Beyond Metrics: Evaluating LLMs' Effectiveness in Culturally Nuanced, Low-Resource Real-World Scenarios
2406.00343
0
0
Abstract
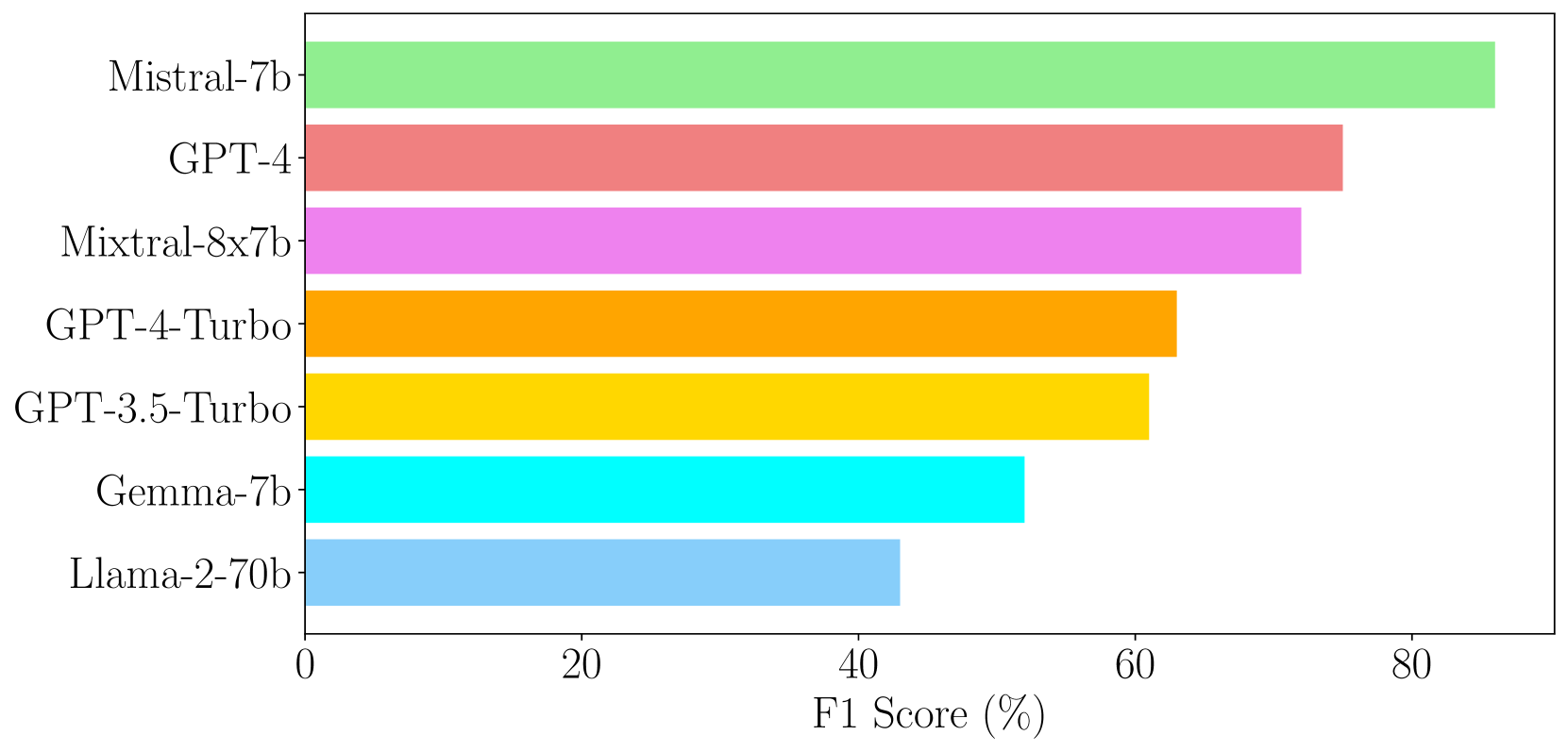
The deployment of Large Language Models (LLMs) in real-world applications presents both opportunities and challenges, particularly in multilingual and code-mixed communication settings. This research evaluates the performance of seven leading LLMs in sentiment analysis on a dataset derived from multilingual and code-mixed WhatsApp chats, including Swahili, English and Sheng. Our evaluation includes both quantitative analysis using metrics like F1 score and qualitative assessment of LLMs' explanations for their predictions. We find that, while Mistral-7b and Mixtral-8x7b achieved high F1 scores, they and other LLMs such as GPT-3.5-Turbo, Llama-2-70b, and Gemma-7b struggled with understanding linguistic and contextual nuances, as well as lack of transparency in their decision-making process as observed from their explanations. In contrast, GPT-4 and GPT-4-Turbo excelled in grasping diverse linguistic inputs and managing various contextual information, demonstrating high consistency with human alignment and transparency in their decision-making process. The LLMs however, encountered difficulties in incorporating cultural nuance especially in non-English settings with GPT-4s doing so inconsistently. The findings emphasize the necessity of continuous improvement of LLMs to effectively tackle the challenges of culturally nuanced, low-resource real-world settings and the need for developing evaluation benchmarks for capturing these issues.
Create account to get full access
Overview
- This paper examines the effectiveness of large language models (LLMs) in culturally nuanced, low-resource real-world scenarios, going beyond traditional metrics like perplexity and accuracy.
- The researchers developed a diverse evaluation dataset spanning multiple languages, cultures, and domains to assess LLM performance in realistic, contextual tasks.
- The findings reveal significant challenges for LLMs in capturing cultural nuances and handling low-resource scenarios, highlighting the need for more comprehensive evaluation methods.
Plain English Explanation
The paper looks at how well large language models, which are AI systems trained on massive amounts of text data, perform in real-world situations that involve cultural context and limited available information. Traditional ways of evaluating these models, like measuring how well they predict the next word in a sentence, don't always capture how useful they would be in practical applications.
The researchers created a diverse dataset that covers multiple languages, cultures, and topic areas to test the language models in more realistic scenarios. This revealed that the models struggle to fully understand cultural nuances and have trouble when there isn't much data available to train on. The findings suggest that we need better ways to evaluate these powerful AI systems beyond just looking at standard performance metrics.
The goal is to ensure these language models can be safely and effectively deployed in the real world, where they need to handle complex, context-dependent tasks rather than just performing well on simplified benchmarks. By taking a more comprehensive and nuanced approach to evaluation, the authors hope to drive progress in making large language models truly useful in diverse, low-resource settings.
Technical Explanation
The paper focuses on evaluating the effectiveness of large language models (LLMs) in culturally nuanced, low-resource real-world scenarios, which go beyond traditional metrics like perplexity and accuracy.
The researchers developed a diverse evaluation dataset called METAL that spans multiple languages, cultures, and domains. This dataset was used to assess LLM performance on realistic, contextual tasks that require understanding cultural nuances and handling low-resource conditions.
The results reveal significant challenges for LLMs in these real-world scenarios. The models struggled to capture cultural context and had difficulty in low-resource settings, where limited training data was available. This highlights the need for more comprehensive evaluation methods beyond standard benchmarks, as outlined in related work such as MEGAVERSE and Unveiling LLM Evaluation.
The findings also build on research examining the performance of large language models in the context of African languages (How Good Are Large Language Models on African?) and discussions around the deployment, tokenomics, and sustainability of these powerful AI systems.
Critical Analysis
The paper provides a valuable contribution by looking beyond traditional evaluation metrics and instead focusing on the real-world effectiveness of large language models in culturally nuanced, low-resource scenarios. This is an important step towards ensuring these powerful AI systems can be safely and responsibly deployed in diverse, practical applications.
However, the paper does not fully address the potential biases and fairness issues that may arise from the cultural and linguistic skew of the training data used for these LLMs. While the authors acknowledge the need for more comprehensive evaluation, further research is required to understand the deeper societal implications of potential biases and how to mitigate them.
Additionally, the paper could have explored the trade-offs between model performance and resource requirements, as well as the scalability and sustainability of these LLMs in real-world deployments. These are crucial considerations for the long-term viability and responsible development of large language models.
Conclusion
This paper highlights the importance of going beyond traditional evaluation metrics to assess the effectiveness of large language models in realistic, culturally nuanced, and low-resource scenarios. The findings reveal significant challenges for these powerful AI systems in capturing cultural context and handling limited data, underscoring the need for more comprehensive evaluation methods.
The research represents an important step towards ensuring large language models can be safely and responsibly deployed in diverse, real-world applications. By adopting a more holistic approach to evaluation, the authors aim to drive progress in making these AI systems truly useful and accessible across different cultures and contexts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

METAL: Towards Multilingual Meta-Evaluation
Rishav Hada, Varun Gumma, Mohamed Ahmed, Kalika Bali, Sunayana Sitaram
0
0
With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
4/3/2024
💬
MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks
Sanchit Ahuja, Divyanshu Aggarwal, Varun Gumma, Ishaan Watts, Ashutosh Sathe, Millicent Ochieng, Rishav Hada, Prachi Jain, Maxamed Axmed, Kalika Bali, Sunayana Sitaram
0
0
There has been a surge in LLM evaluation research to understand LLM capabilities and limitations. However, much of this research has been confined to English, leaving LLM building and evaluation for non-English languages relatively unexplored. Several new LLMs have been introduced recently, necessitating their evaluation on non-English languages. This study aims to perform a thorough evaluation of the non-English capabilities of SoTA LLMs (GPT-3.5-Turbo, GPT-4, PaLM2, Gemini-Pro, Mistral, Llama2, and Gemma) by comparing them on the same set of multilingual datasets. Our benchmark comprises 22 datasets covering 83 languages, including low-resource African languages. We also include two multimodal datasets in the benchmark and compare the performance of LLaVA models, GPT-4-Vision and Gemini-Pro-Vision. Our experiments show that larger models such as GPT-4, Gemini-Pro and PaLM2 outperform smaller models on various tasks, notably on low-resource languages, with GPT-4 outperforming PaLM2 and Gemini-Pro on more datasets. We also perform a study on data contamination and find that several models are likely to be contaminated with multilingual evaluation benchmarks, necessitating approaches to detect and handle contamination while assessing the multilingual performance of LLMs.
4/4/2024
💬
Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis
Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, Lei Li
0
0
Large language models (LLMs) have demonstrated remarkable potential in handling multilingual machine translation (MMT). In this paper, we systematically investigate the advantages and challenges of LLMs for MMT by answering two questions: 1) How well do LLMs perform in translating massive languages? 2) Which factors affect LLMs' performance in translation? We thoroughly evaluate eight popular LLMs, including ChatGPT and GPT-4. Our empirical results show that translation capabilities of LLMs are continually involving. GPT-4 has beat the strong supervised baseline NLLB in 40.91% of translation directions but still faces a large gap towards the commercial translation system like Google Translate, especially on low-resource languages. Through further analysis, we discover that LLMs exhibit new working patterns when used for MMT. First, LLM can acquire translation ability in a resource-efficient way and generate moderate translation even on zero-resource languages. Second, instruction semantics can surprisingly be ignored when given in-context exemplars. Third, cross-lingual exemplars can provide better task guidance for low-resource translation than exemplars in the same language pairs. Code will be released at: https://github.com/NJUNLP/MMT-LLM.
6/17/2024
🚀
Unveiling LLM Evaluation Focused on Metrics: Challenges and Solutions
Taojun Hu, Xiao-Hua Zhou
0
0
Natural Language Processing (NLP) is witnessing a remarkable breakthrough driven by the success of Large Language Models (LLMs). LLMs have gained significant attention across academia and industry for their versatile applications in text generation, question answering, and text summarization. As the landscape of NLP evolves with an increasing number of domain-specific LLMs employing diverse techniques and trained on various corpus, evaluating performance of these models becomes paramount. To quantify the performance, it's crucial to have a comprehensive grasp of existing metrics. Among the evaluation, metrics which quantifying the performance of LLMs play a pivotal role. This paper offers a comprehensive exploration of LLM evaluation from a metrics perspective, providing insights into the selection and interpretation of metrics currently in use. Our main goal is to elucidate their mathematical formulations and statistical interpretations. We shed light on the application of these metrics using recent Biomedical LLMs. Additionally, we offer a succinct comparison of these metrics, aiding researchers in selecting appropriate metrics for diverse tasks. The overarching goal is to furnish researchers with a pragmatic guide for effective LLM evaluation and metric selection, thereby advancing the understanding and application of these large language models.
4/16/2024