Bilateral Sharpness-Aware Minimization for Flatter Minima

0
Sign in to get full access
Overview
- The paper proposes a new optimization method called Bilateral Sharpness-Aware Minimization (BiSAM) that aims to find flatter minima during training, leading to better generalization.
- BiSAM extends the existing Sharpness-Aware Minimization (SAM) technique by considering the sharpness in both the forward and backward directions.
- The authors demonstrate that BiSAM outperforms SAM and other baselines on various tasks, including image classification and language modeling.
Plain English Explanation
The paper introduces a new way of training machine learning models called Bilateral Sharpness-Aware Minimization (BiSAM). The key idea is to find "flatter" minima during the training process, which can lead to better generalization - the ability of the model to perform well on new, unseen data.
Traditionally, training methods have focused on minimizing the loss function, which measures how well the model is performing on the training data. However, this can sometimes lead to "sharp" minima - solutions that are very sensitive to small changes in the input. In contrast, flatter minima are more robust and can generalize better.
The BiSAM method builds on an existing technique called Sharpness-Aware Minimization (SAM), which explicitly considers the sharpness of the minima during training. BiSAM takes this a step further by looking at the sharpness in both the forward and backward directions, which the authors argue is a more comprehensive way to find flat minima.
Through experiments on various tasks, the authors show that BiSAM outperforms SAM and other baselines, demonstrating the benefits of this new approach to training machine learning models.
Technical Explanation
The paper introduces a new optimization method called Bilateral Sharpness-Aware Minimization (BiSAM), which extends the existing Sharpness-Aware Minimization (SAM) technique.
The key idea behind BiSAM is to explicitly consider the sharpness of the minima in both the forward and backward directions during the training process. Traditionally, training methods have focused on minimizing the loss function, which can sometimes lead to "sharp" minima - solutions that are very sensitive to small changes in the input. In contrast, flatter minima are more robust and can generalize better.
SAM addresses this issue by incorporating the sharpness of the minima into the optimization process. However, the authors argue that SAM only considers the sharpness in the forward direction, which may not fully capture the flatness of the solution. BiSAM extends SAM by also considering the sharpness in the backward direction, which the authors claim is a more comprehensive way to find flat minima.
The authors demonstrate the effectiveness of BiSAM through experiments on various tasks, including image classification and language modeling. They show that BiSAM outperforms SAM and other baselines, indicating the benefits of this new approach to training machine learning models.
Critical Analysis
The paper presents a novel optimization method, BiSAM, that aims to find flatter minima during training, leading to better generalization. The key contribution is the extension of SAM to consider the sharpness in both the forward and backward directions, which the authors argue is a more comprehensive way to find flat minima.
One potential limitation of the work is that the authors do not provide a thorough theoretical analysis of the properties of BiSAM, such as its convergence guarantees or the relationship between the sharpness in the forward and backward directions. A more rigorous theoretical understanding of the method could help further justify its advantages over existing approaches.
Additionally, the authors could have explored the sensitivity of BiSAM to hyperparameter choices, such as the penalty parameter for the sharpness term, and how these choices may impact the final performance. Investigating the robustness of the method to different hyperparameter settings would strengthen the claims about its effectiveness.
Furthermore, the authors could have compared BiSAM to a wider range of baselines, including other techniques for finding flatter minima, such as Improving SAM Requires Rethinking Its Optimization Formulation or Universal Class Sharpness-Aware Minimization Algorithms. A more comprehensive empirical evaluation could provide additional insights into the relative strengths and weaknesses of BiSAM.
Conclusion
The paper introduces a new optimization method called Bilateral Sharpness-Aware Minimization (BiSAM), which extends the existing Sharpness-Aware Minimization (SAM) technique. BiSAM aims to find flatter minima during the training process, leading to better generalization of the trained models.
The key innovation of BiSAM is the consideration of the sharpness in both the forward and backward directions, which the authors argue is a more comprehensive approach to finding flat minima. Through experiments on various tasks, the authors demonstrate that BiSAM outperforms SAM and other baselines, highlighting the benefits of this new approach to training machine learning models.
While the paper presents a promising new method, there are opportunities for further research, such as a more rigorous theoretical analysis, an investigation of the sensitivity to hyperparameter choices, and a more comprehensive empirical evaluation against a wider range of baselines. Nonetheless, the work contributes to the ongoing efforts to improve the generalization capabilities of machine learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Bilateral Sharpness-Aware Minimization for Flatter Minima
Jiaxin Deng, Junbiao Pang, Baochang Zhang, Qingming Huang
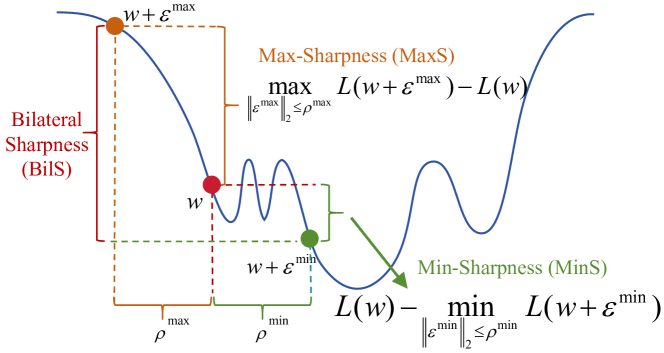
Sharpness-Aware Minimization (SAM) enhances generalization by reducing a Max-Sharpness (MaxS). Despite the practical success, we empirically found that the MAxS behind SAM's generalization enhancements face the Flatness Indicator Problem (FIP), where SAM only considers the flatness in the direction of gradient ascent, resulting in a next minimization region that is not sufficiently flat. A better Flatness Indicator (FI) would bring a better generalization of neural networks. Because SAM is a greedy search method in nature. In this paper, we propose to utilize the difference between the training loss and the minimum loss over the neighborhood surrounding the current weight, which we denote as Min-Sharpness (MinS). By merging MaxS and MinS, we created a better FI that indicates a flatter direction during the optimization. Specially, we combine this FI with SAM into the proposed Bilateral SAM (BSAM) which finds a more flatter minimum than that of SAM. The theoretical analysis proves that BSAM converges to local minima. Extensive experiments demonstrate that BSAM offers superior generalization performance and robustness compared to vanilla SAM across various tasks, i.e., classification, transfer learning, human pose estimation, and network quantization. Code is publicly available at: https://github.com/ajiaaa/BSAM.
Read more9/23/2024

0
Sharpness-Aware Minimization Enhances Feature Quality via Balanced Learning
Jacob Mitchell Springer, Vaishnavh Nagarajan, Aditi Raghunathan
Sharpness-Aware Minimization (SAM) has emerged as a promising alternative optimizer to stochastic gradient descent (SGD). The originally-proposed motivation behind SAM was to bias neural networks towards flatter minima that are believed to generalize better. However, recent studies have shown conflicting evidence on the relationship between flatness and generalization, suggesting that flatness does fully explain SAM's success. Sidestepping this debate, we identify an orthogonal effect of SAM that is beneficial out-of-distribution: we argue that SAM implicitly balances the quality of diverse features. SAM achieves this effect by adaptively suppressing well-learned features which gives remaining features opportunity to be learned. We show that this mechanism is beneficial in datasets that contain redundant or spurious features where SGD falls for the simplicity bias and would not otherwise learn all available features. Our insights are supported by experiments on real data: we demonstrate that SAM improves the quality of features in datasets containing redundant or spurious features, including CelebA, Waterbirds, CIFAR-MNIST, and DomainBed.
Read more6/3/2024

0
Improving SAM Requires Rethinking its Optimization Formulation
Wanyun Xie, Fabian Latorre, Kimon Antonakopoulos, Thomas Pethick, Volkan Cevher
This paper rethinks Sharpness-Aware Minimization (SAM), which is originally formulated as a zero-sum game where the weights of a network and a bounded perturbation try to minimize/maximize, respectively, the same differentiable loss. To fundamentally improve this design, we argue that SAM should instead be reformulated using the 0-1 loss. As a continuous relaxation, we follow the simple conventional approach where the minimizing (maximizing) player uses an upper bound (lower bound) surrogate to the 0-1 loss. This leads to a novel formulation of SAM as a bilevel optimization problem, dubbed as BiSAM. BiSAM with newly designed lower-bound surrogate loss indeed constructs stronger perturbation. Through numerical evidence, we show that BiSAM consistently results in improved performance when compared to the original SAM and variants, while enjoying similar computational complexity. Our code is available at https://github.com/LIONS-EPFL/BiSAM.
Read more7/19/2024

0
A Universal Class of Sharpness-Aware Minimization Algorithms
Behrooz Tahmasebi, Ashkan Soleymani, Dara Bahri, Stefanie Jegelka, Patrick Jaillet
Recently, there has been a surge in interest in developing optimization algorithms for overparameterized models as achieving generalization is believed to require algorithms with suitable biases. This interest centers on minimizing sharpness of the original loss function; the Sharpness-Aware Minimization (SAM) algorithm has proven effective. However, most literature only considers a few sharpness measures, such as the maximum eigenvalue or trace of the training loss Hessian, which may not yield meaningful insights for non-convex optimization scenarios like neural networks. Additionally, many sharpness measures are sensitive to parameter invariances in neural networks, magnifying significantly under rescaling parameters. Motivated by these challenges, we introduce a new class of sharpness measures in this paper, leading to new sharpness-aware objective functions. We prove that these measures are textit{universally expressive}, allowing any function of the training loss Hessian matrix to be represented by appropriate hyperparameters. Furthermore, we show that the proposed objective functions explicitly bias towards minimizing their corresponding sharpness measures, and how they allow meaningful applications to models with parameter invariances (such as scale-invariances). Finally, as instances of our proposed general framework, we present textit{Frob-SAM} and textit{Det-SAM}, which are specifically designed to minimize the Frobenius norm and the determinant of the Hessian of the training loss, respectively. We also demonstrate the advantages of our general framework through extensive experiments.
Read more6/11/2024