Bespoke Large Language Models for Digital Triage Assistance in Mental Health Care

0
Sign in to get full access
Introduction
The paper discusses the potential of using large language models (LLMs) to assist clinicians in triaging patients to appropriate specialist mental healthcare teams within the UK's National Health Service (NHS). Mental healthcare in the NHS is stratified into primary, secondary, and tertiary services, with most patients requiring secondary care being referred to community mental health teams (CMHTs).
The referral process involves a written narrative from a general practitioner (GP) describing the patient's difficulties, symptoms, and relevant risks. CMHTs offer a single point-of-access and triage function, with some additional sub-specialist teams available for specific conditions like eating disorders or first-episode psychosis.
Triage decisions are made using the referral documentation and any available historical electronic health record (EHR) data. The process is time-consuming, subjective, and can lead to "referral bouncing" between teams, causing frustration for patients and referrers.
The authors propose using LLMs to assist clinicians in extracting relevant clinical data and allocating patients to appropriate teams, rather than automating the triage process entirely. This assisted triage approach could improve efficiency, transparency, and robustness of the triage process.
Challenges with Unstructured EHR Data
The paper discusses the challenges and considerations in using large language models (LLMs) for assisting in clinical triage tasks using electronic health record (EHR) data. The main points covered in this section include:
-
Clinical natural language processing (NLP) has traditionally relied on information extraction, heuristics, and named entity recognition to locate relevant information from noisy, idiosyncratic clinical text. In contrast, the authors propose using LLMs to generate embeddings of patients' referral information and histories to determine the best triage team alignment.
-
Managing variable token sequence lengths is a challenge when using transformer-based LLMs for long sequences due to the finite context window and quadratic time- and memory-complexity of the self-attention mechanism.
-
The idiosyncratic nature of clinical language, particularly in mental health, poses difficulties for general-purpose LLMs trained on biomedical research literature. Domain adaptation techniques, such as continued training on specialized datasets, can help mitigate these issues.
-
Clinical text in EHRs is often redundant and contains irrelevant information. The authors aim to develop approaches that automatically select or attend to the most relevant clinical information without requiring annotation.
-
Efficiency is crucial when utilizing LLMs in clinical settings with limited compute resources and the need for transparency. The authors seek to develop tractable LLM pipelines that enable fine-tuning on downstream tasks.
-
Related work has focused on using structured EHR data for patient embeddings and long sequence transformer-based approaches for predicting clinical outcomes, but few have investigated mental health-specific EHR data.
The desiderata for LLM-assisted triage include end-to-end ingestion of unstructured clinical text, resource efficiency, model interpretability, and the ability to train at scale without expert annotation.
Methods
The study used electronic health record data from approximately 200,000 patients spanning over a decade from Oxford Health NHS Foundation Trust. The data included narrative clinical notes and structured information related to referrals and discharges. A heuristic rule was developed to determine if a referral was accepted by a team based on the referral date and a 14-day cut-off. The study focused on five sub-specialty teams: eating disorders, mental health for people with intellectual disability, older-adults, early intervention for psychosis, and peri-natal psychiatry.
The study compared three approaches for handling variable token sequence lengths in the clinical notes:
A. Document-level 'brute force' approach: Each document is tokenized, truncated, and passed to the language model (LLM) for classification. The recommended triage team is determined by majority vote.
B. Instance-level single concatenated sequence approach: Documents are concatenated, tokenized, and truncated before being passed to the LLM. The recommended team is determined by the classification head.
C. Instance-level segment-and-batch approach: Documents are concatenated, tokenized, and divided into fixed-size segments. The segments are processed as a batch by the LLM, and the recommended team is determined by the classification head.
The study also utilized Low-Rank-Adaptation (LoRA) to improve training efficiency by reducing the number of trainable parameters during fine-tuning. The project was reviewed and approved by the Oversight Committee of the Oxford Health NHS Foundation Trust and the Research and Development Team.
Implementation details
Data Preprocessing and Model Training Details
The authors performed minimal data cleaning for language modeling with transformer-based models. Preprocessing steps included removing extra whitespace, carriage returns, tabs, and poorly encoded characters. Acronyms and jargon were intentionally kept to encourage the language models to learn the noise in clinical text.
Training, inference, and evaluation were performed on a single NVIDIA Tesla T4 16 GB GPU on a private AWS instance. The data was split based on unique patient identifiers to prevent data leakage. Sample numbers for the datasets are provided in Table 2.
Different modeling approaches, including Brute force, Concat truncated, Concat Longformer, and Segment-batch, were used. These approaches have varying compute requirements, so hyperparameters could not be fully aligned during training. The hyperparameters used for each approach are summarized in Table 3.
Results
The paper compares three sequence representation methods for handling variable document and instance lengths in electronic health record (EHR) data. The methods are evaluated using RoBERTa models, either fine-tuned on OHFT data or without fine-tuning. The "segment-and-batch" method consistently performs best, and using LoRA for training efficiency incurs only a small performance degradation.
The paper also examines the relationship between instance length and classification performance. Instances are stratified into short, medium, long, and extra long sequences based on token counts. The results show that longer instances lead to better classifier performance for all three methods, with the "segment-and-batch" approach being consistently as good or better than the other methods across all sequence lengths.
Discussion
The paper describes the development of a resource-efficient large language model (LLM) for triaging patient referrals to secondary care mental health teams using electronic health record (EHR) data. The segment-and-batch approach showed the best performance while providing the desired properties of an end-to-end system. The authors propose that their approach emulates the processes used by clinical teams in NHS community out-patient settings.
The segment-and-batch method enables consistent performance over a broad range of token sequence lengths and gracefully handles short or sparse clinical documents. The model utilizes a combination of administrative data and a heuristic based on expected clinical team behavior to deliver a training target for classifying instances.
Using LoRA and the segment-and-batch architecture, training and inference can be managed on a single GPU. The model also allows for interrogation using "interpretability through presentation." An additional benefit of using LoRA with an LLM is the potential for re-using a pre-trained base LLM as a general-purpose encoder for deriving embeddings for similar applications in mental healthcare.
Limitations of the study include the intentional use of smaller LLMs due to computational resource constraints, the need for further validation of the triage assistance system's alignment with clinical practice, and the inability to share the underlying models due to data privacy concerns.
Future work should focus on testing the acceptability and utility of the "interpretability by presentation" model with clinicians, and exploring the implementation of an ensemble of triage 'agents' specializing in detecting and representing signal for specific teams. However, the ensemble approach raises ethical questions regarding the potential reflection of biased and inequitable triaging behavior.
Acknowledgements
Acknowledgment The authors acknowledge the work and support provided by the Oxford Research Informatics Team. The team includes Tanya Smith, the Research Informatics Manager, Adam Pill and Suzanne Fisher, who are Research Informatics Systems Analysts, and Lulu Kane, the Research Informatics Administrator.
Funding
The authors acknowledge funding support from various sources. NT was supported by the EPSRC Center for Doctoral Training in Health Data Science. AK, ANH, IL, and DWJ received partial support from the NIHR AI Award for Health and Social Care. DWJ also received support from an NIHR Infrastructure Programme. AC was supported by the NIHR Oxford Cognitive Health Clinical Research Facility, an NIHR Research Professorship, the NIHR Oxford and Thames Valley Applied Research Collaboration, the NIHR Oxford Health Biomedical Research Centre, and the Wellcome Trust. The views expressed are those of the authors and not necessarily those of the UK National Health Service, the NIHR, or the UK Department of Health.
ontributions
The authors N.T., D.W.J., A.K., and A.N.J. conceptualized the research. N.T. and D.W.J. curated the datasets and N.T. developed the code for pre-processing, running experiments, and analysis. N.T. and D.W.J. wrote the initial draft of the manuscript, which was then revised and edited by A.K., A.N.H., I.L., and A.C. All authors reviewed and approved the final manuscript.
Appendix A Triage and Team Referral Bouncing
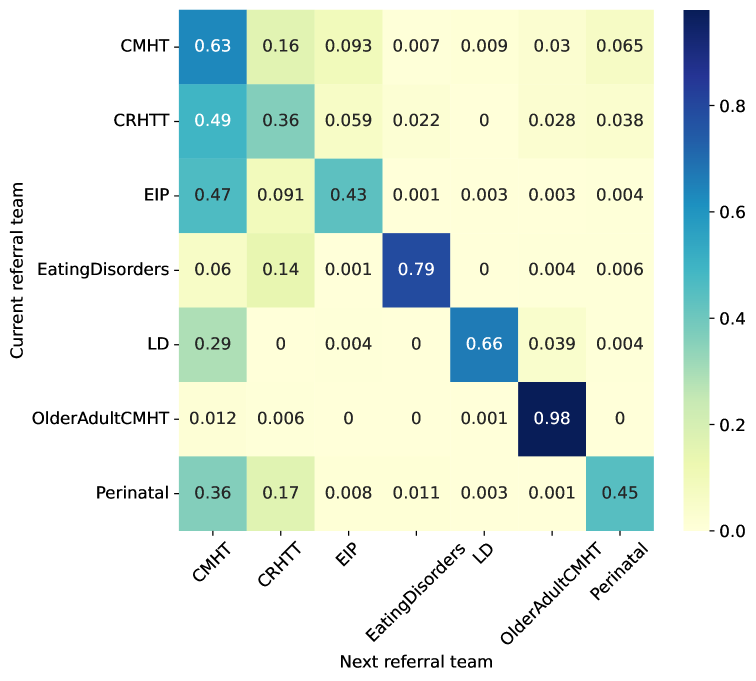
The paper discusses the common pathway for patients to receive specialist secondary care through referrals from primary care physicians. It explains the concept of "referral bouncing," where a referral is forwarded from one team to another due to service pressures or arbitrary application of referral criteria. The authors acknowledge that there can be legitimate clinical reasons for referral forwarding, such as when a team functions as a single-point-of-access for a geographical region in addition to their assessment/treatment function.
The paper presents a descriptive analysis of initial first- and second-referral patterns in their dataset, using community mental health teams (CMHTs) as an example. CMHTs often receive referrals for patients in crisis, which they then refer to crisis resolution and home treatment (CRHTT) teams. The asymmetry in referral patterns is also discussed, with the example of patients referred to Early Intervention in Psychosis (EIP) teams having a high probability of being referred to CMHTs or CRHTTs.
The authors emphasize that using language models and classification to assist in triage is an inductive learning problem using a discriminative model. The electronic health record (EHR) data does not explicitly describe the clinical reasoning behind accepting or rejecting a referral, making it challenging to determine the reasons for referral bouncing in specific instances.
Appendix B Dataset Details
The paper presents a heuristic for determining whether a referral was accepted or rejected based on the available structured data in the electronic health record (EHR) system of Oxford Health NHS Foundation Trust. The heuristic considers a referral as rejected if it is discharged within 14 days of the referral date. This "14 day rule" is supported by the distribution of referral durations, which shows a large proportion of referrals being discharged on the same day and a slight peak around 14 days.
The paper also provides statistics on the number of tokens per individual document and per referral instance. The mean number of tokens per document is 183, with the 90th percentile at 388 tokens. For concatenated instances, the mean token count is 6,420, with the 90th percentile at 11,427 tokens. The distribution of token numbers per instance is similar for accepted and rejected referrals, with median values of 1,463 and 1,367 tokens, respectively.
Appendix C Toward Interpretable Triage Recommendations
The paper argues that providing mechanistic or intrinsic interpretability for contemporary AI systems built using 'black box' methods, such as LLMs with downstream classification tasks, may not be possible. Instead, the authors propose an approach called interpretability through presentation, which exposes key stages or steps in the computational process as graphical intuitions to allow clinicians to interrogate decisions made by the system.
The process involves:
- Mapping an instance to a location in a 768-dimensional embedding space
- Learning a mapping from the embedding space to the probability of being accepted by one of 5 sub-specialty teams
To present this process to users, the authors:
- Use dimensionality reduction to display a planar projection of the embedding space, providing a map of the population of instances and emphasizing clustering of similar referral instances
- Exploit label-aware attention weights to visually highlight instance tokens that contributed most to the classification, enabling users to inspect the 'source' information driving the triage recommendation
The authors present a prototype user interface and show how different types of clinical notes are handled by their assisted triage model. Four examples of clinical notes are provided to illustrate the system's performance:
- A mental state examination implying a psychotic episode, suggesting a referral to an early intervention for psychosis (EIP) team
- A clinical note summarizing a patient's history and clinical review, also suggesting an EIP team referral
- Three short summative notes from different healthcare professionals, strongly implying a referral to an older adult team
- A brief note with evidence of historical care from a learning disability team but current focus on occupational therapy and frailty, suggesting a referral to an older adult team
The model outputs for each example include:
- The clinical note with highlighting proportional to the model's label-aware attention weights
- A planar projection of the embeddings of all patients' instances, indicating the relative location of the query instance




The model demonstrates the ability to identify important information for classifying triage team decisions. The examples show the model highlighting relevant details for specific teams, such as signs of schizophrenia for the Early Intervention Psychosis (EIP) team and memory problems and next steps for the older adult community mental health team (oaCMHT). The model's attention focuses on the most salient parts of the notes, emphasizing the key information needed for accurate team assignment.
Appendix D LoRA
LoRA (Low-Rank Adaptation) is a reparameterization technique for efficiently adapting large language models (LLMs). It approximates the weight update of any weight matrix in the LLM using two trainable matrices, A and B, which act as a low-rank approximation of the singular value decomposition (SVD) of the weight update. The rank of the LoRA matrices is a tunable parameter, typically much smaller than the dimensions of the original weight matrices.
In the forward pass, the weight matrices are updated by adding the product of A and B to the original weights. LoRA is commonly applied to the key, query, and value matrices in the transformer architecture, assuming that weight updates in LLMs have an intrinsically low rank compared to their dimensions.
Once trained, the LoRA matrices can be integrated into the model, resulting in no additional inference latency. During training, the original weight matrices of the LLM remain frozen, making LoRA an efficient training method for adapting large language models to new tasks or domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Bespoke Large Language Models for Digital Triage Assistance in Mental Health Care
Niall Taylor, Andrey Kormilitzin, Isabelle Lorge, Alejo Nevado-Holgado, Dan W Joyce
Contemporary large language models (LLMs) may have utility for processing unstructured, narrative free-text clinical data contained in electronic health records (EHRs) -- a particularly important use-case for mental health where a majority of routinely-collected patient data lacks structured, machine-readable content. A significant problem for the the United Kingdom's National Health Service (NHS) are the long waiting lists for specialist mental healthcare. According to NHS data, in each month of 2023, there were between 370,000 and 470,000 individual new referrals into secondary mental healthcare services. Referrals must be triaged by clinicians, using clinical information contained in the patient's EHR to arrive at a decision about the most appropriate mental healthcare team to assess and potentially treat these patients. The ability to efficiently recommend a relevant team by ingesting potentially voluminous clinical notes could help services both reduce referral waiting times and with the right technology, improve the evidence available to justify triage decisions. We present and evaluate three different approaches for LLM-based, end-to-end ingestion of variable-length clinical EHR data to assist clinicians when triaging referrals. Our model is able to deliver triage recommendations consistent with existing clinical practices and it's architecture was implemented on a single GPU, making it practical for implementation in resource-limited NHS environments where private implementations of LLM technology will be necessary to ensure confidential clinical data is appropriately controlled and governed.
Read more4/1/2024

0
Lifelong Personalized Low-Rank Adaptation of Large Language Models for Recommendation
Jiachen Zhu, Jianghao Lin, Xinyi Dai, Bo Chen, Rong Shan, Jieming Zhu, Ruiming Tang, Yong Yu, Weinan Zhang
We primarily focus on the field of large language models (LLMs) for recommendation, which has been actively explored recently and poses a significant challenge in effectively enhancing recommender systems with logical reasoning abilities and open-world knowledge. Current mainstream efforts mainly center around injecting personalized information from recommendation models into LLMs by customizing input templates or aligning representations between semantic and recommendation spaces at the prediction layer. However, they face three significant limitations: (1) LoRA is mostly used as a core component in existing works, but personalization is not well established in LoRA parameters as the LoRA matrix shared by every user may not cater to different users' characteristics, leading to suboptimal performance. (2) Although lifelong personalized behavior sequences are ideal for personalization, their use raises effectiveness and efficiency issues since LLMs require escalating training and inference time to extend text lengths. (3) Existing approaches aren't scalable for large datasets due to training efficiency constraints. Thus, LLMs only see a small fraction of the datasets (e.g., less than 10%) instead of the whole datasets, limiting their exposure to the full training space. To address these problems, we propose RecLoRA. This model incorporates a Personalized LoRA module that maintains independent LoRAs for different users and a Long-Short Modality Retriever that retrieves different history lengths for different modalities, significantly improving performance while adding minimal time cost. Furthermore, we design a Few2Many Learning Strategy, using a conventional recommendation model as a lens to magnify small training spaces to full spaces. Extensive experiments on public datasets demonstrate the efficacy of our RecLoRA compared to existing baseline models.
Read more8/13/2024
💬
0
A scoping review of using Large Language Models (LLMs) to investigate Electronic Health Records (EHRs)
Lingyao Li, Jiayan Zhou, Zhenxiang Gao, Wenyue Hua, Lizhou Fan, Huizi Yu, Loni Hagen, Yongfeng Zhang, Themistocles L. Assimes, Libby Hemphill, Siyuan Ma
Electronic Health Records (EHRs) play an important role in the healthcare system. However, their complexity and vast volume pose significant challenges to data interpretation and analysis. Recent advancements in Artificial Intelligence (AI), particularly the development of Large Language Models (LLMs), open up new opportunities for researchers in this domain. Although prior studies have demonstrated their potential in language understanding and processing in the context of EHRs, a comprehensive scoping review is lacking. This study aims to bridge this research gap by conducting a scoping review based on 329 related papers collected from OpenAlex. We first performed a bibliometric analysis to examine paper trends, model applications, and collaboration networks. Next, we manually reviewed and categorized each paper into one of the seven identified topics: named entity recognition, information extraction, text similarity, text summarization, text classification, dialogue system, and diagnosis and prediction. For each topic, we discussed the unique capabilities of LLMs, such as their ability to understand context, capture semantic relations, and generate human-like text. Finally, we highlighted several implications for researchers from the perspectives of data resources, prompt engineering, fine-tuning, performance measures, and ethical concerns. In conclusion, this study provides valuable insights into the potential of LLMs to transform EHR research and discusses their applications and ethical considerations.
Read more5/24/2024

0
Large Language Models in Mental Health Care: a Scoping Review
Yining Hua, Fenglin Liu, Kailai Yang, Zehan Li, Hongbin Na, Yi-han Sheu, Peilin Zhou, Lauren V. Moran, Sophia Ananiadou, Andrew Beam, John Torous
The integration of large language models (LLMs) in mental health care is an emerging field. There is a need to systematically review the application outcomes and delineate the advantages and limitations in clinical settings. This review aims to provide a comprehensive overview of the use of LLMs in mental health care, assessing their efficacy, challenges, and potential for future applications. A systematic search was conducted across multiple databases including PubMed, Web of Science, Google Scholar, arXiv, medRxiv, and PsyArXiv in November 2023. All forms of original research, peer-reviewed or not, published or disseminated between October 1, 2019, and December 2, 2023, are included without language restrictions if they used LLMs developed after T5 and directly addressed research questions in mental health care settings. From an initial pool of 313 articles, 34 met the inclusion criteria based on their relevance to LLM application in mental health care and the robustness of reported outcomes. Diverse applications of LLMs in mental health care are identified, including diagnosis, therapy, patient engagement enhancement, etc. Key challenges include data availability and reliability, nuanced handling of mental states, and effective evaluation methods. Despite successes in accuracy and accessibility improvement, gaps in clinical applicability and ethical considerations were evident, pointing to the need for robust data, standardized evaluations, and interdisciplinary collaboration. LLMs hold substantial promise for enhancing mental health care. For their full potential to be realized, emphasis must be placed on developing robust datasets, development and evaluation frameworks, ethical guidelines, and interdisciplinary collaborations to address current limitations.
Read more8/22/2024