BINDy -- Bayesian identification of nonlinear dynamics with reversible-jump Markov-chain Monte-Carlo

0

Sign in to get full access
Overview
- The paper presents a Bayesian method called BINDy (Bayesian Identification of Nonlinear Dynamics) for identifying nonlinear dynamical systems from observed data.
- BINDy uses a reversible-jump Markov-chain Monte-Carlo (RJMCMC) algorithm to explore different model structures and parameter values.
- This allows the method to automatically determine the appropriate model complexity without requiring the user to specify it in advance.
Plain English Explanation
BINDy is a way to figure out the mathematical equations that describe a dynamic system, like how the temperature or population of something changes over time. It takes in data about how the system behaves and uses a statistical technique called Bayesian inference to find the best model to explain that data.
The key innovation in BINDy is that it doesn't require you to know the complexity of the model ahead of time. Instead, it tries out different levels of complexity using a special algorithm called RJMCMC. This allows it to automatically discover the right balance between simplicity and accuracy, without the user having to make that decision manually.
By using this Bayesian approach, BINDy can also provide uncertainty estimates for the identified model parameters, which can be important for understanding the reliability of the results.
Technical Explanation
BINDy is a Bayesian method for identifying nonlinear dynamical systems from time-series data. It uses a reversible-jump Markov-chain Monte-Carlo (RJMCMC) algorithm to explore different model structures and parameter values.
The key aspect of BINDy is that it can automatically determine the appropriate model complexity without requiring the user to specify it in advance. This is achieved by allowing the RJMCMC algorithm to propose changes to the model structure, such as adding or removing terms in the governing differential equations.
By exploring this space of possible models, BINDy can identify the simplest model that still adequately explains the observed data. Additionally, the Bayesian framework provides uncertainty quantification for the estimated model parameters, which can be important for interpreting the results.
BINDy was demonstrated on several example systems, including the Lorenz attractor and a model of population dynamics. The results showed that BINDy could accurately identify the underlying nonlinear dynamics from noisy time-series data.
Critical Analysis
The paper provides a thorough technical description of the BINDy method and demonstrates its effectiveness on several example problems. However, the authors do acknowledge some limitations and areas for further research.
One potential issue is the computational cost of the RJMCMC algorithm, which may become prohibitive for very high-dimensional systems. The authors suggest that using more efficient MCMC sampling techniques could help address this.
Additionally, the paper focuses on identifying the model structure, but does not extensively discuss how to handle cases where the true underlying dynamics are not well-represented by the available model classes. Exploring ways to relax these model assumptions could be an interesting direction for future work.
Overall, BINDy appears to be a promising approach for nonlinear system identification, but as with any method, its performance and applicability will depend on the specific problem at hand and the available data.
Conclusion
BINDy presents a Bayesian framework for identifying nonlinear dynamical systems from time-series data. By using a reversible-jump MCMC algorithm, it can automatically determine the appropriate model complexity without requiring the user to specify it in advance.
This flexible approach, combined with the ability to quantify parameter uncertainties, makes BINDy a valuable tool for researchers and engineers working on a wide range of nonlinear modeling problems. While the method has some computational limitations, the authors have outlined promising directions for future improvements and extensions.
Overall, the BINDy framework represents an important advance in the field of nonlinear system identification, with the potential to yield deeper insights into the underlying dynamics of complex systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
BINDy -- Bayesian identification of nonlinear dynamics with reversible-jump Markov-chain Monte-Carlo
Max D. Champneys, Timothy J. Rogers
Model parsimony is an important emph{cognitive bias} in data-driven modelling that aids interpretability and helps to prevent over-fitting. Sparse identification of nonlinear dynamics (SINDy) methods are able to learn sparse representations of complex dynamics directly from data, given a basis of library functions. In this work, a novel Bayesian treatment of dictionary learning system identification, as an alternative to SINDy, is envisaged. The proposed method -- Bayesian identification of nonlinear dynamics (BINDy) -- is distinct from previous approaches in that it targets the full joint posterior distribution over both the terms in the library and their parameterisation in the model. This formulation confers the advantage that an arbitrary prior may be placed over the model structure to produce models that are sparse in the model space rather than in parameter space. Because this posterior is defined over parameter vectors that can change in dimension, the inference cannot be performed by standard techniques. Instead, a Gibbs sampler based on reversible-jump Markov-chain Monte-Carlo is proposed. BINDy is shown to compare favourably to ensemble SINDy in three benchmark case-studies. In particular, it is seen that the proposed method is better able to assign high probability to correct model terms.
Read more8/16/2024
🧠
0
GN-SINDy: Greedy Sampling Neural Network in Sparse Identification of Nonlinear Partial Differential Equations
Ali Forootani, Peter Benner
The sparse identification of nonlinear dynamical systems (SINDy) is a data-driven technique employed for uncovering and representing the fundamental dynamics of intricate systems based on observational data. However, a primary obstacle in the discovery of models for nonlinear partial differential equations (PDEs) lies in addressing the challenges posed by the curse of dimensionality and large datasets. Consequently, the strategic selection of the most informative samples within a given dataset plays a crucial role in reducing computational costs and enhancing the effectiveness of SINDy-based algorithms. To this aim, we employ a greedy sampling approach to the snapshot matrix of a PDE to obtain its valuable samples, which are suitable to train a deep neural network (DNN) in a SINDy framework. SINDy based algorithms often consist of a data collection unit, constructing a dictionary of basis functions, computing the time derivative, and solving a sparse identification problem which ends to regularised least squares minimization. In this paper, we extend the results of a SINDy based deep learning model discovery (DeePyMoD) approach by integrating greedy sampling technique in its data collection unit and new sparsity promoting algorithms in the least squares minimization unit. In this regard we introduce the greedy sampling neural network in sparse identification of nonlinear partial differential equations (GN-SINDy) which blends a greedy sampling method, the DNN, and the SINDy algorithm. In the implementation phase, to show the effectiveness of GN-SINDy, we compare its results with DeePyMoD by using a Python package that is prepared for this purpose on numerous PDE discovery
Read more5/15/2024
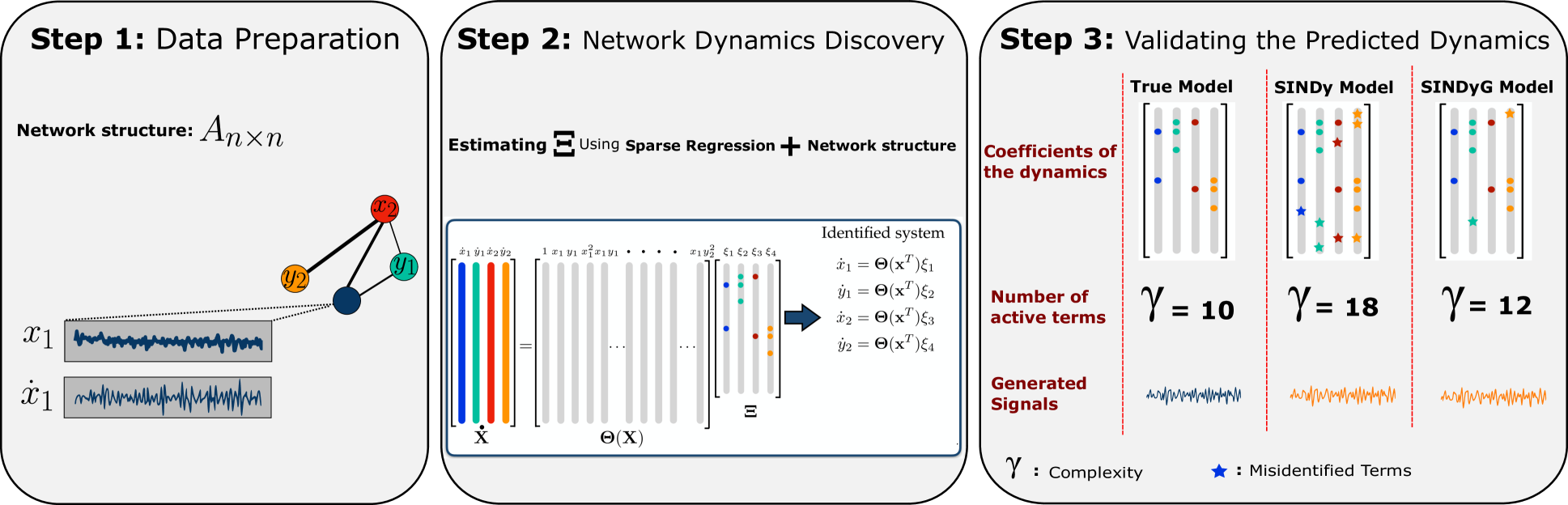
0
Discovering Governing equations from Graph-Structured Data by Sparse Identification of Nonlinear Dynamical Systems
Mohammad Amin Basiri, Sina Khanmohammadi
The combination of machine learning (ML) and sparsity-promoting techniques is enabling direct extraction of governing equations from data, revolutionizing computational modeling in diverse fields of science and engineering. The discovered dynamical models could be used to address challenges in climate science, neuroscience, ecology, finance, epidemiology, and beyond. However, most existing sparse identification methods for discovering dynamical systems treat the whole system as one without considering the interactions between subsystems. As a result, such models are not able to capture small changes in the emergent system behavior. To address this issue, we developed a new method called Sparse Identification of Nonlinear Dynamical Systems from Graph-structured data (SINDyG), which incorporates the network structure into sparse regression to identify model parameters that explain the underlying network dynamics. SINDyG discovers the governing equations of network dynamics while offering improvements in accuracy and model simplicity.
Read more9/10/2024
🤖
0
Simultaneous identification of models and parameters of scientific simulators
Cornelius Schroder, Jakob H. Macke
Many scientific models are composed of multiple discrete components, and scientists often make heuristic decisions about which components to include. Bayesian inference provides a mathematical framework for systematically selecting model components, but defining prior distributions over model components and developing associated inference schemes has been challenging. We approach this problem in a simulation-based inference framework: We define model priors over candidate components and, from model simulations, train neural networks to infer joint probability distributions over both model components and associated parameters. Our method, simulation-based model inference (SBMI), represents distributions over model components as a conditional mixture of multivariate binary distributions in the Grassmann formalism. SBMI can be applied to any compositional stochastic simulator without requiring likelihood evaluations. We evaluate SBMI on a simple time series model and on two scientific models from neuroscience, and show that it can discover multiple data-consistent model configurations, and that it reveals non-identifiable model components and parameters. SBMI provides a powerful tool for data-driven scientific inquiry which will allow scientists to identify essential model components and make uncertainty-informed modelling decisions.
Read more5/31/2024