Breaking the False Sense of Security in Backdoor Defense through Re-Activation Attack
2405.16134
0
0

Abstract
Deep neural networks face persistent challenges in defending against backdoor attacks, leading to an ongoing battle between attacks and defenses. While existing backdoor defense strategies have shown promising performance on reducing attack success rates, can we confidently claim that the backdoor threat has truly been eliminated from the model? To address it, we re-investigate the characteristics of the backdoored models after defense (denoted as defense models). Surprisingly, we find that the original backdoors still exist in defense models derived from existing post-training defense strategies, and the backdoor existence is measured by a novel metric called backdoor existence coefficient. It implies that the backdoors just lie dormant rather than being eliminated. To further verify this finding, we empirically show that these dormant backdoors can be easily re-activated during inference, by manipulating the original trigger with well-designed tiny perturbation using universal adversarial attack. More practically, we extend our backdoor reactivation to black-box scenario, where the defense model can only be queried by the adversary during inference, and develop two effective methods, i.e., query-based and transfer-based backdoor re-activation attacks. The effectiveness of the proposed methods are verified on both image classification and multimodal contrastive learning (i.e., CLIP) tasks. In conclusion, this work uncovers a critical vulnerability that has never been explored in existing defense strategies, emphasizing the urgency of designing more robust and advanced backdoor defense mechanisms in the future.
Create account to get full access
Overview
• This paper examines a new type of attack called a "re-activation attack" that can bypass existing defenses against backdoor attacks in machine learning models.
• Backdoor attacks are a sneaky way for attackers to compromise machine learning models by injecting hidden triggers that cause the model to misclassify inputs during deployment.
• While previous research has proposed various defenses against backdoor attacks, this paper shows how a re-activation attack can reactivate a backdoor that was supposedly removed by these defenses, breaking the sense of security they provide.
Plain English Explanation
Imagine you have a secret way to make a machine learning model do something you want, even if the model's creators try to stop you. This secret way is called a "backdoor attack." The backdoor allows you to make the model give the wrong answer whenever a specific "trigger" is present, without the model's creators knowing.
Researchers have come up with ways to try and detect and remove these backdoors. However, this paper describes a new type of attack called a "re-activation attack" that can reactivate a backdoor, even after the defense measures have been applied. It's like the backdoor was never really removed, just hidden for a while.
This is concerning because it means the existing defenses against backdoor attacks may not be as effective as people thought. The re-activation attack can essentially bypass these defenses and restore the backdoor, giving the attacker control over the model again.
The significance of this work is that it highlights a weakness in the current approaches to protecting machine learning models from backdoor attacks. It shows that more research is needed to develop truly robust and reliable defenses against these types of threats.
Technical Explanation
The paper proposes a new attack called a "re-activation attack" that can bypass existing defenses against backdoor attacks in machine learning models. Backdoor attacks involve injecting hidden triggers into a model during training, which can then cause the model to misclassify inputs during deployment.
The authors demonstrate how a re-activation attack can reactivate a backdoor that was supposedly removed by previous defense techniques, such as Universal Post-Training Reverse Engineering Defense Against Backdoor Attacks, Mask-Based Invisible Backdoor Attacks for Object Detection, Invisible Backdoor Attack Based on Semantic Feature, and Efficient Backdoor Attacks on Deep Neural Networks via Bucketing.
The key idea is that the re-activation attack can exploit subtle changes in the model's internal representations to reactivate the backdoor, even after it has supposedly been removed. The authors demonstrate the effectiveness of this attack through extensive experiments on various datasets and model architectures.
Critical Analysis
The paper provides a valuable contribution by exposing a significant weakness in existing backdoor defense mechanisms. The re-activation attack highlights the need for more robust and comprehensive defenses against these types of threats.
One limitation of the research is that it focuses on a specific type of backdoor attack and defense scenario. It would be important to investigate whether the re-activation attack can be generalized to other types of backdoor attacks and defense approaches.
Additionally, the paper does not explore potential mitigation strategies or countermeasures that could be developed to address the re-activation attack. Further research in this direction would be valuable to help strengthen the security of machine learning systems against these types of advanced attacks.
Conclusion
This paper presents a concerning new type of attack called a "re-activation attack" that can bypass existing defenses against backdoor attacks in machine learning models. The authors demonstrate how this attack can reactivate a backdoor that was supposedly removed by previous defense techniques, highlighting a significant weakness in the current state of backdoor defense research.
The findings of this paper underscore the need for continued efforts to develop robust and reliable defenses against backdoor attacks, as the security of machine learning systems remains a critical challenge that requires ongoing attention and innovation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Universal Post-Training Reverse-Engineering Defense Against Backdoors in Deep Neural Networks
Xi Li, Hang Wang, David J. Miller, George Kesidis
0
0
A variety of defenses have been proposed against backdoors attacks on deep neural network (DNN) classifiers. Universal methods seek to reliably detect and/or mitigate backdoors irrespective of the incorporation mechanism used by the attacker, while reverse-engineering methods often explicitly assume one. In this paper, we describe a new detector that: relies on internal feature map of the defended DNN to detect and reverse-engineer the backdoor and identify its target class; can operate post-training (without access to the training dataset); is highly effective for various incorporation mechanisms (i.e., is universal); and which has low computational overhead and so is scalable. Our detection approach is evaluated for different attacks on benchmark CIFAR-10 and CIFAR-100 image classifiers.
5/24/2024
⛏️
Unveiling and Mitigating Backdoor Vulnerabilities based on Unlearning Weight Changes and Backdoor Activeness
Weilin Lin, Li Liu, Shaokui Wei, Jianze Li, Hui Xiong
0
0
The security threat of backdoor attacks is a central concern for deep neural networks (DNNs). Recently, without poisoned data, unlearning models with clean data and then learning a pruning mask have contributed to backdoor defense. Additionally, vanilla fine-tuning with those clean data can help recover the lost clean accuracy. However, the behavior of clean unlearning is still under-explored, and vanilla fine-tuning unintentionally induces back the backdoor effect. In this work, we first investigate model unlearning from the perspective of weight changes and gradient norms, and find two interesting observations in the backdoored model: 1) the weight changes between poison and clean unlearning are positively correlated, making it possible for us to identify the backdoored-related neurons without using poisoned data; 2) the neurons of the backdoored model are more active (i.e., larger changes in gradient norm) than those in the clean model, suggesting the need to suppress the gradient norm during fine-tuning. Then, we propose an effective two-stage defense method. In the first stage, an efficient Neuron Weight Change (NWC)-based Backdoor Reinitialization is proposed based on observation 1). In the second stage, based on observation 2), we design an Activeness-Aware Fine-Tuning to replace the vanilla fine-tuning. Extensive experiments, involving eight backdoor attacks on three benchmark datasets, demonstrate the superior performance of our proposed method compared to recent state-of-the-art backdoor defense approaches.
5/31/2024
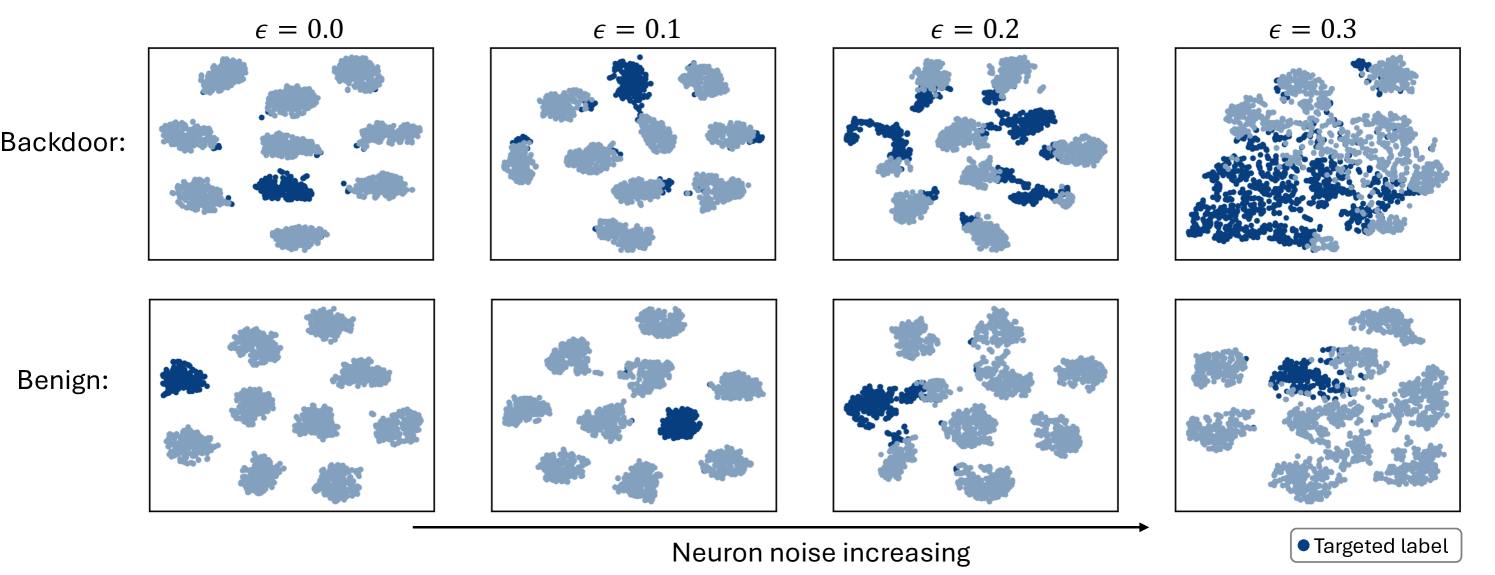
BAN: Detecting Backdoors Activated by Adversarial Neuron Noise
Xiaoyun Xu, Zhuoran Liu, Stefanos Koffas, Shujian Yu, Stjepan Picek
0
0
Backdoor attacks on deep learning represent a recent threat that has gained significant attention in the research community. Backdoor defenses are mainly based on backdoor inversion, which has been shown to be generic, model-agnostic, and applicable to practical threat scenarios. State-of-the-art backdoor inversion recovers a mask in the feature space to locate prominent backdoor features, where benign and backdoor features can be disentangled. However, it suffers from high computational overhead, and we also find that it overly relies on prominent backdoor features that are highly distinguishable from benign features. To tackle these shortcomings, this paper improves backdoor feature inversion for backdoor detection by incorporating extra neuron activation information. In particular, we adversarially increase the loss of backdoored models with respect to weights to activate the backdoor effect, based on which we can easily differentiate backdoored and clean models. Experimental results demonstrate our defense, BAN, is 1.37$times$ (on CIFAR-10) and 5.11$times$ (on ImageNet200) more efficient with 9.99% higher detect success rate than the state-of-the-art defense BTI-DBF. Our code and trained models are publicly available.url{https://anonymous.4open.science/r/ban-4B32}
5/31/2024
📈
Backdoor for Debias: Mitigating Model Bias with Backdoor Attack-based Artificial Bias
Shangxi Wu, Qiuyang He, Dongyuan Lu, Jian Yu, Jitao Sang
0
0
With the swift advancement of deep learning, state-of-the-art algorithms have been utilized in various social situations. Nonetheless, some algorithms have been discovered to exhibit biases and provide unequal results. The current debiasing methods face challenges such as poor utilization of data or intricate training requirements. In this work, we found that the backdoor attack can construct an artificial bias similar to the model bias derived in standard training. Considering the strong adjustability of backdoor triggers, we are motivated to mitigate the model bias by carefully designing reverse artificial bias created from backdoor attack. Based on this, we propose a backdoor debiasing framework based on knowledge distillation, which effectively reduces the model bias from original data and minimizes security risks from the backdoor attack. The proposed solution is validated on both image and structured datasets, showing promising results. This work advances the understanding of backdoor attacks and highlights its potential for beneficial applications. The code for the study can be found at url{https://anonymous.4open.science/r/DwB-BC07/}.
6/18/2024