On the test-time zero-shot generalization of vision-language models: Do we really need prompt learning?

0
Sign in to get full access
Overview
- This research paper examines the ability of vision-language models to generalize to new tasks without requiring specialized prompt engineering.
- The authors investigate whether vision-language models like CLIP can achieve strong zero-shot performance on new tasks without the need for extensive prompt tuning.
- The paper compares the zero-shot performance of vision-language models with and without prompt learning, exploring the potential benefits and limitations of each approach.
Plain English Explanation
Vision-language models, such as CLIP, are powerful AI systems that can understand and process both visual and textual information. These models are trained on massive datasets of images and text, allowing them to learn rich representations that can be applied to a wide range of tasks.
One key challenge with these models is how to adapt them to new tasks or datasets that were not part of their original training. Traditionally, this has involved a process called "prompt learning," where the model is fine-tuned on a specific set of example prompts to enable it to perform well on a new task.
This research paper investigates whether prompt learning is truly necessary for vision-language models to achieve strong zero-shot performance on new tasks. The authors hypothesize that these models may already possess the inherent capability to generalize to new tasks without requiring extensive prompt tuning.
To test this hypothesis, the researchers compare the zero-shot performance of vision-language models with and without prompt learning. They find that in many cases, the models can achieve competitive or even superior performance on new tasks without the need for prompt engineering. This suggests that vision-language models may already possess a remarkable degree of inherent generalization ability, potentially reducing the need for complex prompt tuning in certain applications.
Technical Explanation
The core of this research paper is a series of experiments that examine the zero-shot generalization capabilities of vision-language models like CLIP and CLAP.
The authors first establish a set of benchmark tasks to evaluate the zero-shot performance of these models, including image classification, visual question answering, and visual reasoning. They then compare the performance of the models under two conditions:
- Zero-shot without prompts: The models are evaluated on the benchmark tasks without any prompt engineering or fine-tuning.
- Zero-shot with prompts: The models are fine-tuned on a set of example prompts for each task, and then evaluated on the benchmark tasks.
The results show that in many cases, the vision-language models can achieve strong zero-shot performance without the need for prompt learning. In some instances, the models even outperform their prompt-tuned counterparts, suggesting that the inherent generalization capabilities of these models may be more powerful than previously thought.
The authors also investigate the impact of various factors, such as dataset size, task difficulty, and model architecture, on the zero-shot performance of the vision-language models. They find that the models' generalization abilities are influenced by these factors, but that prompt learning is not always necessary to achieve high-quality results.
Critical Analysis
The research presented in this paper offers an important contribution to the understanding of vision-language models and their ability to generalize to new tasks. By demonstrating that prompt learning may not be a universal requirement for achieving strong zero-shot performance, the authors challenge the prevailing assumptions in the field and open up new avenues for exploration.
However, it is important to note that the paper also acknowledges several limitations and caveats to their findings. For example, the authors acknowledge that prompt learning may still be beneficial for certain tasks or datasets, particularly those that are more specialized or domain-specific. Additionally, the paper does not explore the potential trade-offs between prompt-based and prompt-free approaches in terms of factors like computational efficiency, training time, or robustness.
Furthermore, the paper raises questions about the underlying mechanisms that enable vision-language models to generalize without prompt learning. Understanding these mechanisms could lead to important insights about the nature of these models and how they can be further improved or adapted for a wider range of applications.
Conclusion
This research paper presents a compelling case for re-evaluating the role of prompt learning in the context of vision-language models. By demonstrating that these models can often achieve strong zero-shot performance without the need for extensive prompt engineering, the authors challenge the prevailing assumptions in the field and open up new avenues for exploration.
The findings of this study have the potential to influence the design and development of future vision-language models, as well as the strategies used to adapt these models to new tasks and datasets. As the field of AI continues to evolve, research like this will be essential for unlocking the full potential of these powerful technologies and ensuring that they can be deployed in a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On the test-time zero-shot generalization of vision-language models: Do we really need prompt learning?
Maxime Zanella, Ismail Ben Ayed
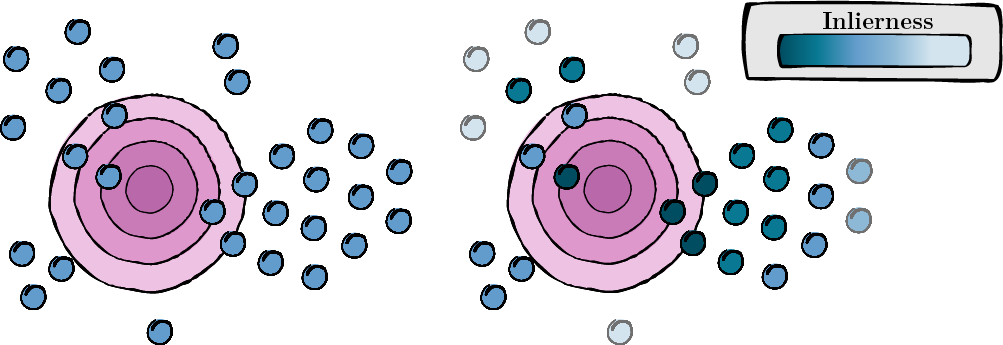
The development of large vision-language models, notably CLIP, has catalyzed research into effective adaptation techniques, with a particular focus on soft prompt tuning. Conjointly, test-time augmentation, which utilizes multiple augmented views of a single image to enhance zero-shot generalization, is emerging as a significant area of interest. This has predominantly directed research efforts toward test-time prompt tuning. In contrast, we introduce a robust MeanShift for Test-time Augmentation (MTA), which surpasses prompt-based methods without requiring this intensive training procedure. This positions MTA as an ideal solution for both standalone and API-based applications. Additionally, our method does not rely on ad hoc rules (e.g., confidence threshold) used in some previous test-time augmentation techniques to filter the augmented views. Instead, MTA incorporates a quality assessment variable for each view directly into its optimization process, termed as the inlierness score. This score is jointly optimized with a density mode seeking process, leading to an efficient training- and hyperparameter-free approach. We extensively benchmark our method on 15 datasets and demonstrate MTA's superiority and computational efficiency. Deployed easily as plug-and-play module on top of zero-shot models and state-of-the-art few-shot methods, MTA shows systematic and consistent improvements.
Read more5/6/2024
0
Frustratingly Easy Test-Time Adaptation of Vision-Language Models
Matteo Farina, Gianni Franchi, Giovanni Iacca, Massimiliano Mancini, Elisa Ricci
Vision-Language Models seamlessly discriminate among arbitrary semantic categories, yet they still suffer from poor generalization when presented with challenging examples. For this reason, Episodic Test-Time Adaptation (TTA) strategies have recently emerged as powerful techniques to adapt VLMs in the presence of a single unlabeled image. The recent literature on TTA is dominated by the paradigm of prompt tuning by Marginal Entropy Minimization, which, relying on online backpropagation, inevitably slows down inference while increasing memory. In this work, we theoretically investigate the properties of this approach and unveil that a surprisingly strong TTA method lies dormant and hidden within it. We term this approach ZERO (TTA with zero temperature), whose design is both incredibly effective and frustratingly simple: augment N times, predict, retain the most confident predictions, and marginalize after setting the Softmax temperature to zero. Remarkably, ZERO requires a single batched forward pass through the vision encoder only and no backward passes. We thoroughly evaluate our approach following the experimental protocol established in the literature and show that ZERO largely surpasses or compares favorably w.r.t. the state-of-the-art while being almost 10x faster and 13x more memory-friendly than standard Test-Time Prompt Tuning. Thanks to its simplicity and comparatively negligible computation, ZERO can serve as a strong baseline for future work in this field. The code is available at https://github.com/FarinaMatteo/zero.
Read more5/29/2024

0
Efficient Test-Time Prompt Tuning for Vision-Language Models
Yuhan Zhu, Guozhen Zhang, Chen Xu, Haocheng Shen, Xiaoxin Chen, Gangshan Wu, Limin Wang
Vision-language models have showcased impressive zero-shot classification capabilities when equipped with suitable text prompts. Previous studies have shown the effectiveness of test-time prompt tuning; however, these methods typically require per-image prompt adaptation during inference, which incurs high computational budgets and limits scalability and practical deployment. To overcome this issue, we introduce Self-TPT, a novel framework leveraging Self-supervised learning for efficient Test-time Prompt Tuning. The key aspect of Self-TPT is that it turns to efficient predefined class adaptation via self-supervised learning, thus avoiding computation-heavy per-image adaptation at inference. Self-TPT begins by co-training the self-supervised and the classification task using source data, then applies the self-supervised task exclusively for test-time new class adaptation. Specifically, we propose Contrastive Prompt Learning (CPT) as the key task for self-supervision. CPT is designed to minimize the intra-class distances while enhancing inter-class distinguishability via contrastive learning. Furthermore, empirical evidence suggests that CPT could closely mimic back-propagated gradients of the classification task, offering a plausible explanation for its effectiveness. Motivated by this finding, we further introduce a gradient matching loss to explicitly enhance the gradient similarity. We evaluated Self-TPT across three challenging zero-shot benchmarks. The results consistently demonstrate that Self-TPT not only significantly reduces inference costs but also achieves state-of-the-art performance, effectively balancing the efficiency-efficacy trade-off.
Read more8/13/2024
💬
0
Test-Time Low Rank Adaptation via Confidence Maximization for Zero-Shot Generalization of Vision-Language Models
Raza Imam, Hanan Gani, Muhammad Huzaifa, Karthik Nandakumar
The conventional modus operandi for adapting pre-trained vision-language models (VLMs) during test-time involves tuning learnable prompts, ie, test-time prompt tuning. This paper introduces Test-Time Low-rank adaptation (TTL) as an alternative to prompt tuning for zero-shot generalization of large-scale VLMs. Taking inspiration from recent advancements in efficiently fine-tuning large language models, TTL offers a test-time parameter-efficient adaptation approach that updates the attention weights of the transformer encoder by maximizing prediction confidence. The self-supervised confidence maximization objective is specified using a weighted entropy loss that enforces consistency among predictions of augmented samples. TTL introduces only a small amount of trainable parameters for low-rank adapters in the model space while keeping the prompts and backbone frozen. Extensive experiments on a variety of natural distribution and cross-domain tasks show that TTL can outperform other techniques for test-time optimization of VLMs in strict zero-shot settings. Specifically, TTL outperforms test-time prompt tuning baselines with a significant improvement on average. Our code is available at at https://github.com/Razaimam45/TTL-Test-Time-Low-Rank-Adaptation.
Read more7/24/2024