Beyond Flesch-Kincaid: Prompt-based Metrics Improve Difficulty Classification of Educational Texts
2405.09482
0
0

Abstract
Using large language models (LLMs) for educational applications like dialogue-based teaching is a hot topic. Effective teaching, however, requires teachers to adapt the difficulty of content and explanations to the education level of their students. Even the best LLMs today struggle to do this well. If we want to improve LLMs on this adaptation task, we need to be able to measure adaptation success reliably. However, current Static metrics for text difficulty, like the Flesch-Kincaid Reading Ease score, are known to be crude and brittle. We, therefore, introduce and evaluate a new set of Prompt-based metrics for text difficulty. Based on a user study, we create Prompt-based metrics as inputs for LLMs. They leverage LLM's general language understanding capabilities to capture more abstract and complex features than Static metrics. Regression experiments show that adding our Prompt-based metrics significantly improves text difficulty classification over Static metrics alone. Our results demonstrate the promise of using LLMs to evaluate text adaptation to different education levels.
Create account to get full access
Overview
- This paper explores the use of prompt-based metrics to improve the classification of educational text difficulty, going beyond traditional readability measures like the Flesch-Kincaid grade level.
- The researchers developed a new dataset of educational texts labeled by difficulty and used large language models to create prompt-based features for predicting text difficulty.
- The results show that prompt-based metrics can outperform Flesch-Kincaid and other standard readability metrics in accurately classifying the difficulty of educational texts.
Plain English Explanation
The paper focuses on finding better ways to measure how difficult a piece of educational text is. The standard way to do this is using the Flesch-Kincaid grade level, which looks at things like word length and sentence length. However, the researchers wanted to see if they could get more accurate difficulty ratings using newer techniques.
They created a dataset of educational texts that were manually labeled by experts as being easy, medium, or hard to read. Then they used large language models - powerful AI systems that can understand and generate human-like text - to analyze these texts in a more nuanced way.
Specifically, the researchers had the language models respond to prompts about the texts, like "Explain the main idea of this passage in your own words." The responses from the language models were used to create new features, or data points, that could be used to predict the difficulty level.
The results showed that this prompt-based approach was better at classifying the texts as easy, medium, or hard, compared to just using the standard Flesch-Kincaid metric. In other words, the new technique was more accurate at assessing how difficult a piece of educational material would be for a reader.
This is significant because being able to reliably gauge text difficulty is important for educators, content creators, and others who want to match readers with appropriate learning materials. The findings suggest that incorporating language model-based features can improve our ability to do that.
Technical Explanation
The paper presents a novel approach to assessing the difficulty of educational texts that goes beyond traditional readability measures like the Flesch-Kincaid grade level. The researchers created a dataset of educational texts labeled by difficulty level (https://aimodels.fyi/papers/arxiv/cseprompts-benchmark-introductory-computer-science-prompts) and explored the use of prompt-based features generated by large language models to predict text difficulty.
The key technical elements include:
- Developing a dataset of 1,000 educational texts across three difficulty levels (easy, medium, hard) based on expert annotations.
- Using large language models (e.g. GPT-3) to generate responses to prompts about the texts, such as "Summarize the main idea of this passage in your own words."
- Extracting features from the language model responses, such as perplexity, length, and sentiment, to use as predictors of text difficulty.
- Comparing the performance of prompt-based models to standard readability metrics like Flesch-Kincaid in classifying text difficulty.
The results show that the prompt-based approach significantly outperforms Flesch-Kincaid and other baseline methods in accurately classifying the difficulty of the educational texts (https://aimodels.fyi/papers/arxiv/can-large-language-models-automatically-score-proficiency, https://aimodels.fyi/papers/arxiv/state-what-art-call-multi-prompt-llm). This suggests that prompt-based metrics can provide more nuanced and accurate assessments of text difficulty compared to traditional readability formulas.
Critical Analysis
The paper makes a compelling case for the use of prompt-based metrics to improve the assessment of educational text difficulty. However, there are a few potential limitations and areas for further research worth considering:
-
The dataset used is relatively small (1,000 texts), and the texts are primarily from the domain of computer science. Expanding the dataset to cover a broader range of educational subjects and text types could help validate the generalizability of the findings.
-
The paper does not explore the potential biases or limitations of the language models used to generate the prompt-based features. Further research is needed to understand how the choice of language model and prompt design can impact the accuracy of the difficulty predictions (https://aimodels.fyi/papers/arxiv/fpt-feature-prompt-tuning-few-shot-readability).
-
The paper does not provide a detailed error analysis or qualitative insights into the types of texts that are most challenging for the prompt-based approach versus the Flesch-Kincaid metric. Understanding the strengths and weaknesses of each method could inform how they are best applied in practice.
Overall, the paper presents a promising new direction for assessing text difficulty, but more research is needed to fully understand the capabilities and limitations of the prompt-based approach.
Conclusion
This paper explores the use of prompt-based metrics generated by large language models to improve the classification of educational text difficulty, going beyond traditional readability measures like the Flesch-Kincaid grade level. The results show that the prompt-based approach can significantly outperform standard readability metrics in accurately assessing the difficulty of educational texts.
These findings have important implications for educators, content creators, and others who need to match readers with appropriate learning materials. By incorporating more nuanced, language model-based features, we can better understand and predict the difficulty level of educational texts, helping to ensure that students and learners are provided with materials that are appropriately challenging. Further research is needed to validate the generalizability of the approach and address potential limitations, but this paper represents an important step forward in advancing text difficulty assessment (https://aimodels.fyi/papers/arxiv/can-large-language-models-make-grade-empirical).
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Exploring the Capabilities of Prompted Large Language Models in Educational and Assessment Applications
Subhankar Maity, Aniket Deroy, Sudeshna Sarkar
0
0
In the era of generative artificial intelligence (AI), the fusion of large language models (LLMs) offers unprecedented opportunities for innovation in the field of modern education. We embark on an exploration of prompted LLMs within the context of educational and assessment applications to uncover their potential. Through a series of carefully crafted research questions, we investigate the effectiveness of prompt-based techniques in generating open-ended questions from school-level textbooks, assess their efficiency in generating open-ended questions from undergraduate-level technical textbooks, and explore the feasibility of employing a chain-of-thought inspired multi-stage prompting approach for language-agnostic multiple-choice question (MCQ) generation. Additionally, we evaluate the ability of prompted LLMs for language learning, exemplified through a case study in the low-resource Indian language Bengali, to explain Bengali grammatical errors. We also evaluate the potential of prompted LLMs to assess human resource (HR) spoken interview transcripts. By juxtaposing the capabilities of LLMs with those of human experts across various educational tasks and domains, our aim is to shed light on the potential and limitations of LLMs in reshaping educational practices.
5/21/2024

E-Bench: Towards Evaluating the Ease-of-Use of Large Language Models
Zhenyu Zhang, Bingguang Hao, Jinpeng Li, Zekai Zhang, Dongyan Zhao
0
0
Most large language models (LLMs) are sensitive to prompts, and another synonymous expression or a typo may lead to unexpected results for the model. Composing an optimal prompt for a specific demand lacks theoretical support and relies entirely on human experimentation, which poses a considerable obstacle to popularizing generative artificial intelligence. However, there is no systematic analysis of the stability of LLMs in resisting prompt perturbations in real-world scenarios. In this work, we propose to evaluate the ease-of-use of LLMs and construct E-Bench, simulating the actual situation of human use from synonymous perturbation (including paraphrasing, simplification, and colloquialism) and typographical perturbation (such as typing). On this basis, we also discuss the combination of these two types of perturbation and analyze the main reasons for performance degradation. Experimental results indicate that with the increase of model size, although the ease-of-use are significantly improved, there is still a long way to go to build a sufficiently user-friendly model.
6/18/2024
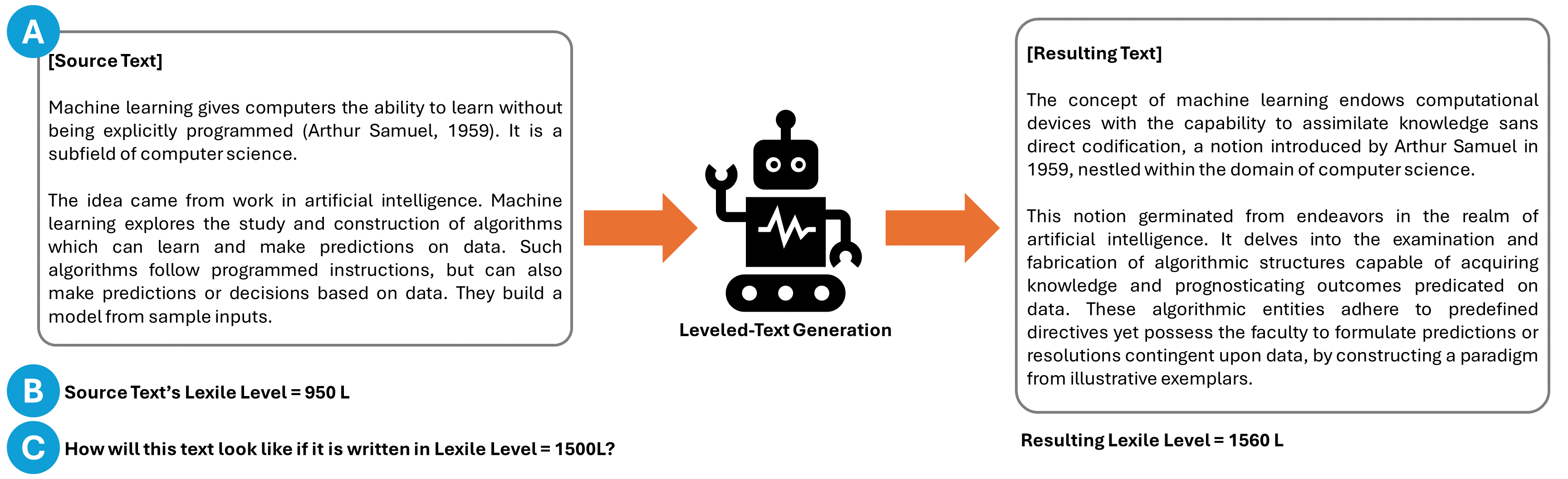
Generating Educational Materials with Different Levels of Readability using LLMs
Chieh-Yang Huang, Jing Wei, Ting-Hao 'Kenneth' Huang
0
0
This study introduces the leveled-text generation task, aiming to rewrite educational materials to specific readability levels while preserving meaning. We assess the capability of GPT-3.5, LLaMA-2 70B, and Mixtral 8x7B, to generate content at various readability levels through zero-shot and few-shot prompting. Evaluating 100 processed educational materials reveals that few-shot prompting significantly improves performance in readability manipulation and information preservation. LLaMA-2 70B performs better in achieving the desired difficulty range, while GPT-3.5 maintains original meaning. However, manual inspection highlights concerns such as misinformation introduction and inconsistent edit distribution. These findings emphasize the need for further research to ensure the quality of generated educational content.
6/19/2024

Efficient multi-prompt evaluation of LLMs
Felipe Maia Polo, Ronald Xu, Lucas Weber, M'irian Silva, Onkar Bhardwaj, Leshem Choshen, Allysson Flavio Melo de Oliveira, Yuekai Sun, Mikhail Yurochkin
0
0
Most popular benchmarks for comparing LLMs rely on a limited set of prompt templates, which may not fully capture the LLMs' abilities and can affect the reproducibility of results on leaderboards. Many recent works empirically verify prompt sensitivity and advocate for changes in LLM evaluation. In this paper, we consider the problem of estimating the performance distribution across many prompt variants instead of finding a single prompt to evaluate with. We introduce PromptEval, a method for estimating performance across a large set of prompts borrowing strength across prompts and examples to produce accurate estimates under practical evaluation budgets. The resulting distribution can be used to obtain performance quantiles to construct various robust performance metrics (e.g., top 95% quantile or median). We prove that PromptEval consistently estimates the performance distribution and demonstrate its efficacy empirically on three prominent LLM benchmarks: MMLU, BIG-bench Hard, and LMentry. For example, PromptEval can accurately estimate performance quantiles across 100 prompt templates on MMLU with a budget equivalent to two single-prompt evaluations. Our code and data can be found at https://github.com/felipemaiapolo/prompt-eval.
6/11/2024