Balanced Data Placement for GEMV Acceleration with Processing-In-Memory
2403.20297
0
0

Abstract
With unprecedented demand for generative AI (GenAI) inference, acceleration of primitives that dominate GenAI such as general matrix-vector multiplication (GEMV) is receiving considerable attention. A challenge with GEMVs is the high memory bandwidth this primitive demands. Multiple memory vendors have proposed commercially viable processing-in-memory (PIM) prototypes that attain bandwidth boost over processor via augmenting memory banks with compute capabilities and broadcasting same command to all banks. While proposed PIM designs stand to accelerate GEMV, we observe in this work that a key impediment to truly harness PIM acceleration is deducing optimal data-placement to place the matrix in memory banks. To this end, we tease out several factors that impact data-placement and propose PIMnast methodology which, like a gymnast, balances these factors to identify data-placements that deliver GEMV acceleration. Across a spectrum of GenAI models, our proposed PIMnast methodology along with additional orchestration knobs we identify delivers up to 6.86$times$ speedup for GEMVs (of the available 7$times$ roofline speedup) leading to up to 5$times$ speedup for per-token latencies.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a technique called "Balanced Data Placement" to improve the performance of GEMV (General Matrix-Vector Multiplication) operations on Processing-in-Memory (PIM) architectures.
- PIM architectures integrate processing and memory on the same chip, allowing for faster data access and reduced data movement compared to traditional CPU-based systems.
- The authors focus on optimizing GEMV, a fundamental operation in many machine learning and scientific computing workloads, to take advantage of PIM capabilities.
Plain English Explanation
Imagine you have a large bookshelf in your house, and you need to find a specific book quickly. If the books are scattered all over the shelves, it will take you a long time to locate the one you need. However, if you organize the books by topic or author, you can find what you're looking for much faster.
Similarly, in computer systems, the way data is stored and accessed can have a big impact on performance. Traditional computer architectures often have a separate CPU and memory, which means the CPU has to spend a lot of time and energy fetching data from memory. This can be slow and inefficient.
Processing-in-Memory (PIM) architectures try to solve this problem by integrating the processing and memory on the same chip. This allows the system to access data much faster, since it doesn't have to move it over a slow connection between the CPU and memory.
The authors of this paper focused on a specific type of calculation called GEMV, which is used a lot in machine learning and scientific computing. They developed a technique called "Balanced Data Placement" to optimize how the data is stored and accessed on a PIM system, in order to get the best possible performance for GEMV operations.
Technical Explanation
The key ideas in this paper are:
- GEMV Acceleration on PIM: The authors identify GEMV as a crucial operation that can benefit from PIM architectures, as it involves a lot of data movement between the CPU and memory in traditional systems.
- Balanced Data Placement: The authors propose a data placement strategy that balances the data distribution across the PIM processing elements (PEs) to maximize parallelism and minimize data movement.
- Optimization Formulation and Algorithm: The authors formulate the data placement problem as an optimization problem and develop an efficient algorithm to solve it.
- Experimental Evaluation: The authors evaluate their approach on a simulated PIM system and show significant performance improvements compared to existing techniques.
The paper provides a detailed mathematical formulation of the optimization problem and the solution algorithm. It also includes a thorough experimental evaluation using realistic workloads and PIM system models.
Critical Analysis
The paper provides a well-designed and comprehensive solution to the problem of optimizing GEMV performance on PIM architectures. The authors have clearly identified a key challenge and developed a principled approach to address it.
One potential limitation is that the proposed technique may not generalize as well to other types of workloads beyond GEMV. The authors acknowledge this and suggest exploring extensions to other linear algebra operations as future work.
Additionally, the paper does not delve into the practical implementation challenges of realizing the proposed PIM architecture and data placement strategy. Factors such as memory technology, on-chip interconnects, and system-level integration would need to be considered for a real-world deployment.
Overall, this paper makes a valuable contribution to the field of PIM and demonstrates the potential benefits of carefully optimizing data placement to take advantage of the unique capabilities of these emerging architectures.
Conclusion
This paper presents an effective technique called "Balanced Data Placement" to accelerate GEMV operations on Processing-in-Memory (PIM) architectures. By carefully optimizing how data is distributed across the PIM processing elements, the authors are able to significantly improve the performance of this crucial linear algebra operation, which is widely used in machine learning and scientific computing.
The research highlights the importance of co-designing algorithms and hardware to fully leverage the capabilities of emerging PIM technologies. The authors' work serves as a valuable example of how innovative data placement strategies can unlock the potential of PIM systems and pave the way for more efficient, high-performance computing platforms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Mapping Parallel Matrix Multiplication in GotoBLAS2 to the AMD Versal ACAP for Deep Learning
Jie Lei, Enrique S. Quintana-Ort'i
0
0
This paper investigates the design of parallel general matrix multiplication (GEMM) for a Versal Adaptive Compute Accelerated Platform (ACAP) equipped with a VC1902 system-on-chip and multiple Artificial Intelligence Engines (AIEs). Our efforts aim to port standard optimization techniques applied in the high-performance realization of GEMM on CPUs to the Versal ACAP. In particular, 1) we address the flexible exploitation of the Versal ACA multi-level memory hierarchy; 2) we delve into the efficient use of the vector units in the AIE tiles, proposing an architecture-specific micro-kernel for mixed precision arithmetic to address the strong demand for adaptive-precision inference in deep learning; and 3) we introduce a parallel design for GEMM that spans multiple AIE tiles, enhancing the computational throughput. We conduct experimental profiling, with up to 32 AI Engines, that demonstrates the high parallel scalability of the solution.
4/24/2024
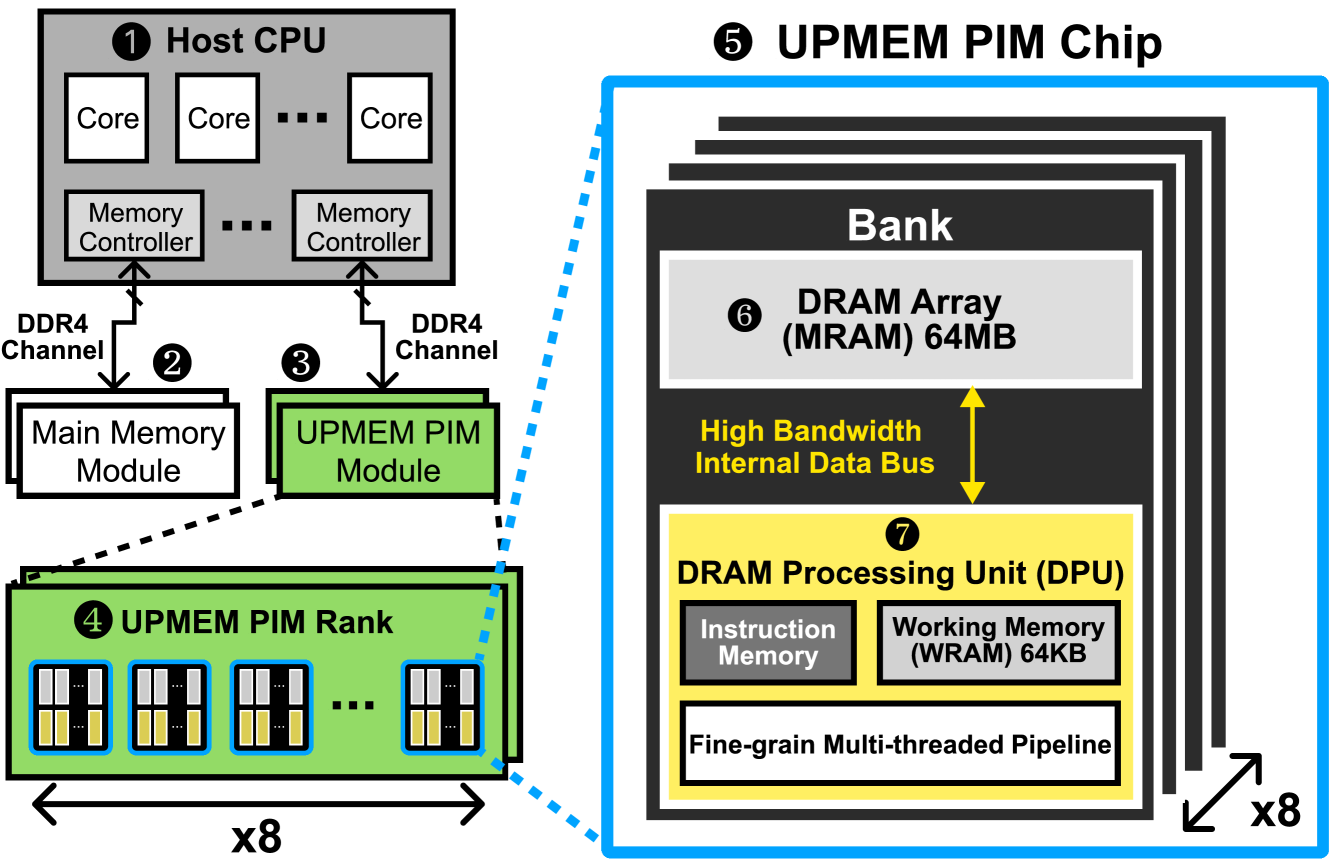
Analysis of Distributed Optimization Algorithms on a Real Processing-In-Memory System
Steve Rhyner, Haocong Luo, Juan G'omez-Luna, Mohammad Sadrosadati, Jiawei Jiang, Ataberk Olgun, Harshita Gupta, Ce Zhang, Onur Mutlu
0
0
Machine Learning (ML) training on large-scale datasets is a very expensive and time-consuming workload. Processor-centric architectures (e.g., CPU, GPU) commonly used for modern ML training workloads are limited by the data movement bottleneck, i.e., due to repeatedly accessing the training dataset. As a result, processor-centric systems suffer from performance degradation and high energy consumption. Processing-In-Memory (PIM) is a promising solution to alleviate the data movement bottleneck by placing the computation mechanisms inside or near memory. Our goal is to understand the capabilities and characteristics of popular distributed optimization algorithms on real-world PIM architectures to accelerate data-intensive ML training workloads. To this end, we 1) implement several representative centralized distributed optimization algorithms on UPMEM's real-world general-purpose PIM system, 2) rigorously evaluate these algorithms for ML training on large-scale datasets in terms of performance, accuracy, and scalability, 3) compare to conventional CPU and GPU baselines, and 4) discuss implications for future PIM hardware and the need to shift to an algorithm-hardware codesign perspective to accommodate decentralized distributed optimization algorithms. Our results demonstrate three major findings: 1) Modern general-purpose PIM architectures can be a viable alternative to state-of-the-art CPUs and GPUs for many memory-bound ML training workloads, when operations and datatypes are natively supported by PIM hardware, 2) the importance of carefully choosing the optimization algorithm that best fit PIM, and 3) contrary to popular belief, contemporary PIM architectures do not scale approximately linearly with the number of nodes for many data-intensive ML training workloads. To facilitate future research, we aim to open-source our complete codebase.
4/11/2024
✅
NeuPIMs: NPU-PIM Heterogeneous Acceleration for Batched LLM Inferencing
Guseul Heo, Sangyeop Lee, Jaehong Cho, Hyunmin Choi, Sanghyeon Lee, Hyungkyu Ham, Gwangsun Kim, Divya Mahajan, Jongse Park
0
0
Modern transformer-based Large Language Models (LLMs) are constructed with a series of decoder blocks. Each block comprises three key components: (1) QKV generation, (2) multi-head attention, and (3) feed-forward networks. In batched processing, QKV generation and feed-forward networks involve compute-intensive matrix-matrix multiplications (GEMM), while multi-head attention requires bandwidth-heavy matrix-vector multiplications (GEMV). Machine learning accelerators like TPUs or NPUs are proficient in handling GEMM but are less efficient for GEMV computations. Conversely, Processing-in-Memory (PIM) technology is tailored for efficient GEMV computation, while it lacks the computational power to handle GEMM effectively. Inspired by this insight, we propose NeuPIMs, a heterogeneous acceleration system that jointly exploits a conventional GEMM-focused NPU and GEMV-optimized PIM devices. The main challenge in efficiently integrating NPU and PIM lies in enabling concurrent operations on both platforms, each addressing a specific kernel type. First, existing PIMs typically operate in a blocked mode, allowing only either NPU or PIM to be active at any given time. Second, the inherent dependencies between GEMM and GEMV in LLMs restrict their parallel processing. To tackle these challenges, NeuPIMs is equipped with dual row buffers in each bank, facilitating the simultaneous management of memory read/write operations and PIM commands. Further, NeuPIMs employs a runtime sub-batch interleaving technique to maximize concurrent execution, leveraging batch parallelism to allow two independent sub-batches to be pipelined within a single NeuPIMs device. Our evaluation demonstrates that compared to GPU-only, NPU-only, and a naive NPU+PIM integrated acceleration approaches, NeuPIMs achieves 3$times$, 2.4$times$ and 1.6$times$ throughput improvement, respectively.
4/1/2024
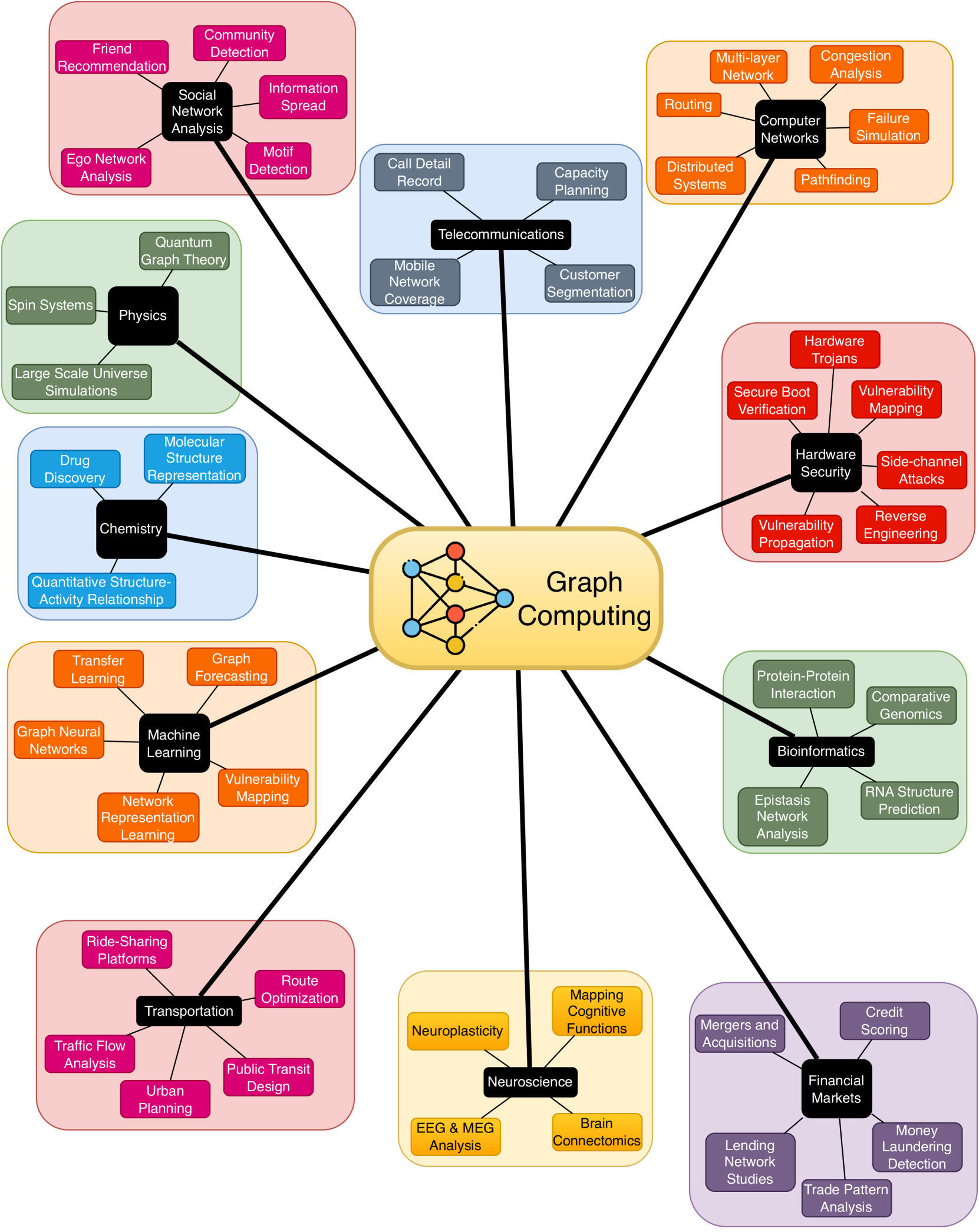
Enabling Accelerators for Graph Computing
Kaustubh Shivdikar
0
0
The advent of Graph Neural Networks (GNNs) has revolutionized the field of machine learning, offering a novel paradigm for learning on graph-structured data. Unlike traditional neural networks, GNNs are capable of capturing complex relationships and dependencies inherent in graph data, making them particularly suited for a wide range of applications including social network analysis, molecular chemistry, and network security. GNNs, with their unique structure and operation, present new computational challenges compared to conventional neural networks. This requires comprehensive benchmarking and a thorough characterization of GNNs to obtain insight into their computational requirements and to identify potential performance bottlenecks. In this thesis, we aim to develop a better understanding of how GNNs interact with the underlying hardware and will leverage this knowledge as we design specialized accelerators and develop new optimizations, leading to more efficient and faster GNN computations. A pivotal component within GNNs is the Sparse General Matrix-Matrix Multiplication (SpGEMM) kernel, known for its computational intensity and irregular memory access patterns. In this thesis, we address the challenges posed by SpGEMM by implementing a highly optimized hashing-based SpGEMM kernel tailored for a custom accelerator. Synthesizing these insights and optimizations, we design state-of-the-art hardware accelerators capable of efficiently handling various GNN workloads. Our accelerator architectures are built on our characterization of GNN computational demands, providing clear motivation for our approaches. This exploration into novel models underlines our comprehensive approach, as we strive to enable accelerators that are not just performant, but also versatile, able to adapt to the evolving landscape of graph computing.
5/7/2024