ToDo: Token Downsampling for Efficient Generation of High-Resolution Images
2402.13573
0
0
Abstract
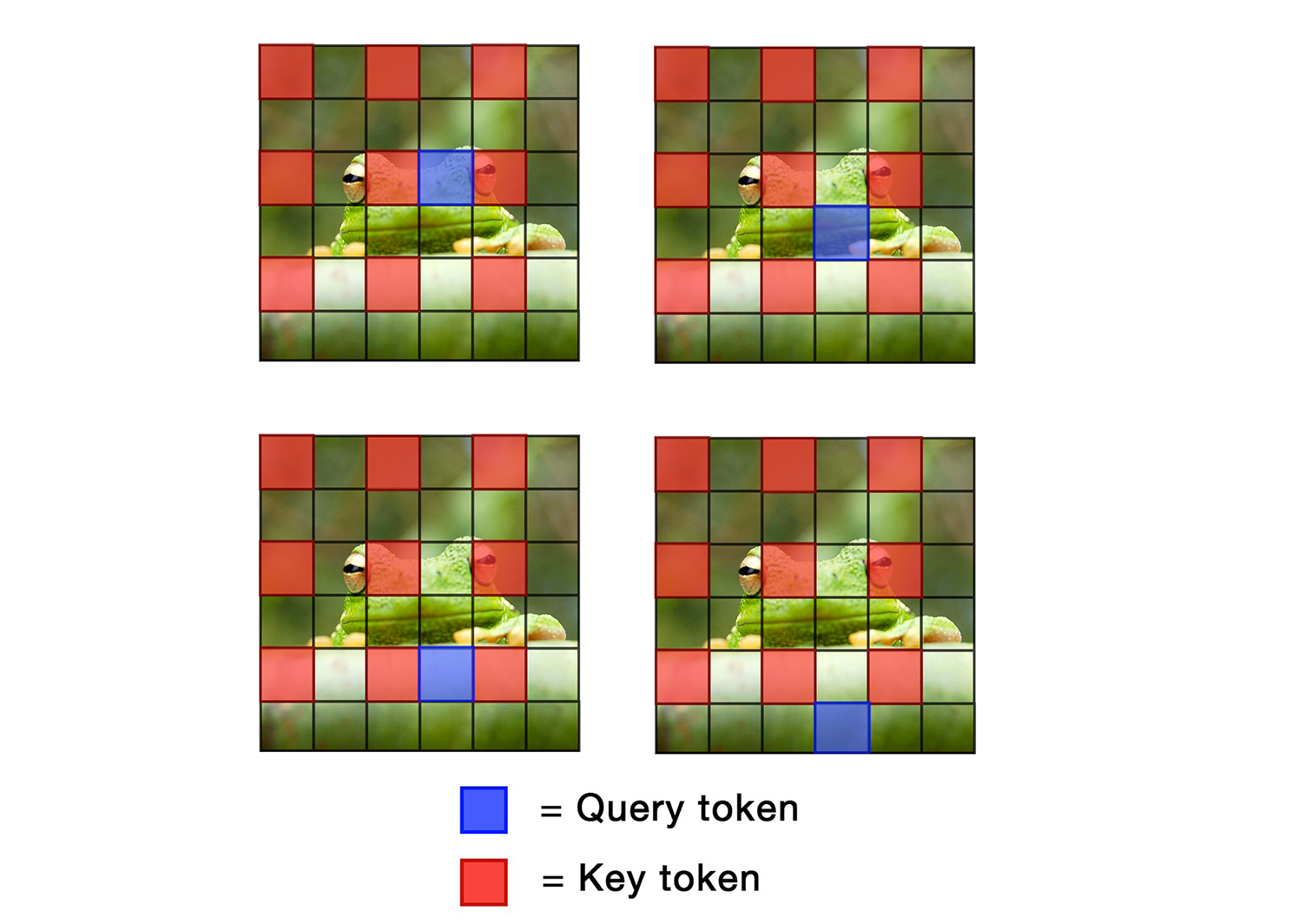
Attention mechanism has been crucial for image diffusion models, however, their quadratic computational complexity limits the sizes of images we can process within reasonable time and memory constraints. This paper investigates the importance of dense attention in generative image models, which often contain redundant features, making them suitable for sparser attention mechanisms. We propose a novel training-free method ToDo that relies on token downsampling of key and value tokens to accelerate Stable Diffusion inference by up to 2x for common sizes and up to 4.5x or more for high resolutions like 2048x2048. We demonstrate that our approach outperforms previous methods in balancing efficient throughput and fidelity.
Create account to get full access
Overview
- This paper proposes a novel token downsampling method for efficient generation of high-resolution images using diffusion models.
- The method, called U-DITs, aims to address the computational complexity and memory requirements of generating high-resolution images with diffusion models.
- The authors demonstrate the effectiveness of U-DITs on various diffusion model architectures, showing significant improvements in generation speed and memory usage compared to previous approaches.
Plain English Explanation
Diffusion models are a powerful type of machine learning algorithm that can generate high-quality images. However, generating high-resolution images with these models can be computationally complex and memory-intensive. This paper introduces a new technique called U-DITs that helps make the process more efficient.
The key idea behind U-DITs is to "downsample" or reduce the number of data points (called "tokens") that the diffusion model needs to process, especially in the earlier stages of the generation process. By doing this, the model can generate high-resolution images more quickly and with less memory usage.
The authors show that U-DITs can be applied to different types of diffusion models, and it consistently leads to significant improvements in generation speed and memory efficiency. This is an important advancement, as it can make high-resolution image generation more practical and accessible, with potential applications in areas like digital art, product visualization, and scientific imaging.
Technical Explanation
The paper introduces a novel token downsampling method called U-DITs to improve the efficiency of high-resolution image generation with diffusion models. Diffusion models work by gradually adding noise to an image and then learning to reverse the process to generate new images. However, this process can be computationally complex and memory-intensive, especially for high-resolution outputs.
U-DITs addresses this challenge by selectively downsampling the image tokens, reducing the number of tokens the model needs to process, particularly in the early stages of the diffusion process. The authors propose a U-shaped downsampling and upsampling strategy that maintains important spatial information while significantly reducing the computational and memory requirements.
The authors evaluate U-DITs on several diffusion model architectures, including Attention-Driven Training-Free Efficiency Enhancement, INF-DIT Upsampling, and Upsampling Guidance. The results demonstrate that U-DITs can achieve substantial speedups and memory savings without compromising image quality, making high-resolution image generation more practical and accessible.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the U-DITs method, with experiments showcasing its effectiveness across multiple diffusion model architectures. The authors acknowledge the limitations of their approach, noting that while U-DITs can significantly improve efficiency, it may not be as effective for certain types of high-frequency image content.
One potential area for further research could be exploring the impact of U-DITs on the quality and fidelity of generated images, particularly for applications where high-resolution details are critical. Additionally, investigating the interaction between U-DITs and other efficiency-enhancing techniques, such as Perturbing Attention, could lead to even greater gains in performance.
Overall, the U-DITs method presented in this paper represents an important advancement in making high-resolution image generation with diffusion models more practical and accessible. The authors have made a valuable contribution to the field, and the ideas and insights presented in the paper are likely to inspire further research and development in this area.
Conclusion
This paper introduces a novel token downsampling method called U-DITs that significantly improves the efficiency of high-resolution image generation with diffusion models. By selectively reducing the number of tokens the model needs to process, especially in the early stages of the diffusion process, U-DITs can achieve substantial speedups and memory savings without compromising image quality.
The authors demonstrate the effectiveness of U-DITs across multiple diffusion model architectures, showcasing its potential to make high-resolution image generation more practical and accessible. This work represents an important advancement in the field, and the insights and techniques presented in the paper are likely to inspire further research and development in this area, with potential applications in digital art, product visualization, scientific imaging, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

An Image is Worth 32 Tokens for Reconstruction and Generation
Qihang Yu, Mark Weber, Xueqing Deng, Xiaohui Shen, Daniel Cremers, Liang-Chieh Chen
0
0
Recent advancements in generative models have highlighted the crucial role of image tokenization in the efficient synthesis of high-resolution images. Tokenization, which transforms images into latent representations, reduces computational demands compared to directly processing pixels and enhances the effectiveness and efficiency of the generation process. Prior methods, such as VQGAN, typically utilize 2D latent grids with fixed downsampling factors. However, these 2D tokenizations face challenges in managing the inherent redundancies present in images, where adjacent regions frequently display similarities. To overcome this issue, we introduce Transformer-based 1-Dimensional Tokenizer (TiTok), an innovative approach that tokenizes images into 1D latent sequences. TiTok provides a more compact latent representation, yielding substantially more efficient and effective representations than conventional techniques. For example, a 256 x 256 x 3 image can be reduced to just 32 discrete tokens, a significant reduction from the 256 or 1024 tokens obtained by prior methods. Despite its compact nature, TiTok achieves competitive performance to state-of-the-art approaches. Specifically, using the same generator framework, TiTok attains 1.97 gFID, outperforming MaskGIT baseline significantly by 4.21 at ImageNet 256 x 256 benchmark. The advantages of TiTok become even more significant when it comes to higher resolution. At ImageNet 512 x 512 benchmark, TiTok not only outperforms state-of-the-art diffusion model DiT-XL/2 (gFID 2.74 vs. 3.04), but also reduces the image tokens by 64x, leading to 410x faster generation process. Our best-performing variant can significantly surpasses DiT-XL/2 (gFID 2.13 vs. 3.04) while still generating high-quality samples 74x faster.
6/12/2024

Fast Sampling Through The Reuse Of Attention Maps In Diffusion Models
Rosco Hunter, {L}ukasz Dudziak, Mohamed S. Abdelfattah, Abhinav Mehrotra, Sourav Bhattacharya, Hongkai Wen
0
0
Text-to-image diffusion models have demonstrated unprecedented capabilities for flexible and realistic image synthesis. Nevertheless, these models rely on a time-consuming sampling procedure, which has motivated attempts to reduce their latency. When improving efficiency, researchers often use the original diffusion model to train an additional network designed specifically for fast image generation. In contrast, our approach seeks to reduce latency directly, without any retraining, fine-tuning, or knowledge distillation. In particular, we find the repeated calculation of attention maps to be costly yet redundant, and instead suggest reusing them during sampling. Our specific reuse strategies are based on ODE theory, which implies that the later a map is reused, the smaller the distortion in the final image. We empirically compare these reuse strategies with few-step sampling procedures of comparable latency, finding that reuse generates images that are closer to those produced by the original high-latency diffusion model.
5/27/2024
🧠
The Binary Quantized Neural Network for Dense Prediction via Specially Designed Upsampling and Attention
Xingyu Ding, Lianlei Shan, Guiqin Zhao, Meiqi Wu, Wenzhang Zhou, Wei Li
0
0
Deep learning-based information processing consumes long time and requires huge computing resources, especially for dense prediction tasks which require an output for each pixel, like semantic segmentation and salient object detection. There are mainly two challenges for quantization of dense prediction tasks. Firstly, directly applying the upsampling operation that dense prediction tasks require is extremely crude and causes unacceptable accuracy reduction. Secondly, the complex structure of dense prediction networks means it is difficult to maintain a fast speed as well as a high accuracy when performing quantization. In this paper, we propose an effective upsampling method and an efficient attention computation strategy to transfer the success of the binary neural networks (BNN) from single prediction tasks to dense prediction tasks. Firstly, we design a simple and robust multi-branch parallel upsampling structure to achieve the high accuracy. Then we further optimize the attention method which plays an important role in segmentation but has huge computation complexity. Our attention method can reduce the computational complexity by a factor of one hundred times but retain the original effect. Experiments on Cityscapes, KITTI road, and ECSSD fully show the effectiveness of our work.
5/29/2024
🛸
Attention-Driven Training-Free Efficiency Enhancement of Diffusion Models
Hongjie Wang, Difan Liu, Yan Kang, Yijun Li, Zhe Lin, Niraj K. Jha, Yuchen Liu
0
0
Diffusion Models (DMs) have exhibited superior performance in generating high-quality and diverse images. However, this exceptional performance comes at the cost of expensive architectural design, particularly due to the attention module heavily used in leading models. Existing works mainly adopt a retraining process to enhance DM efficiency. This is computationally expensive and not very scalable. To this end, we introduce the Attention-driven Training-free Efficient Diffusion Model (AT-EDM) framework that leverages attention maps to perform run-time pruning of redundant tokens, without the need for any retraining. Specifically, for single-denoising-step pruning, we develop a novel ranking algorithm, Generalized Weighted Page Rank (G-WPR), to identify redundant tokens, and a similarity-based recovery method to restore tokens for the convolution operation. In addition, we propose a Denoising-Steps-Aware Pruning (DSAP) approach to adjust the pruning budget across different denoising timesteps for better generation quality. Extensive evaluations show that AT-EDM performs favorably against prior art in terms of efficiency (e.g., 38.8% FLOPs saving and up to 1.53x speed-up over Stable Diffusion XL) while maintaining nearly the same FID and CLIP scores as the full model. Project webpage: https://atedm.github.io.
5/9/2024