The Brain's Bitter Lesson: Scaling Speech Decoding With Self-Supervised Learning
2406.04328
0
0

Abstract
The past few years have produced a series of spectacular advances in the decoding of speech from brain activity. The engine of these advances has been the acquisition of labelled data, with increasingly large datasets acquired from single subjects. However, participants exhibit anatomical and other individual differences, and datasets use varied scanners and task designs. As a result, prior work has struggled to leverage data from multiple subjects, multiple datasets, multiple tasks, and unlabelled datasets. In turn, the field has not benefited from the rapidly growing number of open neural data repositories to exploit large-scale data and deep learning. To address this, we develop an initial set of neuroscience-inspired self-supervised objectives, together with a neural architecture, for representation learning from heterogeneous and unlabelled neural recordings. Experimental results show that representations learned with these objectives scale with data, generalise across subjects, datasets, and tasks, and are also learned faster than using only labelled data. In addition, we set new benchmarks for two foundational speech decoding tasks. Taken together, these methods now unlock the potential for training speech decoding models with orders of magnitude more existing data.
Create account to get full access
Overview
- This paper investigates scaling speech decoding using self-supervised learning, inspired by the "bitter lesson" in AI that general-purpose algorithms and computing power tend to outperform human-designed features and domain knowledge.
- The authors propose a self-supervised learning approach for speech decoding that can leverage large amounts of unlabeled speech data to learn robust representations, outperforming previous state-of-the-art supervised methods.
- The paper covers related work, the proposed approach, experimental results, and a discussion of the implications of their findings.
Plain English Explanation
The researchers in this paper are studying how to improve the ability of AI systems to understand and transcribe human speech. They were inspired by an idea called the "bitter lesson" in AI, which suggests that the most successful AI systems tend to be those that use general-purpose algorithms and a lot of computing power, rather than relying heavily on human-designed features or domain-specific knowledge.
Based on this, the researchers developed a new approach that uses "self-supervised learning" to help the AI system learn how to decode speech. Self-supervised learning means the system can learn useful representations from large amounts of unlabeled speech data, without needing a lot of manually labeled training data. This allows the system to scale up and perform better than previous state-of-the-art methods that relied more on human-designed features.
The key idea is to train the AI system to predict future segments of speech given the current input, which helps it learn robust speech representations that capture the underlying patterns and structure of language. This self-supervised approach allows the system to leverage large amounts of unlabeled speech data to improve its performance, rather than being limited by the availability of manually labeled training data.
The authors tested their approach on several speech decoding benchmarks and found it outperformed previous supervised methods, demonstrating the power of scaling up with self-supervised learning. The implications are that this type of self-supervised learning could be a promising direction for building more capable and scalable speech recognition systems in the future.
Technical Explanation
The paper presents a self-supervised learning approach for scaling speech decoding performance, motivated by the "bitter lesson" in AI that general-purpose algorithms and computing power tend to outperform human-designed features and domain knowledge.
The authors propose a self-supervised learning framework for speech decoding, where the model is trained to predict future speech segments given the current input. This allows the model to learn robust speech representations that capture the underlying structure and patterns of language, without relying on manually labeled training data. The authors evaluate their approach on several speech decoding benchmarks, including transcription of acoustic signals and neural decoding of brain activity, and find it outperforms previous state-of-the-art supervised methods.
The key technical contributions include the self-supervised training objective, the model architecture, and the demonstration of scaled performance on speech decoding tasks. The self-supervised objective involves predicting future speech frames given the current input, which encourages the model to learn useful representations of speech. The model architecture utilizes transformer-based neural networks to effectively capture long-range speech dependencies.
The authors also explore the impact of dataset size, showing that their self-supervised approach is able to leverage large amounts of unlabeled speech data to significantly outperform previous supervised methods, even on small labeled datasets. This suggests that self-supervised learning can be a powerful tool for scaling speech decoding performance by harnessing the abundance of unlabeled speech data available.
The paper's findings also have implications for the broader field of speech processing, as the authors discuss how the self-supervised learning principles could be applied to other speech-related tasks, such as speech enhancement, voice conversion, and speech synthesis. Overall, the work demonstrates the potential of self-supervised learning to drive significant advances in speech decoding and broader speech technologies.
Critical Analysis
The paper presents a compelling approach to scaling speech decoding performance using self-supervised learning, and the experimental results convincingly demonstrate the advantages of this method over previous supervised techniques. However, there are a few potential limitations and areas for further research that could be explored.
One key limitation is that the paper focuses on standard speech decoding benchmarks, which may not fully capture the real-world challenges faced by speech recognition systems. The authors acknowledge that their approach has not yet been tested in more natural, noisy, or multi-speaker environments, where additional challenges like robust feature extraction and speaker diarization may arise.
Additionally, while the self-supervised learning approach can leverage large amounts of unlabeled data, the extent to which it can generalize to truly low-resource scenarios with very limited labeled data is not entirely clear. Further investigation into the data efficiency and sample complexity of the proposed method would be valuable.
The paper also does not provide a detailed analysis of the learned speech representations, nor does it compare them to representations learned by other self-supervised approaches, such as those used in language models or audio processing tasks. A deeper understanding of the properties and capabilities of the learned representations could shed light on the strengths and limitations of the proposed approach.
Overall, the paper makes a significant contribution to the field of speech decoding by demonstrating the power of self-supervised learning. However, further research is needed to fully understand the capabilities and limitations of this approach, and to explore its applicability in more realistic and challenging speech processing scenarios.
Conclusion
This paper presents a self-supervised learning approach for scaling speech decoding performance, inspired by the "bitter lesson" in AI that general-purpose algorithms and computing power tend to outperform human-designed features and domain knowledge. The key idea is to train the AI system to predict future segments of speech given the current input, which allows it to learn robust speech representations from large amounts of unlabeled data.
The authors show that this self-supervised approach outperforms previous state-of-the-art supervised methods on several speech decoding benchmarks, including transcription of acoustic signals and neural decoding of brain activity. This suggests that self-supervised learning can be a powerful tool for building more capable and scalable speech recognition systems, by leveraging the abundance of unlabeled speech data available.
The findings from this paper have broader implications for the field of speech processing, as the self-supervised learning principles could potentially be applied to other speech-related tasks, such as speech enhancement, voice conversion, and speech synthesis. Overall, the work demonstrates the value of exploring general-purpose, data-driven approaches to speech decoding, and provides a promising direction for future research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
Improving Speech Decoding from ECoG with Self-Supervised Pretraining
Brian A. Yuan, Joseph G. Makin
0
0
Recent work on intracranial brain-machine interfaces has demonstrated that spoken speech can be decoded with high accuracy, essentially by treating the problem as an instance of supervised learning and training deep neural networks to map from neural activity to text. However, such networks pay for their expressiveness with very large numbers of labeled data, a requirement that is particularly burdensome for invasive neural recordings acquired from human patients. On the other hand, these patients typically produce speech outside of the experimental blocks used for training decoders. Making use of such data, and data from other patients, to improve decoding would ease the burden of data collection -- especially onerous for dys- and anarthric patients. Here we demonstrate that this is possible, by reengineering wav2vec -- a simple, self-supervised, fully convolutional model that learns latent representations of audio using a noise-contrastive loss -- for electrocorticographic (ECoG) data. We train this model on unlabelled ECoG recordings, and subsequently use it to transform ECoG from labeled speech sessions into wav2vec's representation space, before finally training a supervised encoder-decoder to map these representations to text. We experiment with various numbers of labeled blocks; for almost all choices, the new representations yield superior decoding performance to the original ECoG data, and in no cases do they yield worse. Performance can also be improved in some cases by pretraining wav2vec on another patient's data. In the best cases, wav2vec's representations decrease word error rates over the original data by upwards of 50%.
5/30/2024

NeuSpeech: Decode Neural signal as Speech
Yiqian Yang, Yiqun Duan, Qiang Zhang, Hyejeong Jo, Jinni Zhou, Won Hee Lee, Renjing Xu, Hui Xiong
0
0
Decoding language from brain dynamics is an important open direction in the realm of brain-computer interface (BCI), especially considering the rapid growth of large language models. Compared to invasive-based signals which require electrode implantation surgery, non-invasive neural signals (e.g. EEG, MEG) have attracted increasing attention considering their safety and generality. However, the exploration is not adequate in three aspects: 1) previous methods mainly focus on EEG but none of the previous works address this problem on MEG with better signal quality; 2) prior works have predominantly used $``teacher-forcing$ during generative decoding, which is impractical; 3) prior works are mostly $``BART-based$ not fully auto-regressive, which performs better in other sequence tasks. In this paper, we explore the brain-to-text translation of MEG signals in a speech-decoding formation. Here we are the first to investigate a cross-attention-based ``whisper model for generating text directly from MEG signals without teacher forcing. Our model achieves impressive BLEU-1 scores of 60.30 and 52.89 without pretraining $&$ teacher-forcing on two major datasets ($textit{GWilliams}$ and $textit{Schoffelen}$). This paper conducts a comprehensive review to understand how speech decoding formation performs on the neural decoding tasks, including pretraining initialization, training $&$ evaluation set splitting, augmentation, and scaling law. Code is available at https://github.com/NeuSpeech/NeuSpeech1$.
6/4/2024
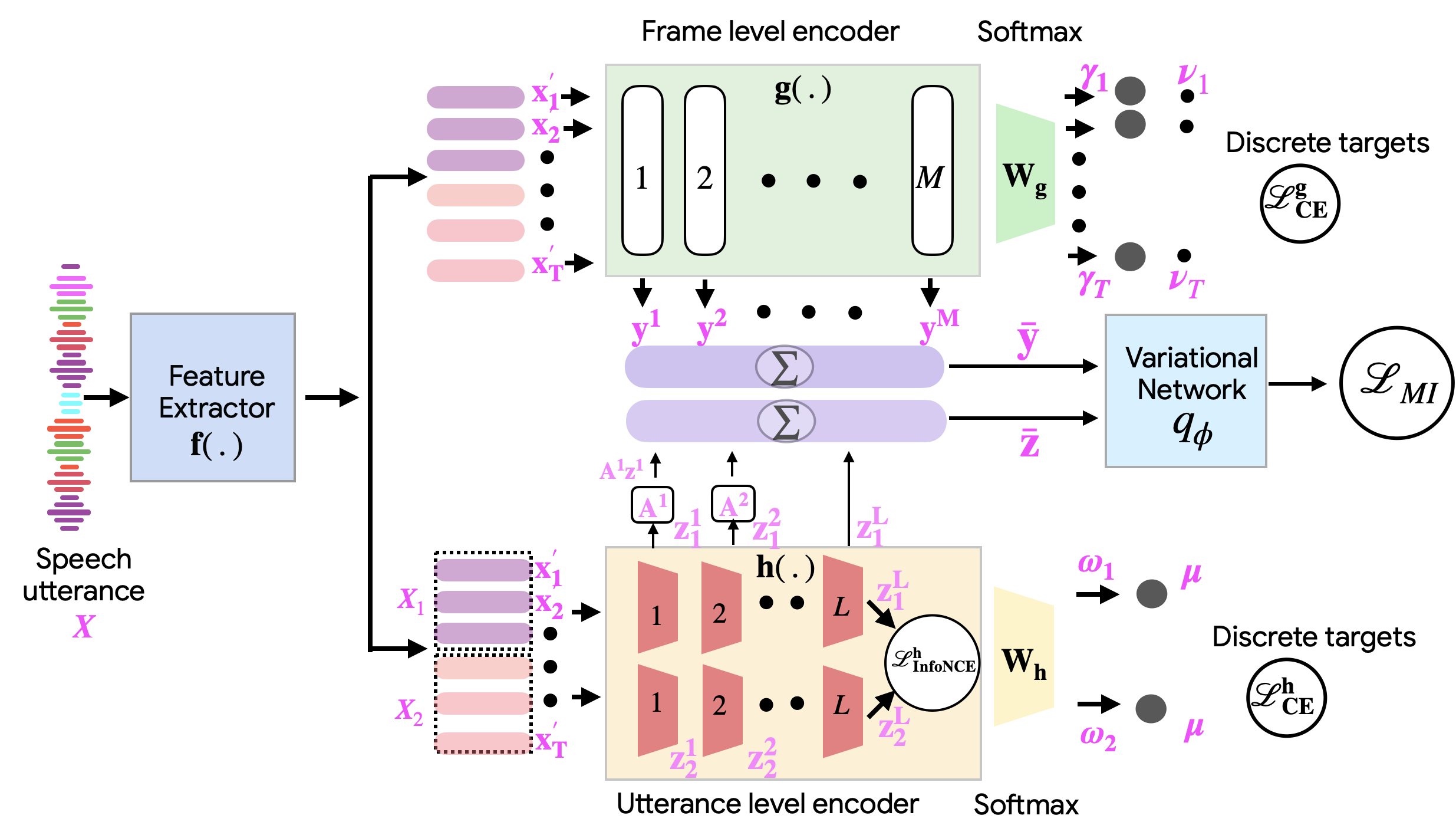
New!Towards the Next Frontier in Speech Representation Learning Using Disentanglement
Varun Krishna, Sriram Ganapathy
0
0
The popular frameworks for self-supervised learning of speech representations have largely focused on frame-level masked prediction of speech regions. While this has shown promising downstream task performance for speech recognition and related tasks, this has largely ignored factors of speech that are encoded at coarser level, like characteristics of the speaker or channel that remain consistent through-out a speech utterance. In this work, we propose a framework for Learning Disentangled Self Supervised (termed as Learn2Diss) representations of speech, which consists of frame-level and an utterance-level encoder modules. The two encoders are initially learned independently, where the frame-level model is largely inspired by existing self supervision techniques, thereby learning pseudo-phonemic representations, while the utterance-level encoder is inspired by constrastive learning of pooled embeddings, thereby learning pseudo-speaker representations. The joint learning of these two modules consists of disentangling the two encoders using a mutual information based criterion. With several downstream evaluation experiments, we show that the proposed Learn2Diss achieves state-of-the-art results on a variety of tasks, with the frame-level encoder representations improving semantic tasks, while the utterance-level representations improve non-semantic tasks.
7/4/2024
🗣️
Towards generalisable and calibrated synthetic speech detection with self-supervised representations
Octavian Pascu, Adriana Stan, Dan Oneata, Elisabeta Oneata, Horia Cucu
0
0
Generalisation -- the ability of a model to perform well on unseen data -- is crucial for building reliable deepfake detectors. However, recent studies have shown that the current audio deepfake models fall short of this desideratum. In this work we investigate the potential of pretrained self-supervised representations in building general and calibrated audio deepfake detection models. We show that large frozen representations coupled with a simple logistic regression classifier are extremely effective in achieving strong generalisation capabilities: compared to the RawNet2 model, this approach reduces the equal error rate from 30.9% to 8.8% on a benchmark of eight deepfake datasets, while learning less than 2k parameters. Moreover, the proposed method produces considerably more reliable predictions compared to previous approaches making it more suitable for realistic use.
6/14/2024