BaFTA: Backprop-Free Test-Time Adaptation For Zero-Shot Vision-Language Models
2406.11309
0
0

Abstract
Large-scale pretrained vision-language models like CLIP have demonstrated remarkable zero-shot image classification capabilities across diverse domains. To enhance CLIP's performance while preserving the zero-shot paradigm, various test-time prompt tuning methods have been introduced to refine class embeddings through unsupervised learning objectives during inference. However, these methods often encounter challenges in selecting appropriate learning rates to prevent collapsed training in the absence of validation data during test-time adaptation. In this study, we propose a novel backpropagation-free algorithm BaFTA for test-time adaptation of vision-language models. Instead of fine-tuning text prompts to refine class embeddings, our approach directly estimates class centroids using online clustering within a projected embedding space that aligns text and visual embeddings. We dynamically aggregate predictions from both estimated and original class embeddings, as well as from distinct augmented views, by assessing the reliability of each prediction using R'enyi Entropy. Through extensive experiments, we demonstrate that BaFTA consistently outperforms state-of-the-art test-time adaptation methods in both effectiveness and efficiency.
Create account to get full access
Overview
- This paper presents a new approach called BaFTA (Backprop-Free Test-Time Adaptation) that allows zero-shot vision-language models to be adapted to new tasks without requiring any gradient-based fine-tuning.
- BaFTA leverages the generative capabilities of the model to generate task-specific prompts that can be used to adapt the model's outputs to new tasks, without modifying the model parameters.
- The authors demonstrate that BaFTA can achieve competitive performance on a range of vision-language tasks, compared to fine-tuning-based approaches, while being significantly more efficient in terms of computational cost and memory requirements.
Plain English Explanation
Zero-shot vision-language models are powerful AI systems that can understand and generate text based on visual inputs, without being explicitly trained on those specific tasks. However, applying these models to new tasks can be challenging, as it often requires time-consuming fine-tuning of the model parameters using gradient-based optimization techniques.
The researchers behind BaFTA: Backprop-Free Test-Time Adaptation For Zero-Shot Vision-Language Models have developed a new approach that allows these models to be adapted to new tasks without any fine-tuning. Instead, BaFTA leverages the model's own generative capabilities to create task-specific prompts that can be used to guide the model's outputs, effectively adapting it to the new task.
This is a clever insight, as it means that the model's parameters don't need to be updated, saving a significant amount of computational resources and memory. The authors show that BaFTA can match the performance of fine-tuning-based approaches on a range of vision-language tasks, while being much more efficient to use.
Technical Explanation
The key idea behind BaFTA is to leverage the generative capabilities of zero-shot vision-language models to create task-specific prompts that can be used to adapt the model's outputs to new tasks, without modifying the model parameters.
The authors start by training a generative model to produce task-specific prompts based on the task description and any other relevant information (e.g., the input image). This prompt generation model is trained using a combination of supervised and unsupervised learning techniques.
At test time, the BaFTA system takes the input image and the task description, and uses the prompt generation model to produce a task-specific prompt. This prompt is then concatenated with the input image and fed into the zero-shot vision-language model, which generates the final output.
The key advantage of BaFTA is that it does not require any gradient-based fine-tuning of the zero-shot model's parameters, which can be computationally expensive and memory-intensive. Instead, the model adaptation is achieved solely through the task-specific prompts, making the approach much more efficient.
The authors evaluate BaFTA on a range of vision-language tasks, including image captioning, visual question answering, and visual reasoning. They show that BaFTA can achieve competitive performance compared to fine-tuning-based approaches, while being significantly more efficient in terms of computational cost and memory requirements.
Critical Analysis
The BaFTA approach is a clever and promising solution to the challenge of adapting zero-shot vision-language models to new tasks. By leveraging the generative capabilities of the model, the authors have found a way to achieve task adaptation without the need for expensive fine-tuning.
However, the paper does not address some potential limitations of the approach. For example, the prompt generation model itself may require significant training data and computational resources, which could limit the practical applicability of BaFTA in certain scenarios.
Additionally, the authors do not explore the generalization capabilities of the BaFTA approach beyond the specific tasks and datasets included in their evaluation. It would be interesting to see how well the system performs on more diverse or out-of-distribution tasks, which could provide important insights into the robustness and versatility of the approach.
Another area for further research could be the integration of BaFTA with other test-time adaptation techniques, such as those described in the Frustratingly Easy Test-Time Adaptation for Vision-Language Models, Lost Opportunity in Vision-Language Models: A Comparative Study, and Test-Time Zero-Shot Generalization in Vision-Language Models papers. Combining different adaptation approaches could potentially lead to even more powerful and flexible vision-language systems.
Conclusion
The BaFTA approach presented in this paper is a significant contribution to the field of zero-shot vision-language models. By enabling efficient test-time adaptation without the need for costly fine-tuning, BaFTA has the potential to make these powerful AI systems more accessible and practical for a wider range of applications.
The authors have demonstrated the effectiveness of their approach on a variety of tasks, and the promising results suggest that BaFTA could be a game-changer in the world of vision-language AI. As the field continues to evolve, techniques like CLIPARTT: Lightweight Adaptation of CLIP to New Tasks and Test-Time Model Adaptation with Only Forward Passes will likely play an important role in unlocking the full potential of these transformative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
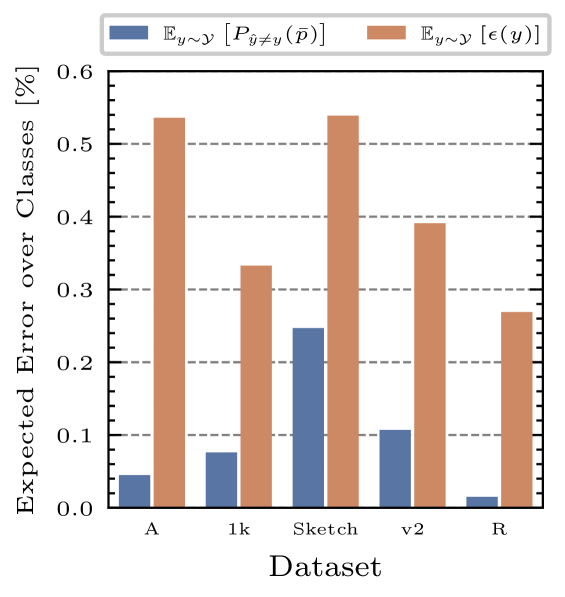
Frustratingly Easy Test-Time Adaptation of Vision-Language Models
Matteo Farina, Gianni Franchi, Giovanni Iacca, Massimiliano Mancini, Elisa Ricci
0
0
Vision-Language Models seamlessly discriminate among arbitrary semantic categories, yet they still suffer from poor generalization when presented with challenging examples. For this reason, Episodic Test-Time Adaptation (TTA) strategies have recently emerged as powerful techniques to adapt VLMs in the presence of a single unlabeled image. The recent literature on TTA is dominated by the paradigm of prompt tuning by Marginal Entropy Minimization, which, relying on online backpropagation, inevitably slows down inference while increasing memory. In this work, we theoretically investigate the properties of this approach and unveil that a surprisingly strong TTA method lies dormant and hidden within it. We term this approach ZERO (TTA with zero temperature), whose design is both incredibly effective and frustratingly simple: augment N times, predict, retain the most confident predictions, and marginalize after setting the Softmax temperature to zero. Remarkably, ZERO requires a single batched forward pass through the vision encoder only and no backward passes. We thoroughly evaluate our approach following the experimental protocol established in the literature and show that ZERO largely surpasses or compares favorably w.r.t. the state-of-the-art while being almost 10x faster and 13x more memory-friendly than standard Test-Time Prompt Tuning. Thanks to its simplicity and comparatively negligible computation, ZERO can serve as a strong baseline for future work in this field. The code is available at https://github.com/FarinaMatteo/zero.
5/29/2024

A Lost Opportunity for Vision-Language Models: A Comparative Study of Online Test-time Adaptation for Vision-Language Models
Mario Dobler, Robert A. Marsden, Tobias Raichle, Bin Yang
0
0
In the realm of deep learning, maintaining model robustness against distribution shifts is critical. This paper investigates test-time adaptation strategies for vision-language models, with a specific focus on CLIP and its variants. Through a systematic exploration of prompt-based techniques and existing test-time adaptation methods, the study aims to enhance the adaptability and robustness of vision-language models in diverse real-world scenarios. The investigation includes an analysis of prompt engineering strategies, such as hand-crafted prompts, prompt ensembles, and prompt learning techniques. We introduce a vision-text-space ensemble that significantly boosts the average performance compared to a text-space-only ensemble. Additionally, our comparative study delves into leveraging existing test-time adaptation methods originally designed for image classification tasks. Experimental evaluations conducted across various datasets and model architectures demonstrate the efficacy of different adaptation strategies. We further give insights into the importance of updating the vision encoder and whether it is beneficial to update the text encoder. Code is available at https://github.com/mariodoebler/test-time-adaptation
5/27/2024
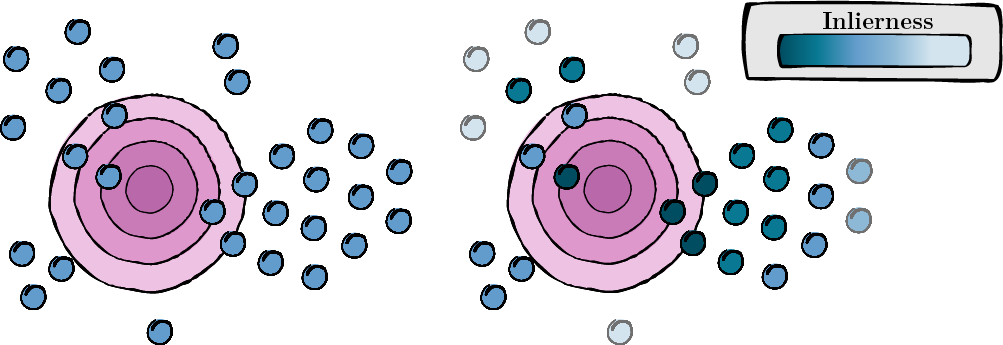
On the test-time zero-shot generalization of vision-language models: Do we really need prompt learning?
Maxime Zanella, Ismail Ben Ayed
0
0
The development of large vision-language models, notably CLIP, has catalyzed research into effective adaptation techniques, with a particular focus on soft prompt tuning. Conjointly, test-time augmentation, which utilizes multiple augmented views of a single image to enhance zero-shot generalization, is emerging as a significant area of interest. This has predominantly directed research efforts toward test-time prompt tuning. In contrast, we introduce a robust MeanShift for Test-time Augmentation (MTA), which surpasses prompt-based methods without requiring this intensive training procedure. This positions MTA as an ideal solution for both standalone and API-based applications. Additionally, our method does not rely on ad hoc rules (e.g., confidence threshold) used in some previous test-time augmentation techniques to filter the augmented views. Instead, MTA incorporates a quality assessment variable for each view directly into its optimization process, termed as the inlierness score. This score is jointly optimized with a density mode seeking process, leading to an efficient training- and hyperparameter-free approach. We extensively benchmark our method on 15 datasets and demonstrate MTA's superiority and computational efficiency. Deployed easily as plug-and-play module on top of zero-shot models and state-of-the-art few-shot methods, MTA shows systematic and consistent improvements.
5/6/2024
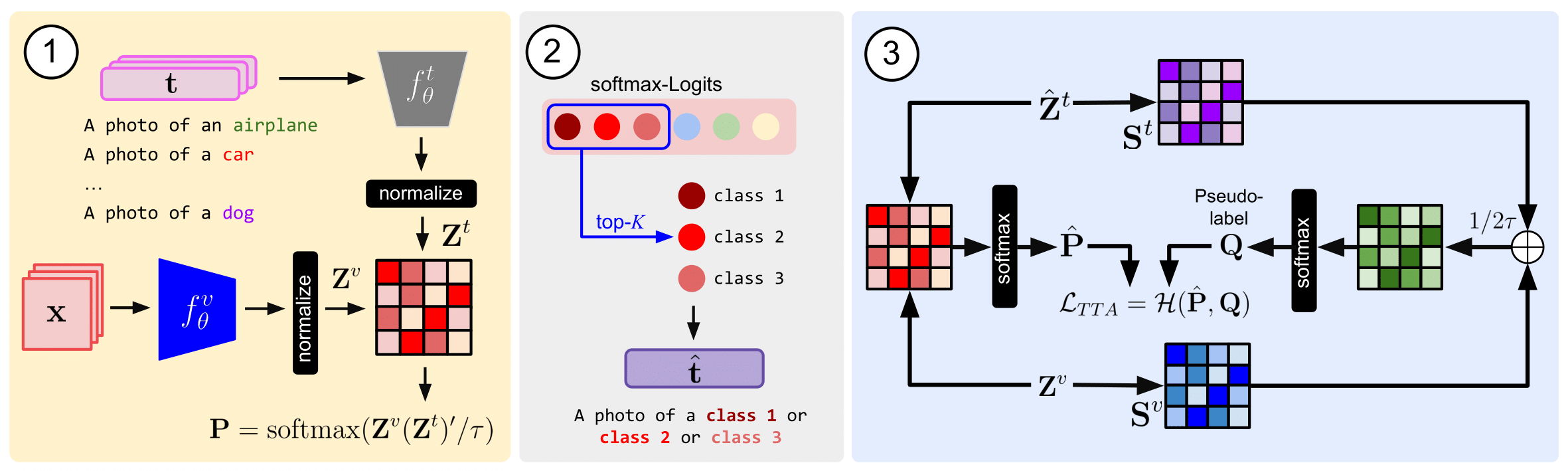
CLIPArTT: Light-weight Adaptation of CLIP to New Domains at Test Time
Gustavo Adolfo Vargas Hakim, David Osowiechi, Mehrdad Noori, Milad Cheraghalikhani, Ali Bahri, Moslem Yazdanpanah, Ismail Ben Ayed, Christian Desrosiers
0
0
Pre-trained vision-language models (VLMs), exemplified by CLIP, demonstrate remarkable adaptability across zero-shot classification tasks without additional training. However, their performance diminishes in the presence of domain shifts. In this study, we introduce CLIP Adaptation duRing Test-Time (CLIPArTT), a fully test-time adaptation (TTA) approach for CLIP, which involves automatic text prompts construction during inference for their use as text supervision. Our method employs a unique, minimally invasive text prompt tuning process, wherein multiple predicted classes are aggregated into a single new text prompt, used as pseudo label to re-classify inputs in a transductive manner. Additionally, we pioneer the standardization of TTA benchmarks (e.g., TENT) in the realm of VLMs. Our findings demonstrate that, without requiring additional transformations nor new trainable modules, CLIPArTT enhances performance dynamically across non-corrupted datasets such as CIFAR-10, corrupted datasets like CIFAR-10-C and CIFAR-10.1, alongside synthetic datasets such as VisDA-C. This research underscores the potential for improving VLMs' adaptability through novel test-time strategies, offering insights for robust performance across varied datasets and environments. The code can be found at: https://github.com/dosowiechi/CLIPArTT.git
5/3/2024