Towards Supervised Performance on Speaker Verification with Self-Supervised Learning by Leveraging Large-Scale ASR Models
2406.02285
0
0
Abstract
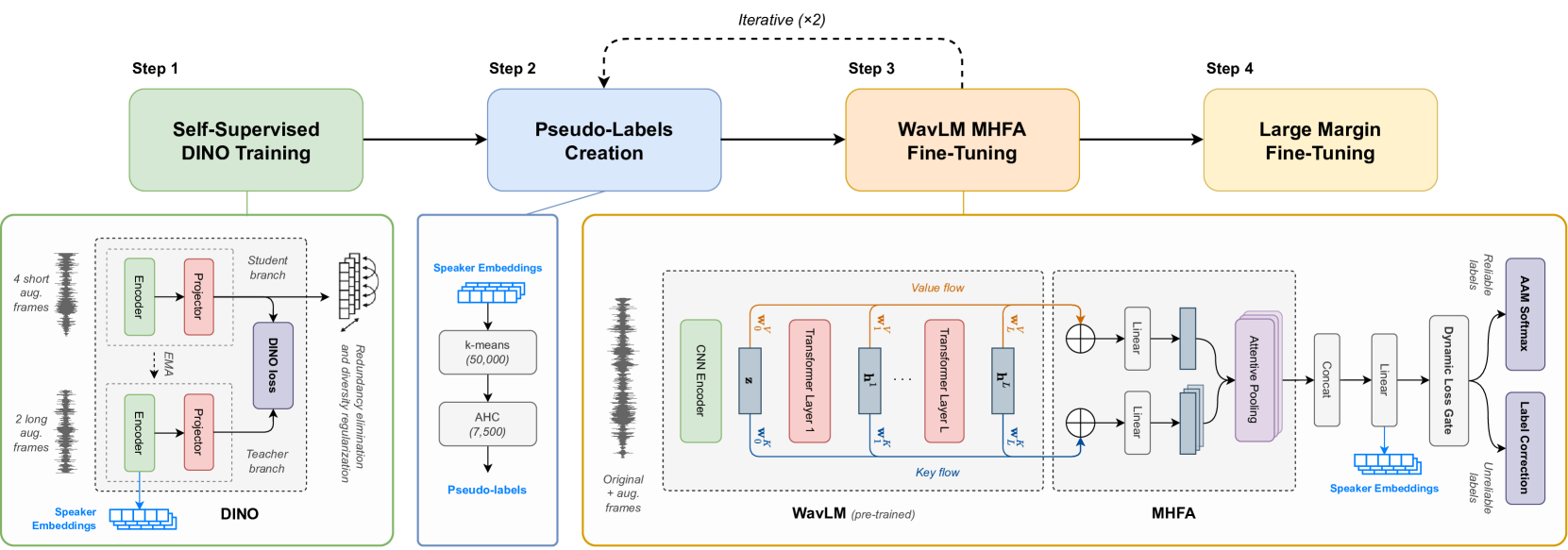
Recent advancements in Self-Supervised Learning (SSL) have shown promising results in Speaker Verification (SV). However, narrowing the performance gap with supervised systems remains an ongoing challenge. Several studies have observed that speech representations from large-scale ASR models contain valuable speaker information. This work explores the limitations of fine-tuning these models for SV using an SSL contrastive objective in an end-to-end approach. Then, we propose a framework to learn speaker representations in an SSL context by fine-tuning a pre-trained WavLM with a supervised loss using pseudo-labels. Initial pseudo-labels are derived from an SSL DINO-based model and are iteratively refined by clustering the model embeddings. Our method achieves 0.99% EER on VoxCeleb1-O, establishing the new state-of-the-art on self-supervised SV. As this performance is close to our supervised baseline of 0.94% EER, this contribution is a step towards supervised performance on SV with SSL.
Create account to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
Improving the Adversarial Robustness for Speaker Verification by Self-Supervised Learning
Haibin Wu, Xu Li, Andy T. Liu, Zhiyong Wu, Helen Meng, Hung-yi Lee
0
0
Previous works have shown that automatic speaker verification (ASV) is seriously vulnerable to malicious spoofing attacks, such as replay, synthetic speech, and recently emerged adversarial attacks. Great efforts have been dedicated to defending ASV against replay and synthetic speech; however, only a few approaches have been explored to deal with adversarial attacks. All the existing approaches to tackle adversarial attacks for ASV require the knowledge for adversarial samples generation, but it is impractical for defenders to know the exact attack algorithms that are applied by the in-the-wild attackers. This work is among the first to perform adversarial defense for ASV without knowing the specific attack algorithms. Inspired by self-supervised learning models (SSLMs) that possess the merits of alleviating the superficial noise in the inputs and reconstructing clean samples from the interrupted ones, this work regards adversarial perturbations as one kind of noise and conducts adversarial defense for ASV by SSLMs. Specifically, we propose to perform adversarial defense from two perspectives: 1) adversarial perturbation purification and 2) adversarial perturbation detection. Experimental results show that our detection module effectively shields the ASV by detecting adversarial samples with an accuracy of around 80%. Moreover, since there is no common metric for evaluating the adversarial defense performance for ASV, this work also formalizes evaluation metrics for adversarial defense considering both purification and detection based approaches into account. We sincerely encourage future works to benchmark their approaches based on the proposed evaluation framework.
6/6/2024

Exploring Self-Supervised Multi-view Contrastive Learning for Speech Emotion Recognition with Limited Annotations
Bulat Khaertdinov, Pedro Jeuris, Annanda Sousa, Enrique Hortal
0
0
Recent advancements in Deep and Self-Supervised Learning (SSL) have led to substantial improvements in Speech Emotion Recognition (SER) performance, reaching unprecedented levels. However, obtaining sufficient amounts of accurately labeled data for training or fine-tuning the models remains a costly and challenging task. In this paper, we propose a multi-view SSL pre-training technique that can be applied to various representations of speech, including the ones generated by large speech models, to improve SER performance in scenarios where annotations are limited. Our experiments, based on wav2vec 2.0, spectral and paralinguistic features, demonstrate that the proposed framework boosts the SER performance, by up to 10% in Unweighted Average Recall, in settings with extremely sparse data annotations.
6/13/2024

LASER: Learning by Aligning Self-supervised Representations of Speech for Improving Content-related Tasks
Amit Meghanani, Thomas Hain
0
0
Self-supervised learning (SSL)-based speech models are extensively used for full-stack speech processing. However, it has been observed that improving SSL-based speech representations using unlabeled speech for content-related tasks is challenging and computationally expensive. Recent attempts have been made to address this issue with cost-effective self-supervised fine-tuning (SSFT) approaches. Continuing in this direction, a cost-effective SSFT method named LASER: Learning by Aligning Self-supervised Representations is presented. LASER is based on the soft-DTW alignment loss with temporal regularisation term. Experiments are conducted with HuBERT and WavLM models and evaluated on the SUPERB benchmark for two content-related tasks: automatic speech recognition (ASR) and phoneme recognition (PR). A relative improvement of 3.7% and 8.2% for HuBERT, and 4.1% and 11.7% for WavLM are observed, for the ASR and PR tasks respectively, with only < 3 hours of fine-tuning on a single GPU.
6/14/2024
🚀
Low-Resource Self-Supervised Learning with SSL-Enhanced TTS
Po-chun Hsu, Ali Elkahky, Wei-Ning Hsu, Yossi Adi, Tu Anh Nguyen, Jade Copet, Emmanuel Dupoux, Hung-yi Lee, Abdelrahman Mohamed
0
0
Self-supervised learning (SSL) techniques have achieved remarkable results in various speech processing tasks. Nonetheless, a significant challenge remains in reducing the reliance on vast amounts of speech data for pre-training. This paper proposes to address this challenge by leveraging synthetic speech to augment a low-resource pre-training corpus. We construct a high-quality text-to-speech (TTS) system with limited resources using SSL features and generate a large synthetic corpus for pre-training. Experimental results demonstrate that our proposed approach effectively reduces the demand for speech data by 90% with only slight performance degradation. To the best of our knowledge, this is the first work aiming to enhance low-resource self-supervised learning in speech processing.
6/5/2024