Bidirectional Progressive Transformer for Interaction Intention Anticipation

0
📉
Sign in to get full access
Overview
- This paper introduces a novel deep learning model called Bidirectional prOgressive Transformer (BOT) for the task of interaction intention anticipation.
- The goal is to jointly predict future hand trajectories and interaction hotspots, which are regions where interactions are likely to occur.
- Existing approaches often treat these as separate tasks or only consider the impact of trajectories on hotspots, leading to accumulated prediction errors.
- The key innovation of BOT is a Bidirectional Progressive mechanism that allows for continuous mutual correction between the predictions of hand trajectories and interaction hotspots.
Plain English Explanation
The paper presents a new deep learning model called BOT that aims to forecast where a person's hands will move and where they are likely to interact with objects in the future. This is an important task for applications like human-robot interaction and egocentric activity recognition.
Traditionally, researchers have treated predicting hand trajectories and interaction hotspots as separate problems. However, these two aspects are actually closely connected - the paths of the hands influence where interactions will occur, and vice versa. BOT takes advantage of this inherent relationship to continuously improve both types of predictions over time, preventing errors from accumulating.
The model starts by using spatial information from the current video frame to get an initial estimate of the hand trajectories and interaction hotspots. Then, it repeatedly refines these predictions in a back-and-forth manner, with the trajectory forecasting and hotspot prediction modules mutually enhancing each other. This bidirectional progressive mechanism allows BOT to converge on more accurate anticipations of human interaction intentions.
Additionally, BOT introduces methods to account for the inherent randomness and uncertainty in human behavior, making the predictions more realistic and useful in real-world applications.
Technical Explanation
The key innovations in the BOT model are:
-
Spatial-Temporal Reconstruction Module: This module leverages the spatial information from the last observation frame to mitigate conflicts that can arise due to changes in camera viewpoint in first-person videos.
-
Bidirectional Progressive Enhancement Module: This module introduces a feedback loop between the hand trajectory forecasting and interaction hotspot prediction branches. The predictions from each branch are used to continuously refine the other, minimizing error accumulation over time.
-
Trajectory Stochastic Unit and C-VAE: These components introduce appropriate uncertainty into the predicted hand trajectories and interaction hotspots, respectively, to better capture the inherent randomness in human behavior.
The BOT model is evaluated on three benchmark datasets: Epic-Kitchens-100, EGO4D, and EGTEA Gaze+. The results demonstrate that BOT outperforms state-of-the-art methods, particularly in complex scenarios where the bidirectional progression mechanism provides significant advantages.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated approach to the important problem of interaction intention anticipation. The key strength of the BOT model is its ability to leverage the inherent connection between hand trajectories and interaction hotspots, allowing for continuous mutual refinement of the predictions.
However, the paper does not address certain limitations and potential concerns:
- The model's performance may be heavily dependent on the quality and diversity of the training data, as human interaction patterns can vary significantly across different contexts and cultural backgrounds.
- The computational complexity of the Bidirectional Progressive Enhancement Module may limit the model's real-time applicability, especially in resource-constrained environments.
- The paper does not explore the interpretability of the model's predictions, which could be crucial for understanding the reasoning behind the anticipations and building trust in the system.
Further research could investigate ways to address these limitations, such as exploring transfer learning techniques to improve the model's generalization, or developing more efficient architectures for the Bidirectional Progressive Enhancement Module.
Conclusion
The BOT model presented in this paper represents a significant advancement in the field of interaction intention anticipation. By introducing a Bidirectional Progressive mechanism that allows for continuous mutual correction between hand trajectory forecasting and interaction hotspot prediction, the model achieves state-of-the-art performance on several benchmark datasets.
This research has the potential to enable more natural and seamless human-robot interactions, as well as enhance the accuracy of egocentric activity recognition systems. As the field continues to evolve, addressing the identified limitations and exploring further improvements to the BOT model could lead to even more robust and reliable anticipation of human interaction intentions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
Bidirectional Progressive Transformer for Interaction Intention Anticipation
Zichen Zhang, Hongchen Luo, Wei Zhai, Yang Cao, Yu Kang
Interaction intention anticipation aims to jointly predict future hand trajectories and interaction hotspots. Existing research often treated trajectory forecasting and interaction hotspots prediction as separate tasks or solely considered the impact of trajectories on interaction hotspots, which led to the accumulation of prediction errors over time. However, a deeper inherent connection exists between hand trajectories and interaction hotspots, which allows for continuous mutual correction between them. Building upon this relationship, a novel Bidirectional prOgressive Transformer (BOT), which introduces a Bidirectional Progressive mechanism into the anticipation of interaction intention is established. Initially, BOT maximizes the utilization of spatial information from the last observation frame through the Spatial-Temporal Reconstruction Module, mitigating conflicts arising from changes of view in first-person videos. Subsequently, based on two independent prediction branches, a Bidirectional Progressive Enhancement Module is introduced to mutually improve the prediction of hand trajectories and interaction hotspots over time to minimize error accumulation. Finally, acknowledging the intrinsic randomness in human natural behavior, we employ a Trajectory Stochastic Unit and a C-VAE to introduce appropriate uncertainty to trajectories and interaction hotspots, respectively. Our method achieves state-of-the-art results on three benchmark datasets Epic-Kitchens-100, EGO4D, and EGTEA Gaze+, demonstrating superior in complex scenarios.
Read more5/10/2024
👀
0
HOI4ABOT: Human-Object Interaction Anticipation for Human Intention Reading Collaborative roBOTs
Esteve Valls Mascaro, Daniel Sliwowski, Dongheui Lee
Robots are becoming increasingly integrated into our lives, assisting us in various tasks. To ensure effective collaboration between humans and robots, it is essential that they understand our intentions and anticipate our actions. In this paper, we propose a Human-Object Interaction (HOI) anticipation framework for collaborative robots. We propose an efficient and robust transformer-based model to detect and anticipate HOIs from videos. This enhanced anticipation empowers robots to proactively assist humans, resulting in more efficient and intuitive collaborations. Our model outperforms state-of-the-art results in HOI detection and anticipation in VidHOI dataset with an increase of 1.76% and 1.04% in mAP respectively while being 15.4 times faster. We showcase the effectiveness of our approach through experimental results in a real robot, demonstrating that the robot's ability to anticipate HOIs is key for better Human-Robot Interaction. More information can be found on our project webpage: https://evm7.github.io/HOI4ABOT_page/
Read more4/9/2024

0
PEAR: Phrase-Based Hand-Object Interaction Anticipation
Zichen Zhang, Hongchen Luo, Wei Zhai, Yang Cao, Yu Kang
First-person hand-object interaction anticipation aims to predict the interaction process over a forthcoming period based on current scenes and prompts. This capability is crucial for embodied intelligence and human-robot collaboration. The complete interaction process involves both pre-contact interaction intention (i.e., hand motion trends and interaction hotspots) and post-contact interaction manipulation (i.e., manipulation trajectories and hand poses with contact). Existing research typically anticipates only interaction intention while neglecting manipulation, resulting in incomplete predictions and an increased likelihood of intention errors due to the lack of manipulation constraints. To address this, we propose a novel model, PEAR (Phrase-Based Hand-Object Interaction Anticipation), which jointly anticipates interaction intention and manipulation. To handle uncertainties in the interaction process, we employ a twofold approach. Firstly, we perform cross-alignment of verbs, nouns, and images to reduce the diversity of hand movement patterns and object functional attributes, thereby mitigating intention uncertainty. Secondly, we establish bidirectional constraints between intention and manipulation using dynamic integration and residual connections, ensuring consistency among elements and thus overcoming manipulation uncertainty. To rigorously evaluate the performance of the proposed model, we collect a new task-relevant dataset, EGO-HOIP, with comprehensive annotations. Extensive experimental results demonstrate the superiority of our method.
Read more8/1/2024
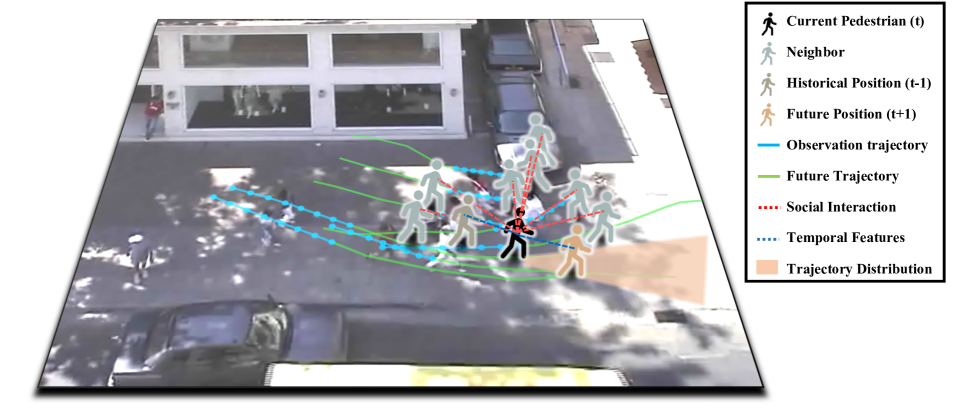
0
Attention-aware Social Graph Transformer Networks for Stochastic Trajectory Prediction
Yao Liu, Binghao Li, Xianzhi Wang, Claude Sammut, Lina Yao
Trajectory prediction is fundamental to various intelligent technologies, such as autonomous driving and robotics. The motion prediction of pedestrians and vehicles helps emergency braking, reduces collisions, and improves traffic safety. Current trajectory prediction research faces problems of complex social interactions, high dynamics and multi-modality. Especially, it still has limitations in long-time prediction. We propose Attention-aware Social Graph Transformer Networks for multi-modal trajectory prediction. We combine Graph Convolutional Networks and Transformer Networks by generating stable resolution pseudo-images from Spatio-temporal graphs through a designed stacking and interception method. Furthermore, we design the attention-aware module to handle social interaction information in scenarios involving mixed pedestrian-vehicle traffic. Thus, we maintain the advantages of the Graph and Transformer, i.e., the ability to aggregate information over an arbitrary number of neighbors and the ability to perform complex time-dependent data processing. We conduct experiments on datasets involving pedestrian, vehicle, and mixed trajectories, respectively. Our results demonstrate that our model minimizes displacement errors across various metrics and significantly reduces the likelihood of collisions. It is worth noting that our model effectively reduces the final displacement error, illustrating the ability of our model to predict for a long time.
Read more5/14/2024