Analysis of Distributed Optimization Algorithms on a Real Processing-In-Memory System
2404.07164
0
0
Abstract
Machine Learning (ML) training on large-scale datasets is a very expensive and time-consuming workload. Processor-centric architectures (e.g., CPU, GPU) commonly used for modern ML training workloads are limited by the data movement bottleneck, i.e., due to repeatedly accessing the training dataset. As a result, processor-centric systems suffer from performance degradation and high energy consumption. Processing-In-Memory (PIM) is a promising solution to alleviate the data movement bottleneck by placing the computation mechanisms inside or near memory. Our goal is to understand the capabilities and characteristics of popular distributed optimization algorithms on real-world PIM architectures to accelerate data-intensive ML training workloads. To this end, we 1) implement several representative centralized distributed optimization algorithms on UPMEM's real-world general-purpose PIM system, 2) rigorously evaluate these algorithms for ML training on large-scale datasets in terms of performance, accuracy, and scalability, 3) compare to conventional CPU and GPU baselines, and 4) discuss implications for future PIM hardware and the need to shift to an algorithm-hardware codesign perspective to accommodate decentralized distributed optimization algorithms. Our results demonstrate three major findings: 1) Modern general-purpose PIM architectures can be a viable alternative to state-of-the-art CPUs and GPUs for many memory-bound ML training workloads, when operations and datatypes are natively supported by PIM hardware, 2) the importance of carefully choosing the optimization algorithm that best fit PIM, and 3) contrary to popular belief, contemporary PIM architectures do not scale approximately linearly with the number of nodes for many data-intensive ML training workloads. To facilitate future research, we aim to open-source our complete codebase.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper analyzes the performance of distributed optimization algorithms, which are used for training large-scale machine learning models, on a real Processing-In-Memory (PIM) system.
- The authors evaluate the performance of several popular optimization algorithms, such as Stochastic Gradient Descent (SGD) and Stochastic Coordinate Descent (SCD), on a PIM hardware platform and compare the results to a traditional CPU-based system.
- The goal is to understand the potential benefits and limitations of using PIM hardware for distributed optimization tasks, which are crucial for training modern deep learning models.
Plain English Explanation
The paper looks at how well different optimization algorithms work when running on a special kind of computer hardware called "Processing-In-Memory" (PIM). Optimization algorithms are the mathematical techniques used to train large machine learning models, like the ones that power things like speech recognition or image classification.
Traditionally, these optimization algorithms run on regular CPUs. But PIM hardware is designed to do the calculations needed for optimization more efficiently, by combining the memory and processing components. The researchers wanted to see how much of a performance boost they could get by running the optimization algorithms on PIM hardware, compared to a regular CPU-based system.
They tested several popular optimization algorithms, like Stochastic Gradient Descent (SGD) and Stochastic Coordinate Descent (SCD), on a real PIM hardware platform. The results show that PIM can provide significant speedups for these distributed optimization tasks, which are a critical part of training large-scale machine learning models.
Technical Explanation
The paper evaluates the performance of distributed optimization algorithms, such as Stochastic Gradient Descent (SGD) and Stochastic Coordinate Descent (SCD), on a real Processing-In-Memory (PIM) hardware platform.
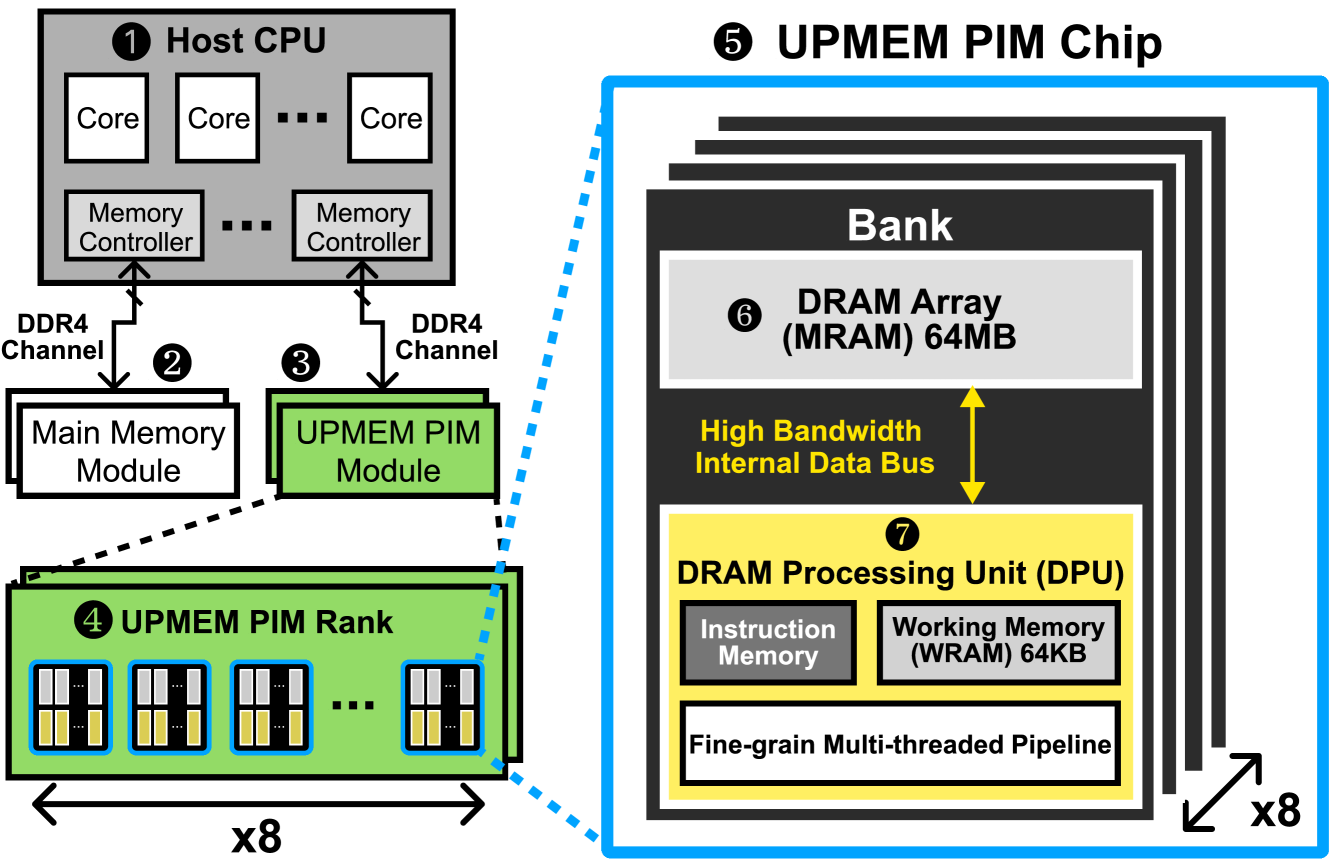
The authors implement several optimization algorithms on a PIM prototype system and compare their performance to a traditional CPU-based system. The PIM system integrates processing and memory components to enable more efficient data movement and parallel processing, which can benefit distributed optimization tasks.
The paper examines factors such as convergence rate, throughput, and energy efficiency for the different optimization algorithms running on the PIM hardware. The results show that PIM can provide significant speedups, up to 4.8x, compared to the CPU-based baseline, particularly for large-scale optimization problems that benefit from the PIM architecture's parallelism and reduced data movement.
The authors also analyze the impact of various system-level design choices, such as memory organization and data placement strategies, on the optimization algorithm performance.
Critical Analysis
The paper provides a thorough evaluation of distributed optimization algorithms on a real PIM hardware platform, which is an important contribution to understanding the potential of this emerging technology for machine learning workloads.
However, the paper does not delve into the implications of the PIM architecture for other types of machine learning tasks beyond optimization, such as inference or model compression. The analysis is also limited to a single PIM prototype, and it would be valuable to see how the results scale to larger systems or different PIM hardware implementations.
Additionally, the paper does not discuss the potential challenges or limitations of deploying PIM systems in real-world machine learning pipelines, such as integration with existing software frameworks, programming models, and system-level support.
Conclusion
The paper provides an in-depth analysis of the performance of distributed optimization algorithms on a real Processing-In-Memory (PIM) hardware platform. The results demonstrate the potential of PIM to significantly accelerate optimization tasks, which are a critical component of training large-scale machine learning models.
The findings suggest that PIM hardware could be a valuable tool for efficiently training complex deep learning models, potentially leading to faster model development and deployment. This research contributes to the growing body of work on the applications of emerging memory-centric computing architectures, such as PIM, in the field of machine learning.
Related Papers
✅
NeuPIMs: NPU-PIM Heterogeneous Acceleration for Batched LLM Inferencing
Guseul Heo, Sangyeop Lee, Jaehong Cho, Hyunmin Choi, Sanghyeon Lee, Hyungkyu Ham, Gwangsun Kim, Divya Mahajan, Jongse Park
0
0
Modern transformer-based Large Language Models (LLMs) are constructed with a series of decoder blocks. Each block comprises three key components: (1) QKV generation, (2) multi-head attention, and (3) feed-forward networks. In batched processing, QKV generation and feed-forward networks involve compute-intensive matrix-matrix multiplications (GEMM), while multi-head attention requires bandwidth-heavy matrix-vector multiplications (GEMV). Machine learning accelerators like TPUs or NPUs are proficient in handling GEMM but are less efficient for GEMV computations. Conversely, Processing-in-Memory (PIM) technology is tailored for efficient GEMV computation, while it lacks the computational power to handle GEMM effectively. Inspired by this insight, we propose NeuPIMs, a heterogeneous acceleration system that jointly exploits a conventional GEMM-focused NPU and GEMV-optimized PIM devices. The main challenge in efficiently integrating NPU and PIM lies in enabling concurrent operations on both platforms, each addressing a specific kernel type. First, existing PIMs typically operate in a blocked mode, allowing only either NPU or PIM to be active at any given time. Second, the inherent dependencies between GEMM and GEMV in LLMs restrict their parallel processing. To tackle these challenges, NeuPIMs is equipped with dual row buffers in each bank, facilitating the simultaneous management of memory read/write operations and PIM commands. Further, NeuPIMs employs a runtime sub-batch interleaving technique to maximize concurrent execution, leveraging batch parallelism to allow two independent sub-batches to be pipelined within a single NeuPIMs device. Our evaluation demonstrates that compared to GPU-only, NPU-only, and a naive NPU+PIM integrated acceleration approaches, NeuPIMs achieves 3$times$, 2.4$times$ and 1.6$times$ throughput improvement, respectively.
4/1/2024

Balanced Data Placement for GEMV Acceleration with Processing-In-Memory
Mohamed Assem Ibrahim, Mahzabeen Islam, Shaizeen Aga
0
0
With unprecedented demand for generative AI (GenAI) inference, acceleration of primitives that dominate GenAI such as general matrix-vector multiplication (GEMV) is receiving considerable attention. A challenge with GEMVs is the high memory bandwidth this primitive demands. Multiple memory vendors have proposed commercially viable processing-in-memory (PIM) prototypes that attain bandwidth boost over processor via augmenting memory banks with compute capabilities and broadcasting same command to all banks. While proposed PIM designs stand to accelerate GEMV, we observe in this work that a key impediment to truly harness PIM acceleration is deducing optimal data-placement to place the matrix in memory banks. To this end, we tease out several factors that impact data-placement and propose PIMnast methodology which, like a gymnast, balances these factors to identify data-placements that deliver GEMV acceleration. Across a spectrum of GenAI models, our proposed PIMnast methodology along with additional orchestration knobs we identify delivers up to 6.86$times$ speedup for GEMVs (of the available 7$times$ roofline speedup) leading to up to 5$times$ speedup for per-token latencies.
4/1/2024
Towards Universal Performance Modeling for Machine Learning Training on Multi-GPU Platforms
Zhongyi Lin, Ning Sun, Pallab Bhattacharya, Xizhou Feng, Louis Feng, John D. Owens
0
0
Characterizing and predicting the training performance of modern machine learning (ML) workloads on compute systems with compute and communication spread between CPUs, GPUs, and network devices is not only the key to optimization and planning but also a complex goal to achieve. The primary challenges include the complexity of synchronization and load balancing between CPUs and GPUs, the variance in input data distribution, and the use of different communication devices and topologies (e.g., NVLink, PCIe, network cards) that connect multiple compute devices, coupled with the desire for flexible training configurations. Built on top of our prior work for single-GPU platforms, we address these challenges and enable multi-GPU performance modeling by incorporating (1) data-distribution-aware performance models for embedding table lookup, and (2) data movement prediction of communication collectives, into our upgraded performance modeling pipeline equipped with inter-and intra-rank synchronization for ML workloads trained on multi-GPU platforms. Beyond accurately predicting the per-iteration training time of DLRM models with random configurations with a geomean error of 5.21% on two multi-GPU platforms, our prediction pipeline generalizes well to other types of ML workloads, such as Transformer-based NLP models with a geomean error of 3.00%. Moreover, even without actually running ML workloads like DLRMs on the hardware, it is capable of generating insights such as quickly selecting the fastest embedding table sharding configuration (with a success rate of 85%).
4/30/2024
🔄
On Error Correction for Nonvolatile Processing-In-Memory
Husrev C{i}lasun, Salonik Resch, Zamshed I. Chowdhury, Masoud Zabihi, Yang Lv, Brandon Zink, Jian-Ping Wang, Sachin S. Sapatnekar, Ulya R. Karpuzcu
0
0
Processing in memory (PiM) represents a promising computing paradigm to enhance performance of numerous data-intensive applications. Variants performing computing directly in emerging nonvolatile memories can deliver very high energy efficiency. PiM architectures directly inherit the vulnerabilities of the underlying memory substrates, but they also are subject to errors due to the computation in place. Numerous well-established error correcting codes (ECC) for memory exist, and are also considered in the PiM context, however, they typically ignore errors that occur throughout computation. In this paper we revisit the error correction design space for nonvolatile PiM, considering both storage/memory and computation-induced errors, surveying several self-checking and homomorphic approaches. We propose several solutions and analyze their complex performance-area-coverage trade-off, using three representative nonvolatile PiM technologies. All of these solutions guarantee single error correction for both, bulk bitwise computations and ordinary memory/storage errors.
4/30/2024