BiomedParse: a biomedical foundation model for image parsing of everything everywhere all at once

1
📈
Sign in to get full access
Overview
- Biomedical image analysis is crucial for scientific discoveries in fields like cell biology, pathology, and radiology.
- Holistic image analysis involves interconnected tasks like segmentation, detection, and recognition of relevant objects.
- The researchers propose BiomedParse, a biomedical foundation model that can jointly perform these tasks for 82 object types across 9 imaging modalities.
- BiomedParse leverages natural language labels and descriptions to harmonize the information with biomedical ontologies, creating a large dataset of over 6 million image-mask-text triples.
- The model demonstrates state-of-the-art performance on segmentation, detection, and recognition tasks, enabling efficient and accurate image-based biomedical discovery.
Plain English Explanation
Biomedical images, such as microscope images of cells or X-rays, contain a wealth of information that scientists use to make important discoveries. Analyzing these images often involves several interconnected tasks, like:
- Segmentation: Identifying the boundaries of different objects or structures within the image.
- Detection: Locating specific objects of interest, like a particular type of cell.
- Recognition: Identifying all the objects in an image and classifying them by type.
The researchers developed a model called BiomedParse that can perform all of these tasks jointly, rather than requiring them to be done separately. This allows the model to learn from the connections between the different tasks, improving the accuracy of each one.
BiomedParse uses natural language descriptions of the objects in the images, along with established biomedical ontologies (formal systems for organizing and classifying biomedical knowledge), to create a large dataset of over 6 million image-description-label triples. This helps the model understand the relationships between the visual information in the images and the corresponding biomedical concepts.
When tested, BiomedParse outperformed other state-of-the-art methods on a wide range of segmentation, detection, and recognition tasks across different biomedical imaging modalities, like microscopy and X-rays. This suggests that BiomedParse could be a valuable tool for efficient and accurate image-based biomedical discovery, enabling scientists to extract more information from their images more quickly and easily.
Technical Explanation
The researchers propose BiomedParse, a biomedical foundation model for imaging parsing that can jointly conduct segmentation, detection, and recognition for 82 object types across 9 imaging modalities. This holistic approach to image analysis aims to improve the accuracy of individual tasks and enable novel applications, such as segmenting all relevant objects in an image through a text prompt, rather than requiring users to specify bounding boxes for each object manually.
To create the necessary training data, the researchers leveraged natural language labels and descriptions accompanying the biomedical imaging datasets, using GPT-4 to harmonize the noisy, unstructured text information with established biomedical object ontologies. This resulted in a large dataset of over 6 million triples of image, segmentation mask, and textual description.
On image segmentation, the researchers showed that BiomedParse outperforms state-of-the-art methods on 102,855 test image-mask-label triples across 9 imaging modalities. For object detection, BiomedParse again demonstrated state-of-the-art performance, particularly on objects with irregular shapes. For object recognition, the model can simultaneously segment and label all biomedical objects in an image, showcasing its ability to perform multiple tasks jointly.
Critical Analysis
The researchers acknowledge several limitations and areas for further research. For example, they note that the performance of BiomedParse may be affected by the quality and coverage of the natural language descriptions in the training data, as well as the accuracy of the biomedical ontologies used. Additionally, the model's ability to generalize to novel object types or imaging modalities not represented in the training data remains to be explored.
While the results are impressive, it would be valuable to see further analysis of the model's performance on specific types of objects or imaging modalities, as well as its robustness to common challenges in biomedical image analysis, such as noise, occlusion, and variations in imaging conditions.
Lastly, the researchers do not discuss the computational and memory requirements of BiomedParse, which could be an important practical consideration for its deployment in real-world biomedical applications. Integrating BiomedParse with interactive segmentation tools or exploring ways to make the model more efficient could further enhance its usability and impact.
Conclusion
BiomedParse is a promising step towards a unified, accurate, and efficient tool for biomedical image analysis. By jointly solving segmentation, detection, and recognition tasks across a wide range of imaging modalities, the model has the potential to significantly accelerate and enhance image-based biomedical discovery. The researchers' use of natural language descriptions and biomedical ontologies to create a large-scale training dataset is a particularly innovative approach that could inspire similar efforts in other domains. Further research to address the model's limitations and optimize its performance and efficiency could solidify BiomedParse's position as a valuable resource for the biomedical research community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
1
BiomedParse: a biomedical foundation model for image parsing of everything everywhere all at once
Theodore Zhao, Yu Gu, Jianwei Yang, Naoto Usuyama, Ho Hin Lee, Tristan Naumann, Jianfeng Gao, Angela Crabtree, Jacob Abel, Christine Moung-Wen, Brian Piening, Carlo Bifulco, Mu Wei, Hoifung Poon, Sheng Wang
Biomedical image analysis is fundamental for biomedical discovery in cell biology, pathology, radiology, and many other biomedical domains. Holistic image analysis comprises interdependent subtasks such as segmentation, detection, and recognition of relevant objects. Here, we propose BiomedParse, a biomedical foundation model for imaging parsing that can jointly conduct segmentation, detection, and recognition for 82 object types across 9 imaging modalities. Through joint learning, we can improve accuracy for individual tasks and enable novel applications such as segmenting all relevant objects in an image through a text prompt, rather than requiring users to laboriously specify the bounding box for each object. We leveraged readily available natural-language labels or descriptions accompanying those datasets and use GPT-4 to harmonize the noisy, unstructured text information with established biomedical object ontologies. We created a large dataset comprising over six million triples of image, segmentation mask, and textual description. On image segmentation, we showed that BiomedParse is broadly applicable, outperforming state-of-the-art methods on 102,855 test image-mask-label triples across 9 imaging modalities (everything). On object detection, which aims to locate a specific object of interest, BiomedParse again attained state-of-the-art performance, especially on objects with irregular shapes (everywhere). On object recognition, which aims to identify all objects in a given image along with their semantic types, we showed that BiomedParse can simultaneously segment and label all biomedical objects in an image (all at once). In summary, BiomedParse is an all-in-one tool for biomedical image analysis by jointly solving segmentation, detection, and recognition for all major biomedical image modalities, paving the path for efficient and accurate image-based biomedical discovery.
Read more6/6/2024

0
Biomedical SAM 2: Segment Anything in Biomedical Images and Videos
Zhiling Yan, Weixiang Sun, Rong Zhou, Zhengqing Yuan, Kai Zhang, Yiwei Li, Tianming Liu, Quanzheng Li, Xiang Li, Lifang He, Lichao Sun
Medical image segmentation and video object segmentation are essential for diagnosing and analyzing diseases by identifying and measuring biological structures. Recent advances in natural domain have been driven by foundation models like the Segment Anything Model 2 (SAM-2). To explore the performance of SAM-2 in biomedical applications, we designed three evaluation pipelines for single-frame 2D image segmentation, multi-frame 3D image segmentation and multi-frame video segmentation with varied prompt designs, revealing SAM-2's limitations in medical contexts. Consequently, we developed BioSAM-2, an enhanced foundation model optimized for biomedical data based on SAM-2. Our experiments show that BioSAM-2 not only surpasses the performance of existing state-of-the-art foundation models but also matches or even exceeds specialist models, demonstrating its efficacy and potential in the medical domain.
Read more8/20/2024
0
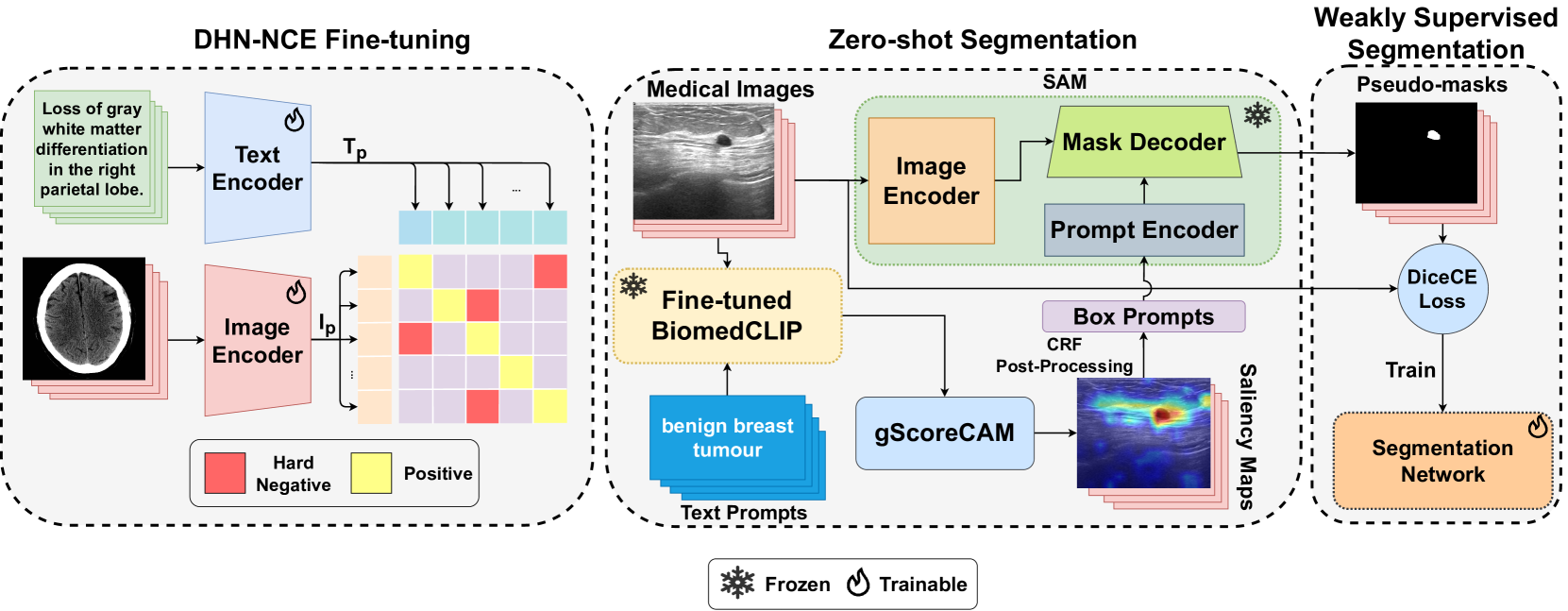
MedCLIP-SAM: Bridging Text and Image Towards Universal Medical Image Segmentation
Taha Koleilat, Hojat Asgariandehkordi, Hassan Rivaz, Yiming Xiao
Medical image segmentation of anatomical structures and pathology is crucial in modern clinical diagnosis, disease study, and treatment planning. To date, great progress has been made in deep learning-based segmentation techniques, but most methods still lack data efficiency, generalizability, and interactability. Consequently, the development of new, precise segmentation methods that demand fewer labeled datasets is of utmost importance in medical image analysis. Recently, the emergence of foundation models, such as CLIP and Segment-Anything-Model (SAM), with comprehensive cross-domain representation opened the door for interactive and universal image segmentation. However, exploration of these models for data-efficient medical image segmentation is still limited, but is highly necessary. In this paper, we propose a novel framework, called MedCLIP-SAM that combines CLIP and SAM models to generate segmentation of clinical scans using text prompts in both zero-shot and weakly supervised settings. To achieve this, we employed a new Decoupled Hard Negative Noise Contrastive Estimation (DHN-NCE) loss to fine-tune the BiomedCLIP model and the recent gScoreCAM to generate prompts to obtain segmentation masks from SAM in a zero-shot setting. Additionally, we explored the use of zero-shot segmentation labels in a weakly supervised paradigm to improve the segmentation quality further. By extensively testing three diverse segmentation tasks and medical image modalities (breast tumor ultrasound, brain tumor MRI, and lung X-ray), our proposed framework has demonstrated excellent accuracy. Code is available at https://github.com/HealthX-Lab/MedCLIP-SAM.
Read more6/21/2024
📈
0
One Model to Rule them All: Towards Universal Segmentation for Medical Images with Text Prompts
Ziheng Zhao, Yao Zhang, Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, Weidi Xie
In this study, we aim to build up a model that can Segment Anything in radiology scans, driven by Text prompts, termed as SAT. Our main contributions are three folds: (i) for dataset construction, we construct the first multi-modal knowledge tree on human anatomy, including 6502 anatomical terminologies; Then we build up the largest and most comprehensive segmentation dataset for training, by collecting over 22K 3D medical image scans from 72 segmentation datasets, across 497 classes, with careful standardization on both image scans and label space; (ii) for architecture design, we propose to inject medical knowledge into a text encoder via contrastive learning, and then formulate a universal segmentation model, that can be prompted by feeding in medical terminologies in text form; (iii) As a result, we have trained SAT-Nano (110M parameters) and SAT-Pro (447M parameters), demonstrating comparable performance to 72 specialist nnU-Nets trained on each dataset/subsets. We validate SAT as a foundational segmentation model, with better generalization ability on external (unseen) datasets, and can be further improved on specific tasks after fine-tuning adaptation. Comparing with interactive segmentation model, for example, MedSAM, segmentation model prompted by text enables superior performance, scalability and robustness. As a use case, we demonstrate that SAT can act as a powerful out-of-the-box agent for large language models, enabling visual grounding in clinical procedures such as report generation. All the data, codes, and models in this work have been released.
Read more7/12/2024