Bifurcated Generative Flow Networks
2406.01901
0
0

Abstract
Generative Flow Networks (GFlowNets), a new family of probabilistic samplers, have recently emerged as a promising framework for learning stochastic policies that generate high-quality and diverse objects proportionally to their rewards. However, existing GFlowNets often suffer from low data efficiency due to the direct parameterization of edge flows or reliance on backward policies that may struggle to scale up to large action spaces. In this paper, we introduce Bifurcated GFlowNets (BN), a novel approach that employs a bifurcated architecture to factorize the flows into separate representations for state flows and edge-based flow allocation. This factorization enables BN to learn more efficiently from data and better handle large-scale problems while maintaining the convergence guarantee. Through extensive experiments on standard evaluation benchmarks, we demonstrate that BN significantly improves learning efficiency and effectiveness compared to strong baselines.
Create account to get full access
Overview
- This paper introduces a new type of generative model called Bifurcated Generative Flow Networks (BiGFlowNets)
- BiGFlowNets are an extension of GFlowNets, which are a class of generative models that learn to sample from a target distribution by learning a stochastic process
- The key innovation in BiGFlowNets is the use of a "bifurcated" network architecture that separates the forward and backward flows, allowing for more flexible and efficient learning
Plain English Explanation
Bifurcated Generative Flow Networks, or BiGFlowNets, are a new type of machine learning model that can generate samples from a desired distribution. They build on an existing approach called GFlowNets, which learn to simulate a stochastic process that produces the target samples.
The main idea behind BiGFlowNets is to split the network into two separate parts - one that handles the forward direction (generating samples) and one that handles the backward direction (learning from the samples). This "bifurcated" architecture allows the model to be more flexible and efficient in how it learns the target distribution, compared to the original GFlowNet design.
Imagine you're trying to learn how to bake a cake. With a regular GFlowNet, the model would have to learn the entire process - from gathering ingredients to mixing them to putting the cake in the oven. With a BiGFlowNet, the forward part would focus on learning how to actually bake the cake, while the backward part would specialize in figuring out the best way to get there, based on the final product.
This separation of concerns can make the learning process more stable and effective, especially for complex target distributions. The paper demonstrates the benefits of BiGFlowNets on several tasks, including optimizing molecular structures and generating high-quality images.
Technical Explanation
The core innovation in Bifurcated Generative Flow Networks (BiGFlowNets) is the use of a "bifurcated" network architecture that separates the forward and backward flows. This is an extension of the GFlowNet framework, which learns a stochastic process to sample from a target distribution.
In a standard GFlowNet, a single network is responsible for both the forward and backward dynamics of the sampling process. In contrast, BiGFlowNets use two distinct networks - one for the forward flow (generating samples) and one for the backward flow (learning from the samples). This bifurcated structure allows for more flexible and efficient learning, as the forward and backward networks can specialize in their respective tasks.
The forward network in a BiGFlowNet is responsible for defining the generative process, learning to produce samples from the target distribution. The backward network, on the other hand, learns to estimate the probability of each step in the generative process, which is used to update the forward network and ensure it converges to the desired distribution.
The paper presents several experiments demonstrating the benefits of the BiGFlowNet architecture. For example, the authors show improved performance on molecular optimization tasks compared to previous GFlowNet and other approaches. They also demonstrate the ability of BiGFlowNets to generate high-quality images, with results competitive with state-of-the-art generative models.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the BiGFlowNet approach, comparing it to relevant baselines and demonstrating its effectiveness on a range of tasks. However, there are a few potential limitations and areas for further research that are worth considering:
-
Computational Complexity: The use of two separate networks in the BiGFlowNet architecture may increase the overall computational complexity compared to a single-network GFlowNet. The authors do not provide a detailed analysis of the training and inference time requirements, which would be helpful for understanding the practical tradeoffs.
-
Hyperparameter Sensitivity: As with many deep learning models, BiGFlowNets may be sensitive to the choice of hyperparameters, such as learning rates, network architectures, and optimization settings. The paper does not explore the robustness of the approach to these choices, which could be an important consideration for real-world applications.
-
Interpretability: The bifurcated architecture of BiGFlowNets may make it more challenging to interpret the inner workings of the model and understand how it is learning the target distribution. Investigating ways to improve the interpretability of these models could be a valuable direction for future research.
-
Broader Applicability: While the paper demonstrates the effectiveness of BiGFlowNets on molecular optimization and image generation tasks, it would be interesting to see how the approach performs on a wider range of generative modeling problems, such as text generation, speech synthesis, or reinforcement learning.
Overall, the Bifurcated Generative Flow Networks presented in this paper represent an interesting and promising advancement in the field of generative modeling. The bifurcated architecture appears to offer tangible benefits, and the thorough experimental evaluation provides a strong foundation for further research and development in this area.
Conclusion
Bifurcated Generative Flow Networks (BiGFlowNets) are a novel extension of the GFlowNet framework, introducing a "bifurcated" network architecture that separates the forward and backward flows. This design allows for more flexible and efficient learning of complex target distributions, as demonstrated by the paper's results on molecular optimization and image generation tasks.
While the BiGFlowNet approach shows promise, there are still some potential limitations and areas for further research, such as computational complexity, hyperparameter sensitivity, interpretability, and broader applicability. Nonetheless, this work represents an important contribution to the field of generative modeling, and the insights gained from this research could inspire future advancements in areas like sample-efficient molecular optimization, goal-conditioned generation, and controllable generative models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Pessimistic Backward Policy for GFlowNets
Hyosoon Jang, Yunhui Jang, Minsu Kim, Jinkyoo Park, Sungsoo Ahn
0
0
This paper studies Generative Flow Networks (GFlowNets), which learn to sample objects proportionally to a given reward function through the trajectory of state transitions. In this work, we observe that GFlowNets tend to under-exploit the high-reward objects due to training on insufficient number of trajectories, which may lead to a large gap between the estimated flow and the (known) reward value. In response to this challenge, we propose a pessimistic backward policy for GFlowNets (PBP-GFN), which maximizes the observed flow to align closely with the true reward for the object. We extensively evaluate PBP-GFN across eight benchmarks, including hyper-grid environment, bag generation, structured set generation, molecular generation, and four RNA sequence generation tasks. In particular, PBP-GFN enhances the discovery of high-reward objects, maintains the diversity of the objects, and consistently outperforms existing methods.
5/28/2024

Embarrassingly Parallel GFlowNets
Tiago da Silva, Luiz Max Carvalho, Amauri Souza, Samuel Kaski, Diego Mesquita
0
0
GFlowNets are a promising alternative to MCMC sampling for discrete compositional random variables. Training GFlowNets requires repeated evaluations of the unnormalized target distribution or reward function. However, for large-scale posterior sampling, this may be prohibitive since it incurs traversing the data several times. Moreover, if the data are distributed across clients, employing standard GFlowNets leads to intensive client-server communication. To alleviate both these issues, we propose embarrassingly parallel GFlowNet (EP-GFlowNet). EP-GFlowNet is a provably correct divide-and-conquer method to sample from product distributions of the form $R(cdot) propto R_1(cdot) ... R_N(cdot)$ -- e.g., in parallel or federated Bayes, where each $R_n$ is a local posterior defined on a data partition. First, in parallel, we train a local GFlowNet targeting each $R_n$ and send the resulting models to the server. Then, the server learns a global GFlowNet by enforcing our newly proposed emph{aggregating balance} condition, requiring a single communication step. Importantly, EP-GFlowNets can also be applied to multi-objective optimization and model reuse. Our experiments illustrate the EP-GFlowNets's effectiveness on many tasks, including parallel Bayesian phylogenetics, multi-objective multiset, sequence generation, and federated Bayesian structure learning.
6/6/2024
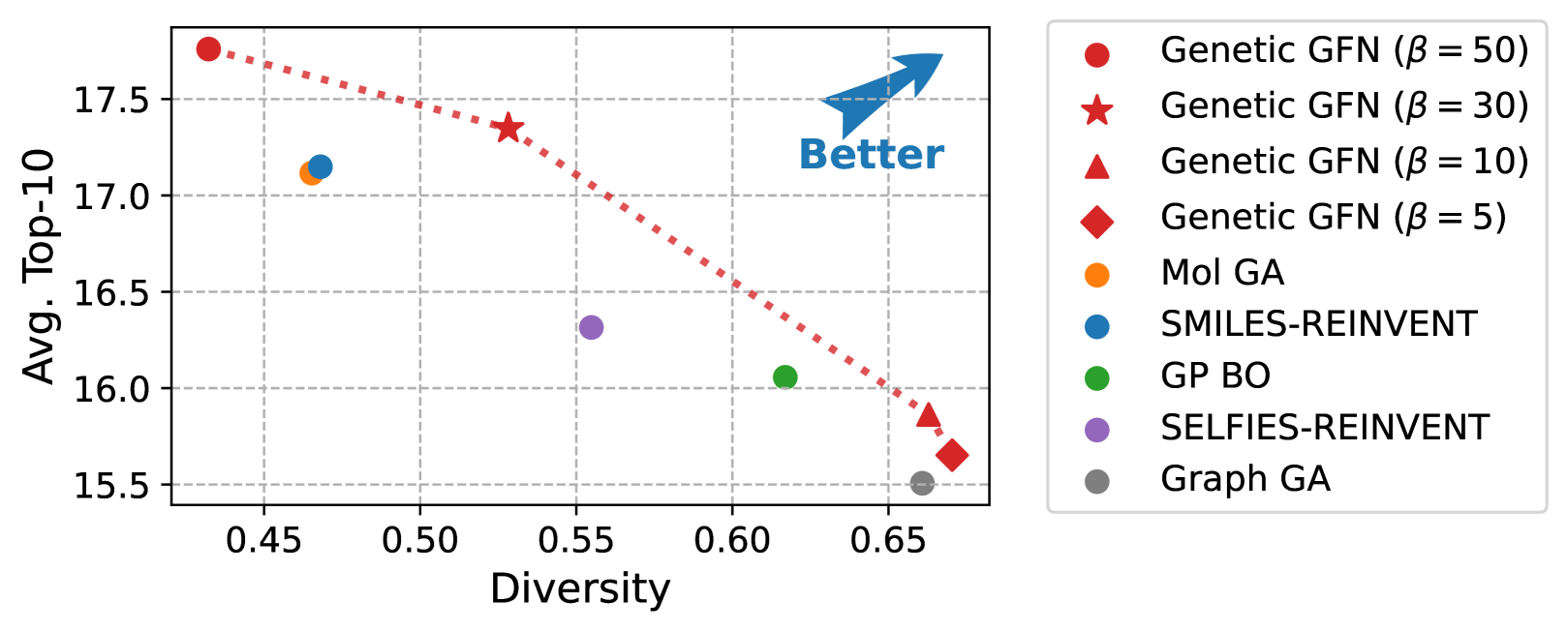
Genetic-guided GFlowNets for Sample Efficient Molecular Optimization
Hyeonah Kim, Minsu Kim, Sanghyeok Choi, Jinkyoo Park
0
0
The challenge of discovering new molecules with desired properties is crucial in domains like drug discovery and material design. Recent advances in deep learning-based generative methods have shown promise but face the issue of sample efficiency due to the computational expense of evaluating the reward function. This paper proposes a novel algorithm for sample-efficient molecular optimization by distilling a powerful genetic algorithm into deep generative policy using GFlowNets training, the off-policy method for amortized inference. This approach enables the deep generative policy to learn from domain knowledge, which has been explicitly integrated into the genetic algorithm. Our method achieves state-of-the-art performance in the official molecular optimization benchmark, significantly outperforming previous methods. It also demonstrates effectiveness in designing inhibitors against SARS-CoV-2 with substantially fewer reward calls.
5/28/2024
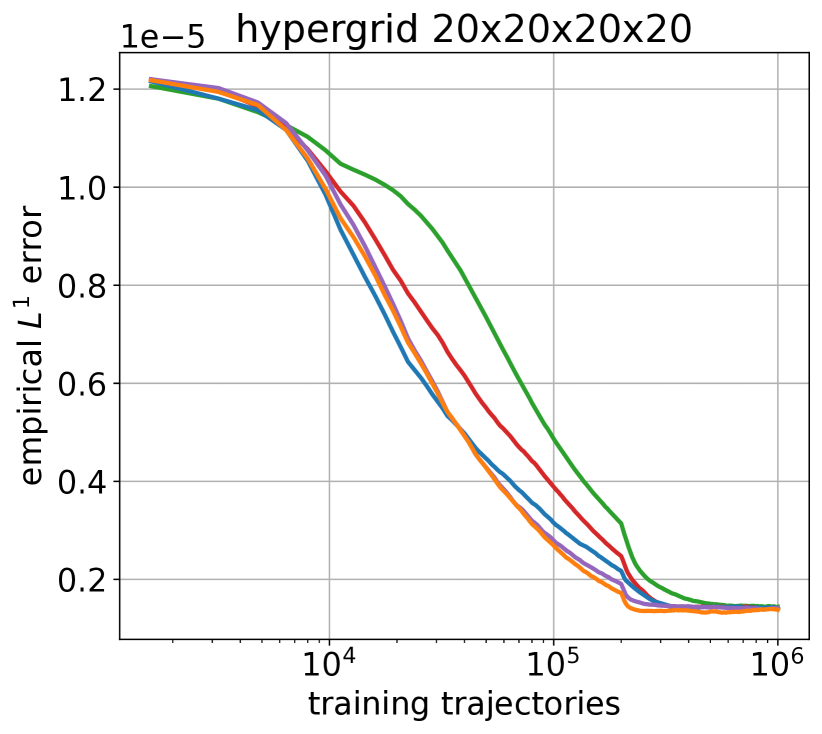
Improving GFlowNets with Monte Carlo Tree Search
Nikita Morozov, Daniil Tiapkin, Sergey Samsonov, Alexey Naumov, Dmitry Vetrov
0
0
Generative Flow Networks (GFlowNets) treat sampling from distributions over compositional discrete spaces as a sequential decision-making problem, training a stochastic policy to construct objects step by step. Recent studies have revealed strong connections between GFlowNets and entropy-regularized reinforcement learning. Building on these insights, we propose to enhance planning capabilities of GFlowNets by applying Monte Carlo Tree Search (MCTS). Specifically, we show how the MENTS algorithm (Xiao et al., 2019) can be adapted for GFlowNets and used during both training and inference. Our experiments demonstrate that this approach improves the sample efficiency of GFlowNet training and the generation fidelity of pre-trained GFlowNet models.
6/21/2024