Sound event localization and classification using WASN in Outdoor Environment
2403.20130
0
0

Abstract
Deep learning-based sound event localization and classification is an emerging research area within wireless acoustic sensor networks. However, current methods for sound event localization and classification typically rely on a single microphone array, making them susceptible to signal attenuation and environmental noise, which limits their monitoring range. Moreover, methods using multiple microphone arrays often focus solely on source localization, neglecting the aspect of sound event classification. In this paper, we propose a deep learning-based method that employs multiple features and attention mechanisms to estimate the location and class of sound source. We introduce a Soundmap feature to capture spatial information across multiple frequency bands. We also use the Gammatone filter to generate acoustic features more suitable for outdoor environments. Furthermore, we integrate attention mechanisms to learn channel-wise relationships and temporal dependencies within the acoustic features. To evaluate our proposed method, we conduct experiments using simulated datasets with different levels of noise and size of monitoring areas, as well as different arrays and source positions. The experimental results demonstrate the superiority of our proposed method over state-of-the-art methods in both sound event classification and sound source localization tasks. And we provide further analysis to explain the reasons for the observed errors.
Create account to get full access
Introduction
This paper presents a novel deep learning-based method for sound event localization and classification (SELC) using wireless acoustic sensor networks (WASN) in outdoor environments. The key aspects are:
-
WASN are used for signal acquisition and processing, with multiple microphone arrays to enable comprehensive monitoring of large outdoor areas.
-
A Soundmap feature is proposed, which leverages the geometric information of the array to enhance spatial gain and suppress noise interference, enabling effective extraction of spatial information in low signal-to-noise environments.
-
Gammatonegram is used to represent the sound signals, as it aligns better with human auditory characteristics and is more effective in outdoor settings.
-
A multitask model based on convolutional neural networks and Transformer encoder modules is introduced, which integrates sound event classification and sound source localization tasks.
-
The proposed method is evaluated in diverse acoustic environments and shows superior performance compared to state-of-the-art deep learning-based approaches.
PROPOSED METHOD
The text describes a system for simultaneous sound source localization (SSL) and sound event classification (SEC) using a wireless acoustic sensor network (WASN). The key components are:
Soundmap Features: The system uses broadband beamforming to obtain spatial-energy information across the frequency spectrum, creating a "Soundmap" feature that captures the frequency-domain distribution of the target sound signal.
Gammatonegram (GTGram) Features: To handle acoustic environments with noise and interference, the system uses Gammatone filterbanks to generate perceptually-relevant GTGram features.
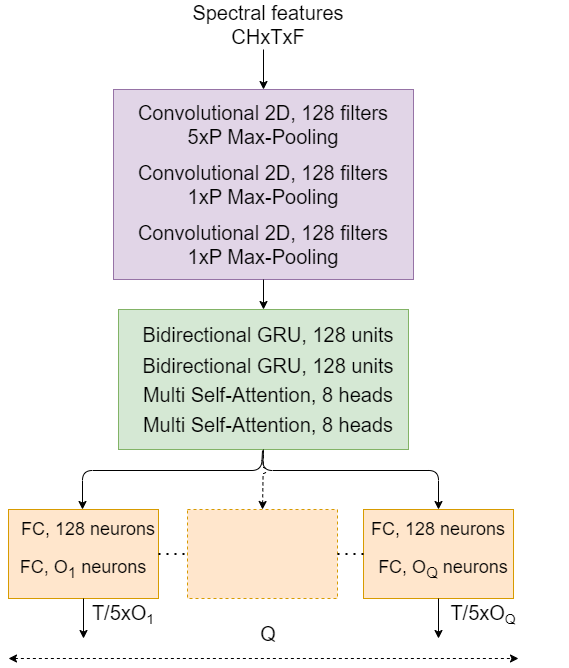
Neural Network Architecture: The system uses a deep neural network with convolutional and transformer encoder layers to learn the mapping between the Soundmap, GTGram, and array position features to the sound source location and classification.
The paper elaborates on the mathematical formulations for the Soundmap and GTGram feature extraction, as well as the details of the neural network modules. The final model outputs the estimated sound source coordinates for SSL and the sound event categories for SEC.
The loss function combines mean squared error for SSL and binary cross-entropy for SEC, with a weighting parameter to balance the two objectives.
EVALUATION
This section introduces simulated multi-array and multi-channel datasets, as well as evaluation metrics for the proposed method and baseline methods.
The authors use the Pyroomacoustic package to simulate sound signal propagation. The experimental setup includes 8-element circular microphone arrays with a radius of 11 cm and a sampling frequency of 8000 Hz. Three types of sound events are considered: emergency siren, human scream, and gunshot, along with a noise category. The simulated data covers five different area sizes, with various sound pressure levels (SPLs) and signal-to-noise ratios (SNRs) for the target and interfering sources.
For the sound event classification (SEC) task, the authors use precision, recall, F1 score, and false alarm rate (FAR) as evaluation metrics. For the sound source localization (SSL) task, they use root mean square error (RMSE) as the metric. Additionally, a comprehensive metric called the SELC score is designed, which combines the F1 score, 1-FAR, and 1-RMSE/area length.
The authors also provide implementation details for the Soundmap and GTGram features, as well as the array position feature. Finally, they introduce several baseline methods for comparison, including SEC-CNN, SEC-SEC, SSL-PLSE, SSL-FUZZY, and SSL-STFT.
V RESULTS AND DISCUSSION
The paper evaluates the baseline methods and the proposed method from various perspectives. The key findings are:
SEC performance: The proposed method outperforms two baseline methods in sound event classification (SEC), achieving higher F1 scores and lower false alarm rates across different sound classes.
SSL performance: The proposed method also outperforms three baseline methods in sound source localization (SSL), with an average localization error of 7.5 meters, significantly lower than the other methods.
Ablation study: Removing the SEC branch from the proposed network decreases localization accuracy, indicating SEC improves SSL performance.
Comparison of SELC: The proposed method achieves the highest combined score for sound event localization and classification, outperforming two baseline methods that use a cascaded or multitask approach.
Real-world experiment: In a real-world urban park setting, the proposed method maintains superior performance in both SEC and SSL tasks compared to the baselines, demonstrating its practicality.
CONCLUSION
This paper presents a deep learning-based method for sound event localization and classification using a wireless acoustic sensor network (WASN). The approach uses multiple microphone arrays, each with multiple sensors, to sample and process acoustic signals.
The key innovations include a novel feature called Soundmap that represents spatial information across multiple frequency bands, and a network architecture that employs attention mechanisms to learn channel-wise relationships and temporal dependencies in the acoustic features.
Experimental results show the proposed method outperforms baseline approaches. It achieves the highest F1 score and lowest false alarm rate for the sound event classification task, as well as the lowest root-mean-square error for the sound source localization task. Further experiments confirm the mutual benefits of jointly learning these two tasks.
Visualization of localization errors demonstrates the robust sound source localization performance of the proposed method in complex environments. The efficiency of the approach is also validated through real-world experiments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Text-Queried Target Sound Event Localization
Jinzheng Zhao, Xinyuan Qian, Yong Xu, Haohe Liu, Yin Cao, Davide Berghi, Wenwu Wang
0
0
Sound event localization and detection (SELD) aims to determine the appearance of sound classes, together with their Direction of Arrival (DOA). However, current SELD systems can only predict the activities of specific classes, for example, 13 classes in DCASE challenges. In this paper, we propose text-queried target sound event localization (SEL), a new paradigm that allows the user to input the text to describe the sound event, and the SEL model can predict the location of the related sound event. The proposed task presents a more user-friendly way for human-computer interaction. We provide a benchmark study for the proposed task and perform experiments on datasets created by simulated room impulse response (RIR) and real RIR to validate the effectiveness of the proposed methods. We hope that our benchmark will inspire the interest and additional research for text-queried sound source localization.
6/25/2024
Sound Event Detection and Localization with Distance Estimation
Daniel Aleksander Krause, Archontis Politis, Annamaria Mesaros
0
0
Sound Event Detection and Localization (SELD) is a combined task of identifying sound events and their corresponding direction-of-arrival (DOA). While this task has numerous applications and has been extensively researched in recent years, it fails to provide full information about the sound source position. In this paper, we overcome this problem by extending the task to Sound Event Detection, Localization with Distance Estimation (3D SELD). We study two ways of integrating distance estimation within the SELD core - a multi-task approach, in which the problem is tackled by a separate model output, and a single-task approach obtained by extending the multi-ACCDOA method to include distance information. We investigate both methods for the Ambisonic and binaural versions of STARSS23: Sony-TAU Realistic Spatial Soundscapes 2023. Moreover, our study involves experiments on the loss function related to the distance estimation part. Our results show that it is possible to perform 3D SELD without any degradation of performance in sound event detection and DOA estimation.
6/13/2024
↗️
Audio Simulation for Sound Source Localization in Virtual Evironment
Yi Di Yuan, Swee Liang Wong, Jonathan Pan
0
0
Non-line-of-sight localization in signal-deprived environments is a challenging yet pertinent problem. Acoustic methods in such predominantly indoor scenarios encounter difficulty due to the reverberant nature. In this study, we aim to locate sound sources to specific locations within a virtual environment by leveraging physically grounded sound propagation simulations and machine learning methods. This process attempts to overcome the issue of data insufficiency to localize sound sources to their location of occurrence especially in post-event localization. We achieve 0.786+/- 0.0136 F1-score using an audio transformer spectrogram approach.
4/3/2024
🛠️
SemiPL: A Semi-supervised Method for Event Sound Source Localization
Yue Li, Baiqiao Yin, Jinfu Liu, Jiajun Wen, Jiaying Lin, Mengyuan Liu
0
0
In recent years, Event Sound Source Localization has been widely applied in various fields. Recent works typically relying on the contrastive learning framework show impressive performance. However, all work is based on large relatively simple datasets. It's also crucial to understand and analyze human behaviors (actions and interactions of people), voices, and sounds in chaotic events in many applications, e.g., crowd management, and emergency response services. In this paper, we apply the existing model to a more complex dataset, explore the influence of parameters on the model, and propose a semi-supervised improvement method SemiPL. With the increase in data quantity and the influence of label quality, self-supervised learning will be an unstoppable trend. The experiment shows that the parameter adjustment will positively affect the existing model. In particular, SSPL achieved an improvement of 12.2% cIoU and 0.56% AUC in Chaotic World compared to the results provided. The code is available at: https://github.com/ly245422/SSPL
5/1/2024