Bayesian Statistical Modeling with Predictors from LLMs
2406.09012
0
0
🤿
Abstract
State of the art large language models (LLMs) have shown impressive performance on a variety of benchmark tasks and are increasingly used as components in larger applications, where LLM-based predictions serve as proxies for human judgements or decision. This raises questions about the human-likeness of LLM-derived information, alignment with human intuition, and whether LLMs could possibly be considered (parts of) explanatory models of (aspects of) human cognition or language use. To shed more light on these issues, we here investigate the human-likeness of LLMs' predictions for multiple-choice decision tasks from the perspective of Bayesian statistical modeling. Using human data from a forced-choice experiment on pragmatic language use, we find that LLMs do not capture the variance in the human data at the item-level. We suggest different ways of deriving full distributional predictions from LLMs for aggregate, condition-level data, and find that some, but not all ways of obtaining condition-level predictions yield adequate fits to human data. These results suggests that assessment of LLM performance depends strongly on seemingly subtle choices in methodology, and that LLMs are at best predictors of human behavior at the aggregate, condition-level, for which they are, however, not designed to, or usually used to, make predictions in the first place.
Create account to get full access
Overview
- The paper investigates the "human-likeness" of large language models (LLMs) by comparing their performance on multiple-choice decision tasks to human behavior.
- Using data from a forced-choice experiment on pragmatic language use, the researchers find that LLMs do not capture the variability in human responses at the individual item level.
- The paper explores different approaches to deriving distributional predictions from LLMs and assessing how well they fit the human data at the aggregate, condition level.
- The results suggest that the assessment of LLM performance depends on the specific methodological choices and that LLMs are better suited for predicting human behavior at the aggregate level, rather than individual-level predictions.
Plain English Explanation
Large language models (LLMs) have become increasingly prominent in various applications, often serving as proxies for human judgments or decision-making. This raises questions about how "human-like" the information generated by these models really is and whether they could be considered as models of human cognition or language use.
To better understand these issues, the researchers in this paper looked at how well LLMs perform on multiple-choice decision tasks compared to actual human behavior. They used data from an experiment where people had to make pragmatic [https://aimodels.fyi/papers/arxiv/probing-large-language-models-from-human-behavioral] language use choices.
The researchers found that the LLMs were not able to capture the variability in the human responses at the individual level. However, they explored different ways of using the LLMs to make predictions at the overall, "condition" level (rather than individual responses). Some of these approaches were able to reasonably match the human data, while others were not.
The key takeaway is that the success of LLMs in predicting human behavior depends a lot on the specific methods used. LLMs may be better suited for making predictions at the aggregate, group level, rather than trying to model individual human decisions. This is an important consideration as these models are increasingly used in applications that rely on human-like judgments.
Technical Explanation
The paper investigates the "human-likeness" of large language models (LLMs) by comparing their performance on multiple-choice decision tasks to human behavior. Using data from a forced-choice experiment on pragmatic language use, the researchers find that LLMs do not capture the variance in the human data at the item-level.
The researchers explore different ways of deriving full distributional predictions from LLMs for aggregate, condition-level data. Some approaches, such as [https://aimodels.fyi/papers/arxiv/llm-processes-numerical-predictive-distributions-conditioned-natural], yield adequate fits to the human data, while others do not. The results suggest that the assessment of LLM performance depends strongly on the specific methodological choices.
Overall, the findings indicate that LLMs are at best predictors of human behavior at the aggregate, condition-level, for which they are not typically designed or used to make predictions. The paper raises important questions about the [https://aimodels.fyi/papers/arxiv/psychometric-predictive-power-large-language-models] and [https://aimodels.fyi/papers/arxiv/humans-vs-large-language-models-judgmental-forecasting] of LLMs in applications that rely on human-like judgments or decision-making.
Critical Analysis
The paper provides a thoughtful examination of the limitations of using LLMs as proxies for human cognition or decision-making. The researchers acknowledge that LLMs are not designed to make predictions at the individual level and that their performance should be assessed at the aggregate, condition level.
However, the paper does not address the potential reasons why LLMs may struggle to capture the variability in human responses. It would be helpful to understand more about the specific cognitive and linguistic processes underlying the pragmatic language use tasks and how they may differ from the underlying mechanisms of LLMs.
Additionally, the paper could have explored the potential implications of these findings for the [https://aimodels.fyi/papers/arxiv/do-large-language-models-perform-way-people] of LLMs in real-world applications. While the researchers mention the increasing use of LLMs as proxies for human judgments, they do not delve into the potential risks or ethical considerations of this practice.
Overall, the paper provides valuable insights into the challenges of using LLMs to model human behavior and highlights the need for more nuanced approaches to assessing the capabilities and limitations of these powerful language models.
Conclusion
This paper sheds light on the limitations of using large language models (LLMs) as proxies for human judgments or decision-making. The researchers find that LLMs do not capture the variability in human responses on multiple-choice decision tasks at the individual level, despite their impressive performance on various benchmarks.
The paper explores different approaches to deriving distributional predictions from LLMs and assessing their fit to human data at the aggregate, condition level. The results suggest that the success of LLMs in predicting human behavior depends on the specific methodological choices, and that LLMs are better suited for making predictions at the group level rather than individual-level predictions.
These findings have important implications for the use of LLMs in applications that rely on human-like judgments or decision-making. As these models become more prevalent, it is crucial to understand their limitations and develop more nuanced approaches to assessing their performance and potential applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Probing Large Language Models from A Human Behavioral Perspective
Xintong Wang, Xiaoyu Li, Xingshan Li, Chris Biemann
0
0
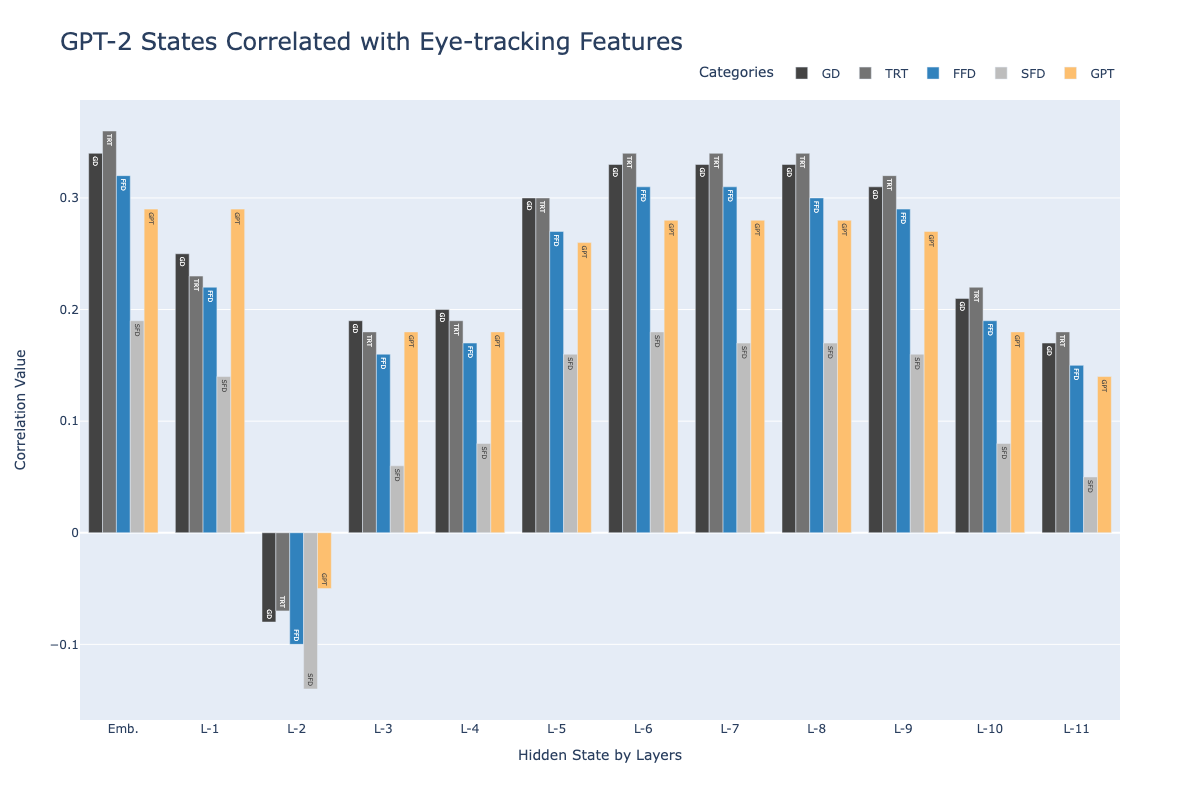
Large Language Models (LLMs) have emerged as dominant foundational models in modern NLP. However, the understanding of their prediction processes and internal mechanisms, such as feed-forward networks (FFN) and multi-head self-attention (MHSA), remains largely unexplored. In this work, we probe LLMs from a human behavioral perspective, correlating values from LLMs with eye-tracking measures, which are widely recognized as meaningful indicators of human reading patterns. Our findings reveal that LLMs exhibit a similar prediction pattern with humans but distinct from that of Shallow Language Models (SLMs). Moreover, with the escalation of LLM layers from the middle layers, the correlation coefficients also increase in FFN and MHSA, indicating that the logits within FFN increasingly encapsulate word semantics suitable for predicting tokens from the vocabulary.
4/16/2024
🌿
LLM Processes: Numerical Predictive Distributions Conditioned on Natural Language
James Requeima, John Bronskill, Dami Choi, Richard E. Turner, David Duvenaud
0
0
Machine learning practitioners often face significant challenges in formally integrating their prior knowledge and beliefs into predictive models, limiting the potential for nuanced and context-aware analyses. Moreover, the expertise needed to integrate this prior knowledge into probabilistic modeling typically limits the application of these models to specialists. Our goal is to build a regression model that can process numerical data and make probabilistic predictions at arbitrary locations, guided by natural language text which describes a user's prior knowledge. Large Language Models (LLMs) provide a useful starting point for designing such a tool since they 1) provide an interface where users can incorporate expert insights in natural language and 2) provide an opportunity for leveraging latent problem-relevant knowledge encoded in LLMs that users may not have themselves. We start by exploring strategies for eliciting explicit, coherent numerical predictive distributions from LLMs. We examine these joint predictive distributions, which we call LLM Processes, over arbitrarily-many quantities in settings such as forecasting, multi-dimensional regression, black-box optimization, and image modeling. We investigate the practical details of prompting to elicit coherent predictive distributions, and demonstrate their effectiveness at regression. Finally, we demonstrate the ability to usefully incorporate text into numerical predictions, improving predictive performance and giving quantitative structure that reflects qualitative descriptions. This lets us begin to explore the rich, grounded hypothesis space that LLMs implicitly encode.
5/28/2024
💬
Psychometric Predictive Power of Large Language Models
Tatsuki Kuribayashi, Yohei Oseki, Timothy Baldwin
0
0
Instruction tuning aligns the response of large language models (LLMs) with human preferences. Despite such efforts in human--LLM alignment, we find that instruction tuning does not always make LLMs human-like from a cognitive modeling perspective. More specifically, next-word probabilities estimated by instruction-tuned LLMs are often worse at simulating human reading behavior than those estimated by base LLMs. In addition, we explore prompting methodologies for simulating human reading behavior with LLMs. Our results show that prompts reflecting a particular linguistic hypothesis improve psychometric predictive power, but are still inferior to small base models. These findings highlight that recent advancements in LLMs, i.e., instruction tuning and prompting, do not offer better estimates than direct probability measurements from base LLMs in cognitive modeling. In other words, pure next-word probability remains a strong predictor for human reading behavior, even in the age of LLMs.
4/16/2024
Explicit and Implicit Large Language Model Personas Generate Opinions but Fail to Replicate Deeper Perceptions and Biases
Salvatore Giorgi, Tingting Liu, Ankit Aich, Kelsey Isman, Garrick Sherman, Zachary Fried, Jo~ao Sedoc, Lyle H. Ungar, Brenda Curtis
0
0
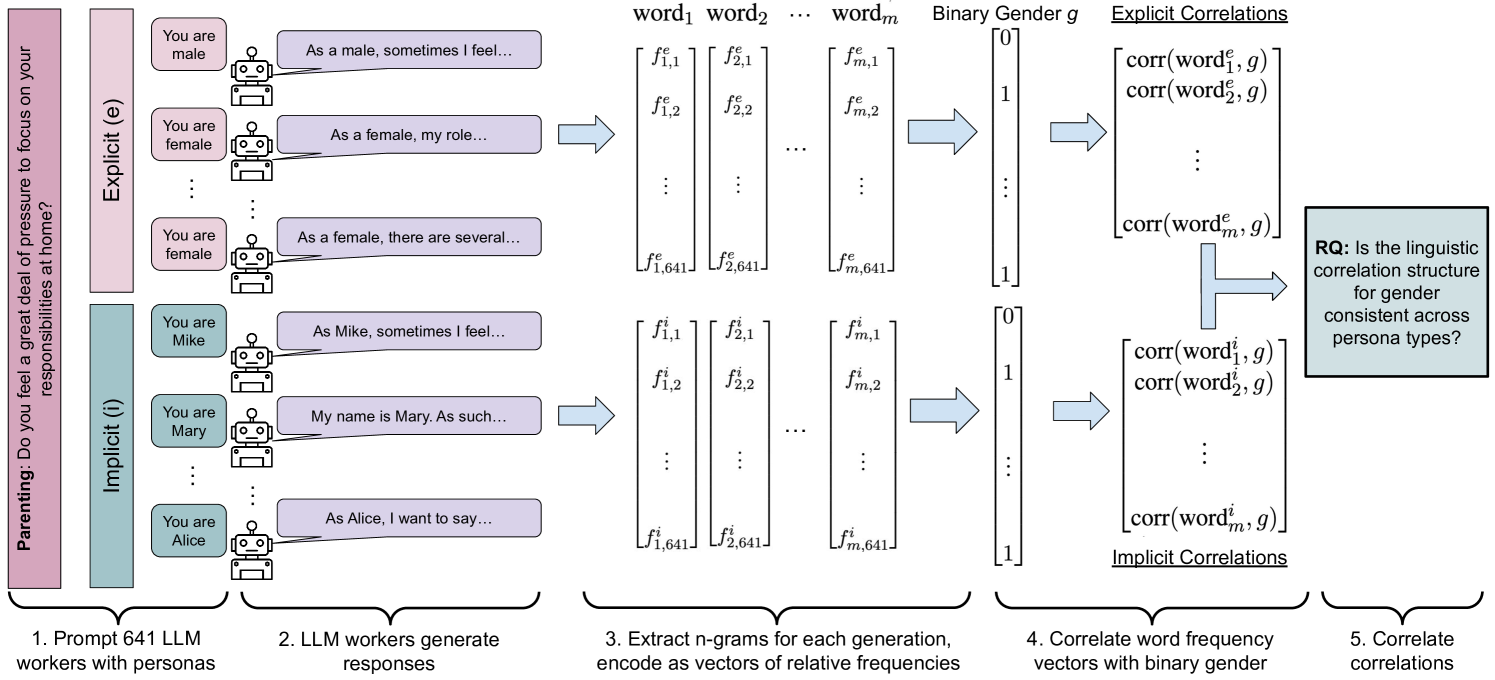
Large language models (LLMs) are increasingly being used in human-centered social scientific tasks, such as data annotation, synthetic data creation, and engaging in dialog. However, these tasks are highly subjective and dependent on human factors, such as one's environment, attitudes, beliefs, and lived experiences. Thus, employing LLMs (which do not have such human factors) in these tasks may result in a lack of variation in data, failing to reflect the diversity of human experiences. In this paper, we examine the role of prompting LLMs with human-like personas and asking the models to answer as if they were a specific human. This is done explicitly, with exact demographics, political beliefs, and lived experiences, or implicitly via names prevalent in specific populations. The LLM personas are then evaluated via (1) subjective annotation task (e.g., detecting toxicity) and (2) a belief generation task, where both tasks are known to vary across human factors. We examine the impact of explicit vs. implicit personas and investigate which human factors LLMs recognize and respond to. Results show that LLM personas show mixed results when reproducing known human biases, but generate generally fail to demonstrate implicit biases. We conclude that LLMs lack the intrinsic cognitive mechanisms of human thought, while capturing the statistical patterns of how people speak, which may restrict their effectiveness in complex social science applications.
6/21/2024