Boundless: Generating Photorealistic Synthetic Data for Object Detection in Urban Streetscapes

0

Sign in to get full access
Overview
- This paper presents "Boundless", a system for generating photorealistic synthetic data for training object detection models in urban streetscapes.
- The authors use a combination of real-world data collection, 3D modeling, and rendering techniques to create high-quality synthetic images with diverse scene content and labeled objects.
- The goal is to address the data scarcity problem that can limit the performance of object detection models, especially for rare or hard-to-capture scenarios.
Plain English Explanation
The researchers developed a system called "Boundless" that can generate realistic computer-made images of urban scenes. These synthetic images include all the typical elements you'd find on city streets, like cars, pedestrians, buildings, and more. The key advantage of these computer-generated images is that they can be labeled with the exact locations of the objects, which is very difficult and time-consuming to do with real-world photos.
By having a large dataset of these labeled synthetic images, the researchers can use them to train object detection AI models more effectively. This helps address a common problem in this field, which is that there is often not enough real-world data available, especially for rare or unusual scenarios. The Boundless system allows them to create as much synthetic data as needed to train robust object detectors.
The Boundless system does this by combining techniques like 3D modeling, computer graphics rendering, and real-world data collection. This allows them to generate highly realistic images that closely match the appearance of actual city streets, while also having the ability to precisely label all the objects in the scenes.
Technical Explanation
The Boundless system uses a combination of techniques to generate the synthetic training data:
-
3D City Modeling: The authors create detailed 3D models of urban environments, including buildings, roads, vegetation, and other static elements. These 3D models are built using a combination of procedural generation and asset libraries.
-
Dynamic Scene Population: They then populate the 3D city models with dynamic elements like vehicles, pedestrians, and other movable objects. These are placed in the scene using a combination of simulations, database retrieval, and interactive tools.
-
Photorealistic Rendering: The complete 3D scenes are then rendered into 2D images using advanced computer graphics techniques, such as global illumination and physically-based shading, to achieve a high level of photorealism.
-
Automated Annotation: Since the 3D models contain precise information about the location and properties of all objects, the system can automatically generate accurate semantic segmentation and bounding box annotations for the synthetic images.
The authors evaluate the Boundless system by training object detection models on the synthetic data and testing them on real-world urban datasets. They demonstrate that the models trained on Boundless data can achieve comparable or better performance than models trained on limited real-world data alone.
Critical Analysis
The Boundless paper presents a compelling approach to addressing the data scarcity problem in object detection for urban scenes. The ability to generate large amounts of high-quality, labeled synthetic data is a valuable contribution to the field.
However, the authors acknowledge some limitations of their approach. For example, the 3D modeling and scene population processes require significant manual effort and expert knowledge, which could limit the scalability and accessibility of the system. Additionally, there may be subtle differences between the synthetic and real-world data distributions that could affect the transferability of the trained models.
Further research could explore ways to improve the automation and realism of the data generation process, as well as investigate techniques to better bridge the gap between synthetic and real-world data. Rigorous evaluation on a wider range of urban datasets and real-world deployment scenarios would also help validate the broader applicability of the Boundless system.
Conclusion
The Boundless paper presents a novel system for generating high-quality, labeled synthetic training data for object detection in urban streetscapes. By combining 3D modeling, dynamic scene population, and photorealistic rendering, the authors demonstrate the ability to create large datasets that can significantly improve the performance of object detection models.
This work addresses an important challenge in the field of computer vision and has the potential to unlock new applications and capabilities for AI-powered systems operating in complex urban environments. As the research in this area continues to evolve, the Boundless system represents an important step forward in leveraging synthetic data to enhance the robustness and reliability of object detection models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Boundless: Generating Photorealistic Synthetic Data for Object Detection in Urban Streetscapes
Mehmet Kerem Turkcan, Yuyang Li, Chengbo Zang, Javad Ghaderi, Gil Zussman, Zoran Kostic
We introduce Boundless, a photo-realistic synthetic data generation system for enabling highly accurate object detection in dense urban streetscapes. Boundless can replace massive real-world data collection and manual ground-truth object annotation (labeling) with an automated and configurable process. Boundless is based on the Unreal Engine 5 (UE5) City Sample project with improvements enabling accurate collection of 3D bounding boxes across different lighting and scene variability conditions. We evaluate the performance of object detection models trained on the dataset generated by Boundless when used for inference on a real-world dataset acquired from medium-altitude cameras. We compare the performance of the Boundless-trained model against the CARLA-trained model and observe an improvement of 7.8 mAP. The results we achieved support the premise that synthetic data generation is a credible methodology for training/fine-tuning scalable object detection models for urban scenes.
Read more9/30/2024

0
Synthetic data augmentation for robotic mobility aids to support blind and low vision people
Hochul Hwang, Krisha Adhikari, Satya Shodhaka, Donghyun Kim
Robotic mobility aids for blind and low-vision (BLV) individuals rely heavily on deep learning-based vision models specialized for various navigational tasks. However, the performance of these models is often constrained by the availability and diversity of real-world datasets, which are challenging to collect in sufficient quantities for different tasks. In this study, we investigate the effectiveness of synthetic data, generated using Unreal Engine 4, for training robust vision models for this safety-critical application. Our findings demonstrate that synthetic data can enhance model performance across multiple tasks, showcasing both its potential and its limitations when compared to real-world data. We offer valuable insights into optimizing synthetic data generation for developing robotic mobility aids. Additionally, we publicly release our generated synthetic dataset to support ongoing research in assistive technologies for BLV individuals, available at https://hchlhwang.github.io/SToP.
Read more9/18/2024
0
GaussianCity: Generative Gaussian Splatting for Unbounded 3D City Generation
Haozhe Xie, Zhaoxi Chen, Fangzhou Hong, Ziwei Liu
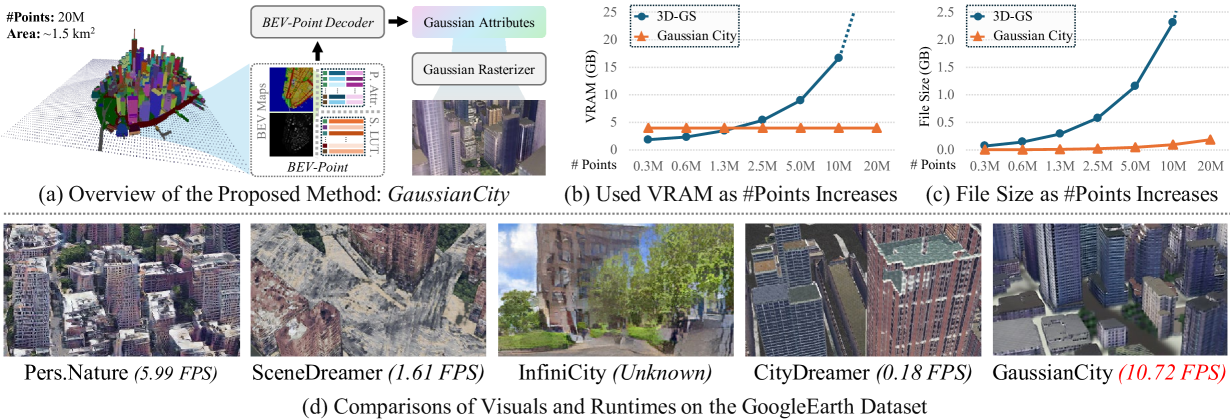
3D city generation with NeRF-based methods shows promising generation results but is computationally inefficient. Recently 3D Gaussian Splatting (3D-GS) has emerged as a highly efficient alternative for object-level 3D generation. However, adapting 3D-GS from finite-scale 3D objects and humans to infinite-scale 3D cities is non-trivial. Unbounded 3D city generation entails significant storage overhead (out-of-memory issues), arising from the need to expand points to billions, often demanding hundreds of Gigabytes of VRAM for a city scene spanning 10km^2. In this paper, we propose GaussianCity, a generative Gaussian Splatting framework dedicated to efficiently synthesizing unbounded 3D cities with a single feed-forward pass. Our key insights are two-fold: 1) Compact 3D Scene Representation: We introduce BEV-Point as a highly compact intermediate representation, ensuring that the growth in VRAM usage for unbounded scenes remains constant, thus enabling unbounded city generation. 2) Spatial-aware Gaussian Attribute Decoder: We present spatial-aware BEV-Point decoder to produce 3D Gaussian attributes, which leverages Point Serializer to integrate the structural and contextual characteristics of BEV points. Extensive experiments demonstrate that GaussianCity achieves state-of-the-art results in both drone-view and street-view 3D city generation. Notably, compared to CityDreamer, GaussianCity exhibits superior performance with a speedup of 60 times (10.72 FPS v.s. 0.18 FPS).
Read more6/11/2024

0
SkyScenes: A Synthetic Dataset for Aerial Scene Understanding
Sahil Khose, Anisha Pal, Aayushi Agarwal, Deepanshi, Judy Hoffman, Prithvijit Chattopadhyay
Real-world aerial scene understanding is limited by a lack of datasets that contain densely annotated images curated under a diverse set of conditions. Due to inherent challenges in obtaining such images in controlled real-world settings, we present SkyScenes, a synthetic dataset of densely annotated aerial images captured from Unmanned Aerial Vehicle (UAV) perspectives. We carefully curate SkyScenes images from CARLA to comprehensively capture diversity across layouts (urban and rural maps), weather conditions, times of day, pitch angles and altitudes with corresponding semantic, instance and depth annotations. Through our experiments using SkyScenes, we show that (1) models trained on SkyScenes generalize well to different real-world scenarios, (2) augmenting training on real images with SkyScenes data can improve real-world performance, (3) controlled variations in SkyScenes can offer insights into how models respond to changes in viewpoint conditions (height and pitch), weather and time of day, and (4) incorporating additional sensor modalities (depth) can improve aerial scene understanding. Our dataset and associated generation code are publicly available at: https://hoffman-group.github.io/SkyScenes/
Read more9/24/2024