segmentation models.
- The proposed method is evaluated on several benchmark datasets and shows significant improvements over existing weakly supervised semantic segmentation techniques.
Plain English Explanation
Semantic segmentation is the task of assigning a label (e.g., "car", "person", "building") to every pixel in an image. Weakly supervised semantic segmentation is a more challenging version of this problem, where the training data only has image-level labels (e.g., "this image contains a car") rather than detailed pixel-level annotations.
One common approach to weakly supervised segmentation is to generate an "attention map" that highlights the regions of the image most relevant to the predicted class. However, these attention maps can often be noisy and include irrelevant background regions, which can degrade the performance of the segmentation model.
This paper presents a technique to reduce the background noise in attention maps, leveraging a pre-trained network to identify and suppress the irrelevant regions. By cleaning up the attention maps, the segmentation model can focus on the most important parts of the image, leading to improved performance.
The authors evaluate their method on several popular benchmark datasets and show that it outperforms existing weakly supervised semantic segmentation techniques. This work represents an important step forward in making weakly supervised segmentation more robust and practical for real-world applications.
Technical Explanation
The key innovation in this paper is a background noise reduction (BNR) module that is used to refine the attention maps generated by the weakly supervised segmentation model. The BNR module takes the attention map as input and outputs a "cleaned" version of the map, with the background regions suppressed.
The BNR module consists of two main components:
- Background Attention Map Estimator: This sub-module uses a pre-trained network (e.g., CAM-based methods) to generate a map that highlights the background regions of the image.
- Background Noise Suppression: The background attention map is then used to selectively suppress the irrelevant regions in the original attention map, resulting in a cleaner focus on the foreground objects of interest.
The authors experiment with different ways of combining the background attention map with the original attention map, including element-wise multiplication and learnable fusion modules. They find that the learnable fusion approach performs best, allowing the model to adaptively balance the contribution of the background suppression.
The BNR module is integrated into a weakly supervised segmentation pipeline, where it is used to refine the attention maps before feeding them into the final segmentation head. The authors evaluate their approach on several benchmark datasets, including PASCAL VOC and MS-COCO, and demonstrate significant improvements over state-of-the-art weakly supervised segmentation methods.
Critical Analysis
The proposed BNR module is a clever and well-designed technique to address a key challenge in weakly supervised semantic segmentation. By leveraging a pre-trained network to identify and suppress background regions in the attention maps, the authors are able to significantly improve the performance of their weakly supervised model.
One potential limitation of the approach is its reliance on a pre-trained network for the background attention map estimation. While the authors show that this network can be trained in a self-supervised manner, it would be interesting to explore ways of jointly learning the background attention map as part of the overall weakly supervised segmentation pipeline, potentially further improving the performance and robustness of the approach.
Additionally, the authors primarily evaluate their method on traditional semantic segmentation benchmarks, which may not fully capture the real-world challenges of weakly supervised segmentation. It would be valuable to see how the BNR module performs in more realistic, unconstrained scenarios, such as semi-supervised active learning for video action detection or sound event localization and classification in outdoor environments.
Overall, this paper presents a compelling and well-executed approach to a critical problem in weakly supervised semantic segmentation. The authors' focus on reducing background noise in attention maps is a valuable contribution to the field, and the promising results suggest that this line of research is worth further exploration.
Conclusion
This paper introduces a novel background noise reduction (BNR) module that can be integrated into weakly supervised semantic segmentation pipelines to improve their performance. By leveraging a pre-trained network to identify and suppress irrelevant background regions in the attention maps, the BNR module helps the segmentation model focus on the most important parts of the image.
The authors demonstrate the effectiveness of their approach on several benchmark datasets, where it outperforms existing weakly supervised segmentation techniques. This work represents an important step forward in making weakly supervised semantic segmentation more robust and practical for real-world applications, potentially paving the way for more efficient and versatile computer vision systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
Reduction of Class Activation Uncertainty with Background Information
H M Dipu Kabir
0
0
Multitask learning is a popular approach to training high-performing neural networks with improved generalization. In this paper, we propose a background class to achieve improved generalization at a lower computation compared to multitask learning to help researchers and organizations with limited computation power. We also present a methodology for selecting background images and discuss potential future improvements. We apply our approach to several datasets and achieve improved generalization with much lower computation. Through the class activation mappings (CAMs) of the trained models, we observed the tendency towards looking at a bigger picture with the proposed model training methodology. Applying the vision transformer with the proposed background class, we receive state-of-the-art (SOTA) performance on STL-10, Caltech-101, and CINIC-10 datasets. Example scripts are available in the 'CAM' folder of the following GitHub Repository: github.com/dipuk0506/UQ
4/9/2024
Fine-grained Background Representation for Weakly Supervised Semantic Segmentation
Xu Yin, Woobin Im, Dongbo Min, Yuchi Huo, Fei Pan, Sung-Eui Yoon
0
0
Generating reliable pseudo masks from image-level labels is challenging in the weakly supervised semantic segmentation (WSSS) task due to the lack of spatial information. Prevalent class activation map (CAM)-based solutions are challenged to discriminate the foreground (FG) objects from the suspicious background (BG) pixels (a.k.a. co-occurring) and learn the integral object regions. This paper proposes a simple fine-grained background representation (FBR) method to discover and represent diverse BG semantics and address the co-occurring problems. We abandon using the class prototype or pixel-level features for BG representation. Instead, we develop a novel primitive, negative region of interest (NROI), to capture the fine-grained BG semantic information and conduct the pixel-to-NROI contrast to distinguish the confusing BG pixels. We also present an active sampling strategy to mine the FG negatives on-the-fly, enabling efficient pixel-to-pixel intra-foreground contrastive learning to activate the entire object region. Thanks to the simplicity of design and convenience in use, our proposed method can be seamlessly plugged into various models, yielding new state-of-the-art results under various WSSS settings across benchmarks. Leveraging solely image-level (I) labels as supervision, our method achieves 73.2 mIoU and 45.6 mIoU segmentation results on Pascal Voc and MS COCO test sets, respectively. Furthermore, by incorporating saliency maps as an additional supervision signal (I+S), we attain 74.9 mIoU on Pascal Voc test set. Concurrently, our FBR approach demonstrates meaningful performance gains in weakly-supervised instance segmentation (WSIS) tasks, showcasing its robustness and strong generalization capabilities across diverse domains.
6/26/2024
👨🏫
Learning to Detour: Shortcut Mitigating Augmentation for Weakly Supervised Semantic Segmentation
JuneHyoung Kwon, Eunju Lee, Yunsung Cho, YoungBin Kim
0
0
Weakly supervised semantic segmentation (WSSS) employing weak forms of labels has been actively studied to alleviate the annotation cost of acquiring pixel-level labels. However, classifiers trained on biased datasets tend to exploit shortcut features and make predictions based on spurious correlations between certain backgrounds and objects, leading to a poor generalization performance. In this paper, we propose shortcut mitigating augmentation (SMA) for WSSS, which generates synthetic representations of object-background combinations not seen in the training data to reduce the use of shortcut features. Our approach disentangles the object-relevant and background features. We then shuffle and combine the disentangled representations to create synthetic features of diverse object-background combinations. SMA-trained classifier depends less on contexts and focuses more on the target object when making predictions. In addition, we analyzed the behavior of the classifier on shortcut usage after applying our augmentation using an attribution method-based metric. The proposed method achieved the improved performance of semantic segmentation result on PASCAL VOC 2012 and MS COCO 2014 datasets.
5/29/2024
👨🏫
Enhancing Weakly Supervised Semantic Segmentation with Multi-modal Foundation Models: An End-to-End Approach
Elham Ravanbakhsh, Cheng Niu, Yongqing Liang, J. Ramanujam, Xin Li
0
0
Semantic segmentation is a core computer vision problem, but the high costs of data annotation have hindered its wide application. Weakly-Supervised Semantic Segmentation (WSSS) offers a cost-efficient workaround to extensive labeling in comparison to fully-supervised methods by using partial or incomplete labels. Existing WSSS methods have difficulties in learning the boundaries of objects leading to poor segmentation results. We propose a novel and effective framework that addresses these issues by leveraging visual foundation models inside the bounding box. Adopting a two-stage WSSS framework, our proposed network consists of a pseudo-label generation module and a segmentation module. The first stage leverages Segment Anything Model (SAM) to generate high-quality pseudo-labels. To alleviate the problem of delineating precise boundaries, we adopt SAM inside the bounding box with the help of another pre-trained foundation model (e.g., Grounding-DINO). Furthermore, we eliminate the necessity of using the supervision of image labels, by employing CLIP in classification. Then in the second stage, the generated high-quality pseudo-labels are used to train an off-the-shelf segmenter that achieves the state-of-the-art performance on PASCAL VOC 2012 and MS COCO 2014.
5/13/2024