Boosting MLPs with a Coarsening Strategy for Long-Term Time Series Forecasting

0
🧠
Sign in to get full access
Overview
- Deep learning models have been effective for long-term time series forecasting, but often struggle to balance expressive power and computational efficiency.
- The researchers propose a novel architecture called the Coarsened Perceptron Network (CP-Net) that enhances the predictive capability of multilayer perceptrons (MLPs) while maintaining linear computational complexity.
- CP-Net utilizes a coarsening strategy with two-stage convolution-based sampling blocks to extract short-term semantic and contextual patterns, complementing the global point-wise projection of MLP layers.
Plain English Explanation
The paper discusses a new deep learning model called the Coarsened Perceptron Network (CP-Net) that aims to improve the forecasting performance of time series data while keeping the computational cost low. Deep learning models have been successful in long-term time series forecasting, but they often struggle to balance being powerful enough to make accurate predictions and being efficient enough to run quickly.
[CP-Net][https://aimodels.fyi/papers/arxiv/tslanet-rethinking-transformers-time-series-representation-learning] introduces a novel architectural design that enhances the capabilities of a standard multilayer perceptron (MLP) model. MLPs are a type of neural network that process data in a global, point-wise fashion. However, they can sometimes miss important short-term patterns in the data.
CP-Net addresses this by using a "coarsening" strategy, which involves applying a series of convolutional layers to the input data. Convolutions are good at extracting local, contextual features. By combining the global projection of the MLP with the local pattern extraction of the convolutions, CP-Net is able to make more accurate forecasts without sacrificing computational efficiency.
The researchers show that CP-Net outperforms state-of-the-art time series forecasting methods by 4.1% on average across several benchmark datasets. It also becomes more effective as the historical data window used for forecasting is increased, demonstrating its ability to effectively leverage long-term dependencies in the data.
Technical Explanation
The key innovation of [CP-Net][https://aimodels.fyi/papers/arxiv/neural-knitworks-patched-neural-implicit-representation-networks] is its use of a coarsening strategy as the architectural backbone. This consists of two-stage convolution-based sampling blocks that extract short-term semantic and contextual patterns from the input time series.
Convolutions are well-suited for capturing local relationships in data, which complements the global point-wise projection performed by the MLP layers. By combining these two components, CP-Net is able to achieve enhanced predictive performance compared to standard MLP models.
Importantly, the convolution-based sampling blocks in CP-Net maintain a linear computational complexity, allowing the model to scale efficiently to long input sequences. This is in contrast to other deep learning approaches for time series forecasting, which may struggle with computational costs as the input window size increases.
The researchers evaluate CP-Net on seven time series forecasting benchmark datasets and demonstrate an average improvement of 4.1% over the state-of-the-art method. They also show that the model's performance continues to improve as the historical look-back window is expanded, indicating its ability to effectively utilize long-term dependencies in the data.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the CP-Net architecture, including comparisons to a range of state-of-the-art time series forecasting models. The researchers acknowledge that while CP-Net achieves strong performance, there may be opportunities for further improvements, such as exploring more advanced coarsening strategies or incorporating additional components like attention mechanisms.
One potential limitation of the study is that it focuses solely on evaluating CP-Net on standard benchmark datasets, which may not fully capture the model's real-world performance. Applying the architecture to more diverse and challenging time series forecasting scenarios could provide additional insights.
Additionally, the paper does not delve deeply into the interpretability of the CP-Net model or provide much analysis of the internal workings and feature representations learned by the network. Further research in this direction could help shed light on the model's strengths and weaknesses, as well as its suitability for different types of time series data.
Overall, the [CP-Net][https://aimodels.fyi/papers/arxiv/analyzing-exploring-training-recipes-large-scale-transformer] architecture represents a promising contribution to the field of time series forecasting, offering a balance of expressive power and computational efficiency. The researchers have laid a solid foundation, and there is potential for future work to build upon and refine the approach.
Conclusion
The Coarsened Perceptron Network (CP-Net) proposed in this paper is a novel deep learning architecture that aims to improve the long-term time series forecasting capabilities of multilayer perceptrons (MLPs) while maintaining computational efficiency. By integrating a coarsening strategy based on two-stage convolution-based sampling blocks, CP-Net is able to extract both global and local patterns from the input data, leading to enhanced predictive performance.
The researchers demonstrate the effectiveness of CP-Net through extensive experiments on seven benchmark time series forecasting datasets, where it outperforms state-of-the-art methods by 4.1% on average. Importantly, the model's performance continues to improve as the historical look-back window is expanded, showcasing its ability to effectively leverage long-term dependencies in the data.
This work represents a promising step forward in the field of time series forecasting, offering a novel architectural design that balances expressive power and computational complexity. The insights and techniques presented in this paper could inspire further research and development of efficient and high-performing deep learning models for a wide range of time series applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Boosting MLPs with a Coarsening Strategy for Long-Term Time Series Forecasting
Nannan Bian, Minhong Zhu, Li Chen, Weiran Cai
Deep learning methods have been exerting their strengths in long-term time series forecasting. However, they often struggle to strike a balance between expressive power and computational efficiency. Resorting to multi-layer perceptrons (MLPs) provides a compromising solution, yet they suffer from two critical problems caused by the intrinsic point-wise mapping mode, in terms of deficient contextual dependencies and inadequate information bottleneck. Here, we propose the Coarsened Perceptron Network (CP-Net), featured by a coarsening strategy that alleviates the above problems associated with the prototype MLPs by forming information granules in place of solitary temporal points. The CP-Net utilizes primarily a two-stage framework for extracting semantic and contextual patterns, which preserves correlations over larger timespans and filters out volatile noises. This is further enhanced by a multi-scale setting, where patterns of diverse granularities are fused towards a comprehensive prediction. Based purely on convolutions of structural simplicity, CP-Net is able to maintain a linear computational complexity and low runtime, while demonstrates an improvement of 4.1% compared with the SOTA method on seven forecasting benchmarks.
Read more5/21/2024

0
Random Projection Layers for Multidimensional Time Series Forecasting
Chin-Chia Michael Yeh, Yujie Fan, Xin Dai, Uday Singh Saini, Vivian Lai, Prince Osei Aboagye, Junpeng Wang, Huiyuan Chen, Yan Zheng, Zhongfang Zhuang, Liang Wang, Wei Zhang
Spatial-temporal forecasting systems play a crucial role in addressing numerous real-world challenges. In this paper, we investigate the potential of addressing spatial-temporal forecasting problems using general time series forecasting models, i.e., models that do not leverage the spatial relationships among the nodes. We propose a all-Multi-Layer Perceptron (all-MLP) time series forecasting architecture called RPMixer. The all-MLP architecture was chosen due to its recent success in time series forecasting benchmarks. Furthermore, our method capitalizes on the ensemble-like behavior of deep neural networks, where each individual block within the network behaves like a base learner in an ensemble model, particularly when identity mapping residual connections are incorporated. By integrating random projection layers into our model, we increase the diversity among the blocks' outputs, thereby improving the overall performance of the network. Extensive experiments conducted on the largest spatial-temporal forecasting benchmark datasets demonstrate that the proposed method outperforms alternative methods, including both spatial-temporal graph models and general forecasting models.
Read more6/13/2024
✨
0
Probabilistic Forecasting with Coherent Aggregation
Kin G. Olivares, Geoffrey N'egiar, Ruijun Ma, O. Nangba Meetei, Mengfei Cao, Michael W. Mahoney
Obtaining accurate probabilistic forecasts is an important operational challenge in many applications, perhaps most obviously in energy management, climate forecasting, supply chain planning, and resource allocation. In many of these applications, there is a natural hierarchical structure over the forecasted quantities; and forecasting systems that adhere to this hierarchical structure are said to be coherent. Furthermore, operational planning benefits from accuracy at all levels of the aggregation hierarchy. Building accurate and coherent forecasting systems, however, is challenging: classic multivariate time series tools and neural network methods are still being adapted for this purpose. In this paper, we augment an MQForecaster neural network architecture with a novel deep Gaussian factor forecasting model that achieves coherence by construction, yielding a method we call the Deep Coherent Factor Model Neural Network (DeepCoFactor) model. DeepCoFactor generates samples that can be differentiated with respect to model parameters, allowing optimization on various sample-based learning objectives that align with the forecasting system's goals, including quantile loss and the scaled Continuous Ranked Probability Score (CRPS). In a comparison to state-of-the-art coherent forecasting methods, DeepCoFactor achieves significant improvements in scaled CRPS forecast accuracy, with gains between 4.16 and 54.40%, as measured on three publicly available hierarchical forecasting datasets.
Read more8/7/2024
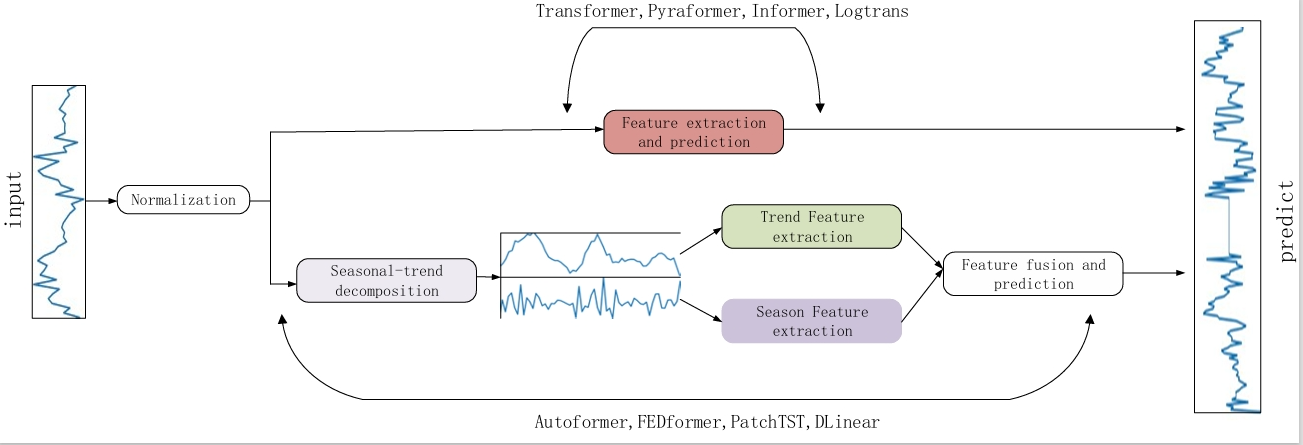
0
FPN-fusion: Enhanced Linear Complexity Time Series Forecasting Model
Chu Li, Pingjia Xiao, Qiping Yuan
This study presents a novel time series prediction model, FPN-fusion, designed with linear computational complexity, demonstrating superior predictive performance compared to DLiner without increasing parameter count or computational demands. Our model introduces two key innovations: first, a Feature Pyramid Network (FPN) is employed to effectively capture time series data characteristics, bypassing the traditional decomposition into trend and seasonal components. Second, a multi-level fusion structure is developed to integrate deep and shallow features seamlessly. Empirically, FPN-fusion outperforms DLiner in 31 out of 32 test cases on eight open-source datasets, with an average reduction of 16.8% in mean squared error (MSE) and 11.8% in mean absolute error (MAE). Additionally, compared to the transformer-based PatchTST, FPN-fusion achieves 10 best MSE and 15 best MAE results, using only 8% of PatchTST's total computational load in the 32 test projects.
Read more6/12/2024