The Binary Quantized Neural Network for Dense Prediction via Specially Designed Upsampling and Attention
2405.17776
0
0
🧠
Abstract
Deep learning-based information processing consumes long time and requires huge computing resources, especially for dense prediction tasks which require an output for each pixel, like semantic segmentation and salient object detection. There are mainly two challenges for quantization of dense prediction tasks. Firstly, directly applying the upsampling operation that dense prediction tasks require is extremely crude and causes unacceptable accuracy reduction. Secondly, the complex structure of dense prediction networks means it is difficult to maintain a fast speed as well as a high accuracy when performing quantization. In this paper, we propose an effective upsampling method and an efficient attention computation strategy to transfer the success of the binary neural networks (BNN) from single prediction tasks to dense prediction tasks. Firstly, we design a simple and robust multi-branch parallel upsampling structure to achieve the high accuracy. Then we further optimize the attention method which plays an important role in segmentation but has huge computation complexity. Our attention method can reduce the computational complexity by a factor of one hundred times but retain the original effect. Experiments on Cityscapes, KITTI road, and ECSSD fully show the effectiveness of our work.
Create account to get full access
Overview
- This blog post provides a plain English summary and technical explanation of a research paper on efficient multitask dense prediction and related topics.
- The paper explores techniques for improving the efficiency and performance of deep learning models, particularly in areas like image segmentation and high-resolution generation.
- Key topics covered include binarization, quantization, and downsampling approaches to enable more compact and computationally efficient models.
Plain English Explanation
The research paper discusses ways to make deep learning models more efficient and accurate, especially for tasks like image segmentation and high-resolution image generation. Deep learning models can be very powerful, but they also require a lot of computing power and memory. The researchers explored techniques like binarization, quantization, and downsampling to create more compact and efficient models without sacrificing too much performance.
Binarization involves converting the weights and activations of a neural network to just 0s and 1s, rather than the full range of floating-point numbers. This can significantly reduce the model size and computational requirements. Quantization is a similar approach that reduces the precision of the model parameters to save space and speed up computations.
The researchers also explored techniques for multitask dense prediction, where a single model is trained to perform multiple related tasks, like image classification and segmentation. This can lead to more efficient models that can handle a variety of tasks.
Overall, the goal of this research is to make deep learning models more practical and accessible, by reducing their resource requirements without compromising their accuracy and capabilities too much. This could enable the deployment of advanced AI systems on a wider range of hardware, from mobile devices to edge computing platforms.
Technical Explanation
The paper presents several techniques for improving the efficiency of deep learning models, particularly in the context of multitask dense prediction problems.
One key approach is binarization, where the weights and activations of the neural network are converted to just 0s and 1s. This can significantly reduce the model size and computational requirements, making it more suitable for deployment on resource-constrained hardware. The researchers explore different binarization strategies and their impact on model performance.
Another technique explored is quantization, where the precision of the model parameters is reduced to save space and speed up computations. The paper investigates the interplay between quantization and other hardware-aware optimization techniques.
The researchers also present an efficient multitask dense predictor that can perform multiple related tasks, such as image classification and segmentation, using a single model. This can lead to more compact and efficient models that can handle a variety of tasks.
Additionally, the paper explores token downsampling as a way to enable efficient generation of high-resolution images. By strategically downsampling the input tokens, the model can produce higher-quality outputs without excessive computational requirements.
Throughout the paper, the researchers conduct extensive experiments to evaluate the performance and efficiency of their proposed techniques, comparing them to state-of-the-art approaches on various benchmark datasets.
Critical Analysis
The research presented in this paper offers valuable insights and techniques for improving the efficiency of deep learning models. The binarization and quantization approaches demonstrated can significantly reduce model size and computational requirements, which is crucial for deploying advanced AI systems on resource-constrained hardware.
However, the paper acknowledges that these efficiency-enhancing techniques can come with some trade-offs in terms of model performance. The researchers carefully analyze the impact of their proposed methods on task-specific metrics, ensuring that the efficiency gains do not come at the expense of unacceptable accuracy or quality degradation.
One potential area for further research could be exploring how these efficiency-focused techniques interact with other model architectures or training strategies. Additionally, the researchers could investigate the generalization of their findings to a broader range of tasks and domains, beyond the specific applications covered in this paper.
It would also be interesting to see the researchers address any potential limitations or edge cases of their approaches, as well as discuss potential societal implications or ethical considerations related to the deployment of highly efficient, yet powerful, deep learning models.
Conclusion
This research paper presents a range of techniques for improving the efficiency of deep learning models, including binarization, quantization, and multitask dense prediction. These approaches aim to create more compact and computationally efficient models without sacrificing too much performance, enabling the deployment of advanced AI systems on a wider range of hardware platforms.
The findings of this paper have the potential to significantly impact the field of deep learning, especially in areas where resource constraints are a major concern, such as mobile and edge computing applications. By making deep learning models more efficient, the researchers are paving the way for more widespread adoption and real-world impact of these powerful AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
Efficient Multitask Dense Predictor via Binarization
Yuzhang Shang, Dan Xu, Gaowen Liu, Ramana Rao Kompella, Yan Yan
0
0
Multi-task learning for dense prediction has emerged as a pivotal area in computer vision, enabling simultaneous processing of diverse yet interrelated pixel-wise prediction tasks. However, the substantial computational demands of state-of-the-art (SoTA) models often limit their widespread deployment. This paper addresses this challenge by introducing network binarization to compress resource-intensive multi-task dense predictors. Specifically, our goal is to significantly accelerate multi-task dense prediction models via Binary Neural Networks (BNNs) while maintaining and even improving model performance at the same time. To reach this goal, we propose a Binary Multi-task Dense Predictor, Bi-MTDP, and several variants of Bi-MTDP, in which a multi-task dense predictor is constructed via specified binarized modules. Our systematical analysis of this predictor reveals that performance drop from binarization is primarily caused by severe information degradation. To address this issue, we introduce a deep information bottleneck layer that enforces representations for downstream tasks satisfying Gaussian distribution in forward propagation. Moreover, we introduce a knowledge distillation mechanism to correct the direction of information flow in backward propagation. Intriguingly, one variant of Bi-MTDP outperforms full-precision (FP) multi-task dense prediction SoTAs, ARTC (CNN-based) and InvPT (ViT-Based). This result indicates that Bi-MTDP is not merely a naive trade-off between performance and efficiency, but is rather a benefit of the redundant information flow thanks to the multi-task architecture. Code is available at https://github.com/42Shawn/BiMTDP.
5/24/2024
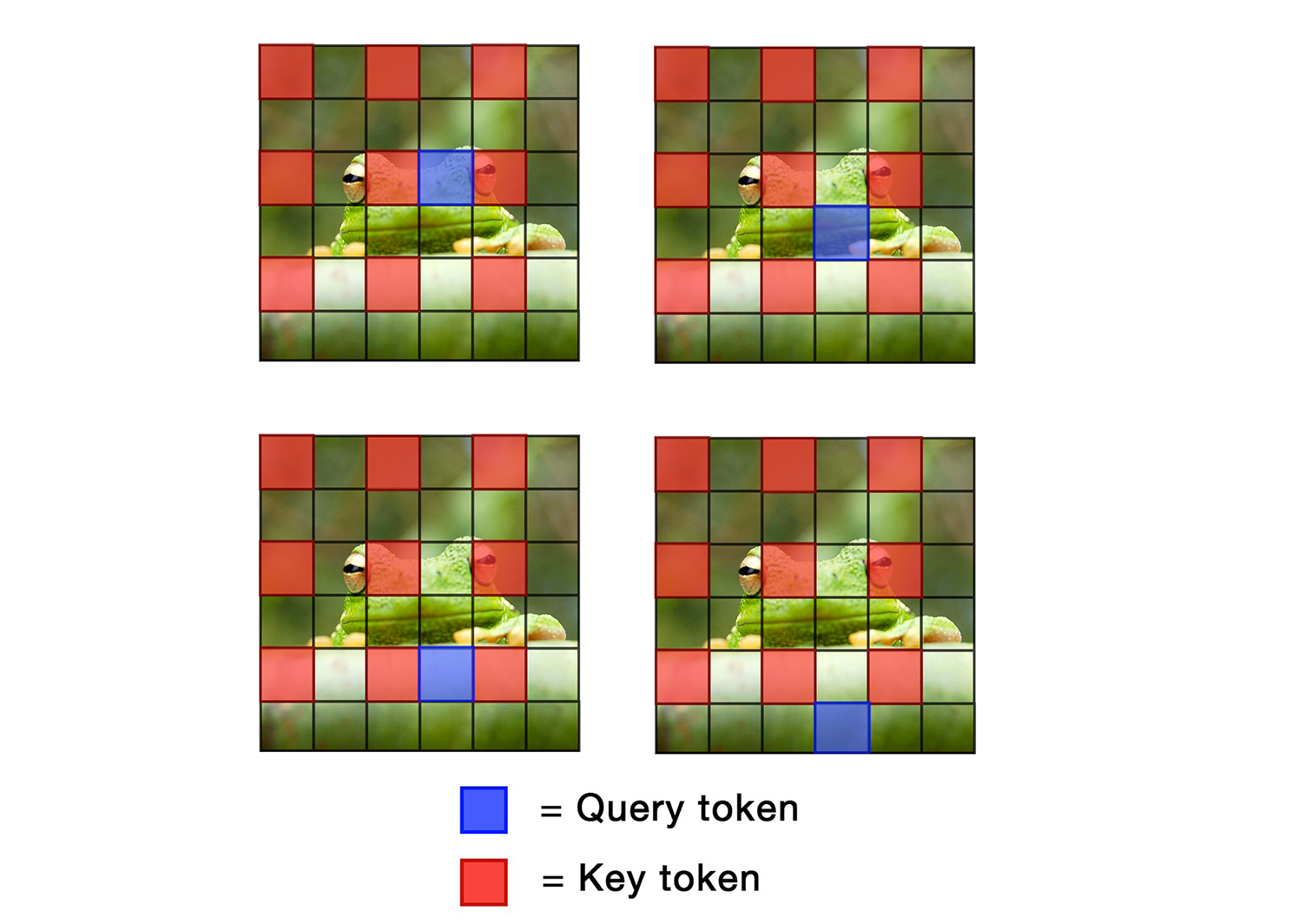
ToDo: Token Downsampling for Efficient Generation of High-Resolution Images
Ethan Smith, Nayan Saxena, Aninda Saha
0
0
Attention mechanism has been crucial for image diffusion models, however, their quadratic computational complexity limits the sizes of images we can process within reasonable time and memory constraints. This paper investigates the importance of dense attention in generative image models, which often contain redundant features, making them suitable for sparser attention mechanisms. We propose a novel training-free method ToDo that relies on token downsampling of key and value tokens to accelerate Stable Diffusion inference by up to 2x for common sizes and up to 4.5x or more for high resolutions like 2048x2048. We demonstrate that our approach outperforms previous methods in balancing efficient throughput and fidelity.
5/9/2024

New!Joint Pruning and Channel-wise Mixed-Precision Quantization for Efficient Deep Neural Networks
Beatrice Alessandra Motetti, Matteo Risso, Alessio Burrello, Enrico Macii, Massimo Poncino, Daniele Jahier Pagliari
0
0
The resource requirements of deep neural networks (DNNs) pose significant challenges to their deployment on edge devices. Common approaches to address this issue are pruning and mixed-precision quantization, which lead to latency and memory occupation improvements. These optimization techniques are usually applied independently. We propose a novel methodology to apply them jointly via a lightweight gradient-based search, and in a hardware-aware manner, greatly reducing the time required to generate Pareto-optimal DNNs in terms of accuracy versus cost (i.e., latency or memory). We test our approach on three edge-relevant benchmarks, namely CIFAR-10, Google Speech Commands, and Tiny ImageNet. When targeting the optimization of the memory footprint, we are able to achieve a size reduction of 47.50% and 69.54% at iso-accuracy with the baseline networks with all weights quantized at 8 and 2-bit, respectively. Our method surpasses a previous state-of-the-art approach with up to 56.17% size reduction at iso-accuracy. With respect to the sequential application of state-of-the-art pruning and mixed-precision optimizations, we obtain comparable or superior results, but with a significantly lowered training time. In addition, we show how well-tailored cost models can improve the cost versus accuracy trade-offs when targeting specific hardware for deployment.
7/2/2024
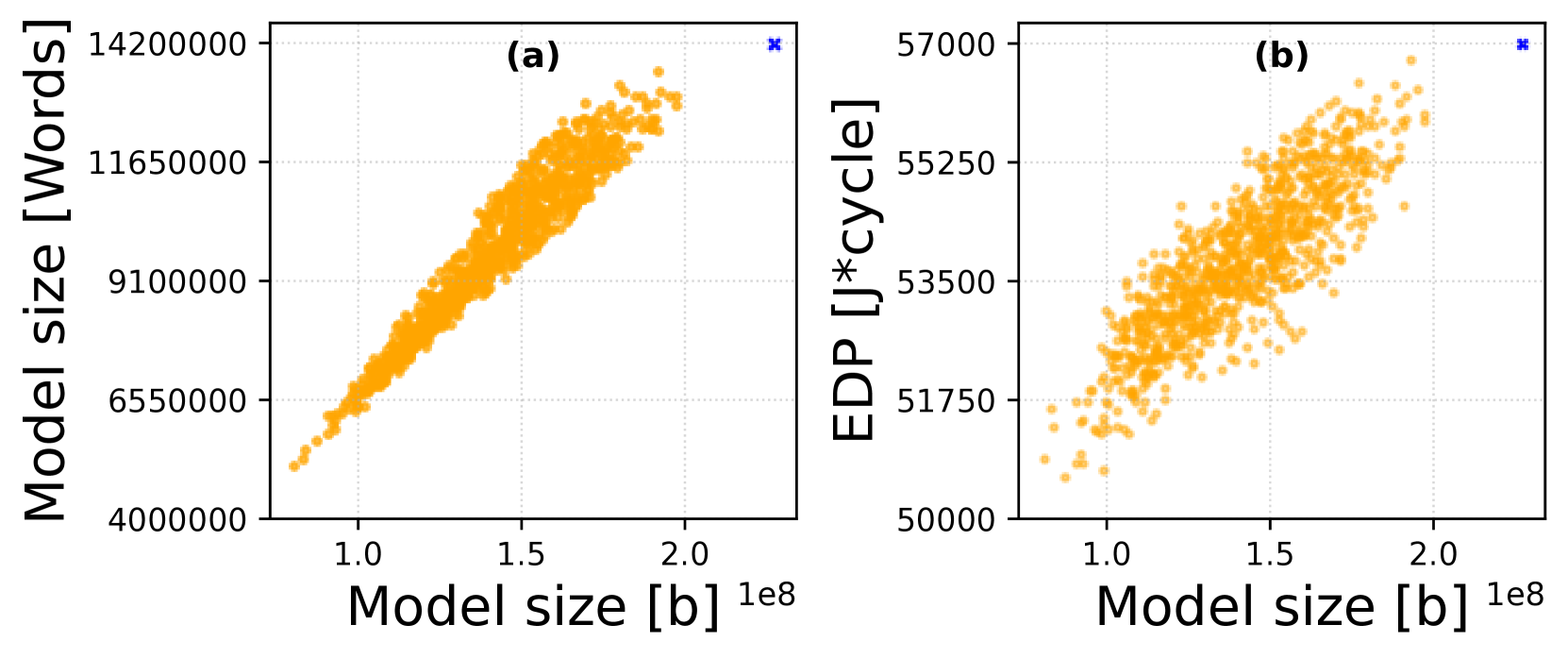
Exploring Quantization and Mapping Synergy in Hardware-Aware Deep Neural Network Accelerators
Jan Klhufek, Miroslav Safar, Vojtech Mrazek, Zdenek Vasicek, Lukas Sekanina
0
0
Energy efficiency and memory footprint of a convolutional neural network (CNN) implemented on a CNN inference accelerator depend on many factors, including a weight quantization strategy (i.e., data types and bit-widths) and mapping (i.e., placement and scheduling of DNN elementary operations on hardware units of the accelerator). We show that enabling rich mixed quantization schemes during the implementation can open a previously hidden space of mappings that utilize the hardware resources more effectively. CNNs utilizing quantized weights and activations and suitable mappings can significantly improve trade-offs among the accuracy, energy, and memory requirements compared to less carefully optimized CNN implementations. To find, analyze, and exploit these mappings, we: (i) extend a general-purpose state-of-the-art mapping tool (Timeloop) to support mixed quantization, which is not currently available; (ii) propose an efficient multi-objective optimization algorithm to find the most suitable bit-widths and mapping for each DNN layer executed on the accelerator; and (iii) conduct a detailed experimental evaluation to validate the proposed method. On two CNNs (MobileNetV1 and MobileNetV2) and two accelerators (Eyeriss and Simba) we show that for a given quality metric (such as the accuracy on ImageNet), energy savings are up to 37% without any accuracy drop.
4/9/2024