MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks
2311.07463
0
0
💬
Abstract
There has been a surge in LLM evaluation research to understand LLM capabilities and limitations. However, much of this research has been confined to English, leaving LLM building and evaluation for non-English languages relatively unexplored. Several new LLMs have been introduced recently, necessitating their evaluation on non-English languages. This study aims to perform a thorough evaluation of the non-English capabilities of SoTA LLMs (GPT-3.5-Turbo, GPT-4, PaLM2, Gemini-Pro, Mistral, Llama2, and Gemma) by comparing them on the same set of multilingual datasets. Our benchmark comprises 22 datasets covering 83 languages, including low-resource African languages. We also include two multimodal datasets in the benchmark and compare the performance of LLaVA models, GPT-4-Vision and Gemini-Pro-Vision. Our experiments show that larger models such as GPT-4, Gemini-Pro and PaLM2 outperform smaller models on various tasks, notably on low-resource languages, with GPT-4 outperforming PaLM2 and Gemini-Pro on more datasets. We also perform a study on data contamination and find that several models are likely to be contaminated with multilingual evaluation benchmarks, necessitating approaches to detect and handle contamination while assessing the multilingual performance of LLMs.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Researchers have been studying the capabilities and limitations of large language models (LLMs), but much of this research has focused on English, leaving non-English languages largely unexplored.
- Several new LLMs have been introduced recently, necessitating their evaluation on non-English languages.
- This study aims to comprehensively evaluate the non-English capabilities of state-of-the-art LLMs, including GPT-3.5-Turbo, GPT-4, PaLM2, Gemini-Pro, Mistral, Llama2, and Gemma.
- The benchmark includes 22 datasets covering 83 languages, including low-resource African languages, as well as two multimodal datasets.
Plain English Explanation
Researchers have been studying how well the latest and greatest language models, like GPT-4 and PaLM2, can handle tasks in languages other than English. This is important because these models are being used for all sorts of applications around the world, but a lot of the testing has focused on English.
The researchers in this study wanted to get a better understanding of how these models perform on a wide range of languages, including less common ones like some African languages. They tested the models on 22 different datasets covering 83 languages in total, as well as a couple of datasets that involve both language and images.
The key finding is that the larger, more powerful models like GPT-4 and Gemini-Pro tend to outperform the smaller models, especially when it comes to less common languages. But the researchers also found that some of the models may have been "contaminated" by being trained on the same datasets used to test them, which could skew the results.
Technical Explanation
The researchers conducted a comprehensive evaluation of the non-English capabilities of state-of-the-art LLMs, including GPT-3.5-Turbo, GPT-4, PaLM2, Gemini-Pro, Mistral, Llama2, and Gemma. They used a benchmark comprising 22 datasets covering 83 languages, including low-resource African languages, as well as two multimodal datasets.
The experiments showed that larger models like GPT-4, Gemini-Pro, and PaLM2 generally outperformed smaller models on various tasks, particularly on low-resource languages. GPT-4 outperformed PaLM2 and Gemini-Pro on more datasets.
The researchers also investigated the issue of data contamination, finding that several models were likely contaminated by the multilingual evaluation benchmarks used in the study. This highlights the need for robust methods to detect and handle contamination when assessing the multilingual performance of LLMs.
Critical Analysis
The study provides a valuable contribution to the understanding of LLM capabilities in non-English languages. However, the issue of data contamination raised by the researchers is a significant concern that warrants further investigation.
While the results suggest that larger models tend to perform better on low-resource languages, the extent of this advantage and its implications for real-world applications are not fully explored. Additional research is needed to understand the practical implications and the factors that contribute to the superior performance of larger models in multilingual settings.
Furthermore, the study focuses on a limited set of LLMs and datasets. Expanding the evaluation to a broader range of models and datasets, including more diverse language families and modalities, could provide a more comprehensive understanding of the state of the art in multilingual LLM performance.
Conclusion
This study represents an important step in the ongoing efforts to understand the multilingual capabilities of large language models. The findings highlight the potential of more powerful LLMs to perform well on a wide range of languages, including low-resource ones. However, the issue of data contamination and the need for robust evaluation methods are crucial considerations for further advancing the field.
As LLMs continue to play an increasingly important role in diverse applications around the world, understanding their performance across languages is essential. This research contributes to this understanding and serves as a foundation for future work in this important area.
Related Papers

METAL: Towards Multilingual Meta-Evaluation
Rishav Hada, Varun Gumma, Mohamed Ahmed, Kalika Bali, Sunayana Sitaram
0
0
With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
4/3/2024
Benchmarking Large Language Models for Persian: A Preliminary Study Focusing on ChatGPT
Amirhossein Abaskohi, Sara Baruni, Mostafa Masoudi, Nesa Abbasi, Mohammad Hadi Babalou, Ali Edalat, Sepehr Kamahi, Samin Mahdizadeh Sani, Nikoo Naghavian, Danial Namazifard, Pouya Sadeghi, Yadollah Yaghoobzadeh
0
0
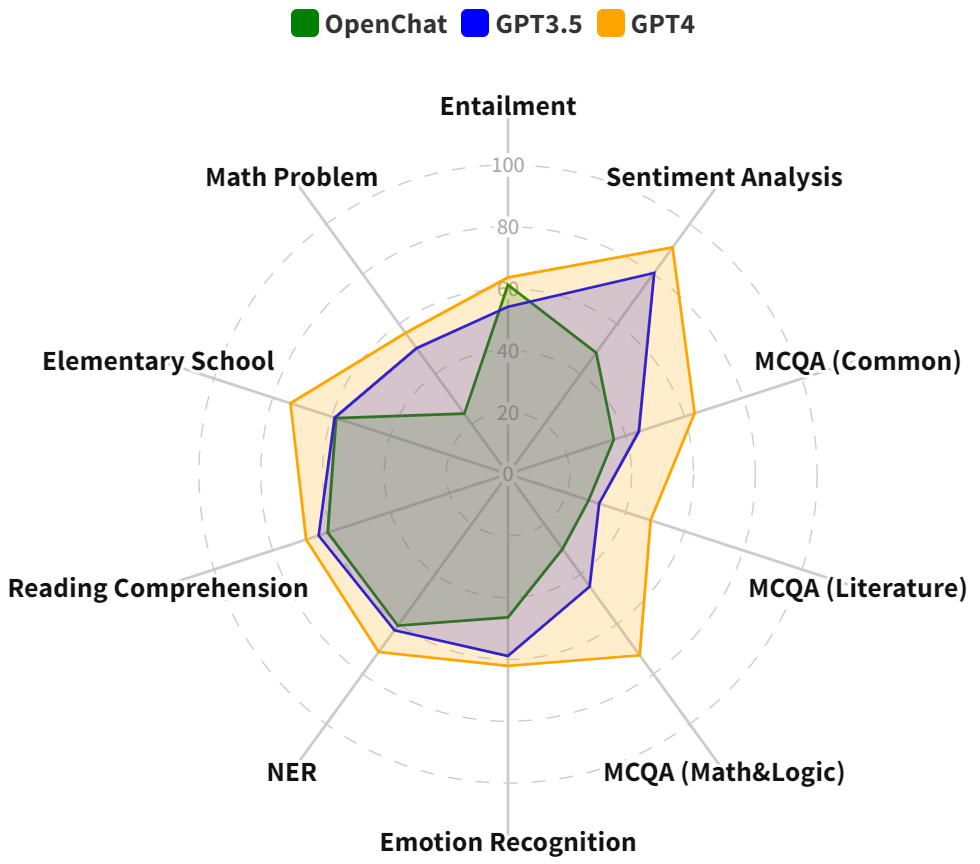
This paper explores the efficacy of large language models (LLMs) for Persian. While ChatGPT and consequent LLMs have shown remarkable performance in English, their efficiency for more low-resource languages remains an open question. We present the first comprehensive benchmarking study of LLMs across diverse Persian language tasks. Our primary focus is on GPT-3.5-turbo, but we also include GPT-4 and OpenChat-3.5 to provide a more holistic evaluation. Our assessment encompasses a diverse set of tasks categorized into classic, reasoning, and knowledge-based domains. To enable a thorough comparison, we evaluate LLMs against existing task-specific fine-tuned models. Given the limited availability of Persian datasets for reasoning tasks, we introduce two new benchmarks: one based on elementary school math questions and another derived from the entrance exams for 7th and 10th grades. Our findings reveal that while LLMs, especially GPT-4, excel in tasks requiring reasoning abilities and a broad understanding of general knowledge, they often lag behind smaller pre-trained models fine-tuned specifically for particular tasks. Additionally, we observe improved performance when test sets are translated to English before inputting them into GPT-3.5. These results highlight the significant potential for enhancing LLM performance in the Persian language. This is particularly noteworthy due to the unique attributes of Persian, including its distinct alphabet and writing styles.
4/4/2024
🛸
IndicGenBench: A Multilingual Benchmark to Evaluate Generation Capabilities of LLMs on Indic Languages
Harman Singh, Nitish Gupta, Shikhar Bharadwaj, Dinesh Tewari, Partha Talukdar
0
0
As large language models (LLMs) see increasing adoption across the globe, it is imperative for LLMs to be representative of the linguistic diversity of the world. India is a linguistically diverse country of 1.4 Billion people. To facilitate research on multilingual LLM evaluation, we release IndicGenBench - the largest benchmark for evaluating LLMs on user-facing generation tasks across a diverse set 29 of Indic languages covering 13 scripts and 4 language families. IndicGenBench is composed of diverse generation tasks like cross-lingual summarization, machine translation, and cross-lingual question answering. IndicGenBench extends existing benchmarks to many Indic languages through human curation providing multi-way parallel evaluation data for many under-represented Indic languages for the first time. We evaluate a wide range of proprietary and open-source LLMs including GPT-3.5, GPT-4, PaLM-2, mT5, Gemma, BLOOM and LLaMA on IndicGenBench in a variety of settings. The largest PaLM-2 models performs the best on most tasks, however, there is a significant performance gap in all languages compared to English showing that further research is needed for the development of more inclusive multilingual language models. IndicGenBench is released at www.github.com/google-research-datasets/indic-gen-bench
4/26/2024
💬
How good are Large Language Models on African Languages?
Jessica Ojo, Kelechi Ogueji, Pontus Stenetorp, David Ifeoluwa Adelani
0
0
Recent advancements in natural language processing have led to the proliferation of large language models (LLMs). These models have been shown to yield good performance, using in-context learning, even on tasks and languages they are not trained on. However, their performance on African languages is largely understudied relative to high-resource languages. We present an analysis of four popular large language models (mT0, Aya, LLaMa 2, and GPT-4) on six tasks (topic classification, sentiment classification, machine translation, summarization, question answering, and named entity recognition) across 60 African languages, spanning different language families and geographical regions. Our results suggest that all LLMs produce lower performance for African languages, and there is a large gap in performance compared to high-resource languages (such as English) for most tasks. We find that GPT-4 has an average to good performance on classification tasks, yet its performance on generative tasks such as machine translation and summarization is significantly lacking. Surprisingly, we find that mT0 had the best overall performance for cross-lingual QA, better than the state-of-the-art supervised model (i.e. fine-tuned mT5) and GPT-4 on African languages. Similarly, we find the recent Aya model to have comparable result to mT0 in almost all tasks except for topic classification where it outperform mT0. Overall, LLaMa 2 showed the worst performance, which we believe is due to its English and code-centric~(around 98%) pre-training corpus. Our findings confirms that performance on African languages continues to remain a hurdle for the current LLMs, underscoring the need for additional efforts to close this gap.
5/1/2024