Breaking Free: How to Hack Safety Guardrails in Black-Box Diffusion Models!

0
Sign in to get full access
Overview
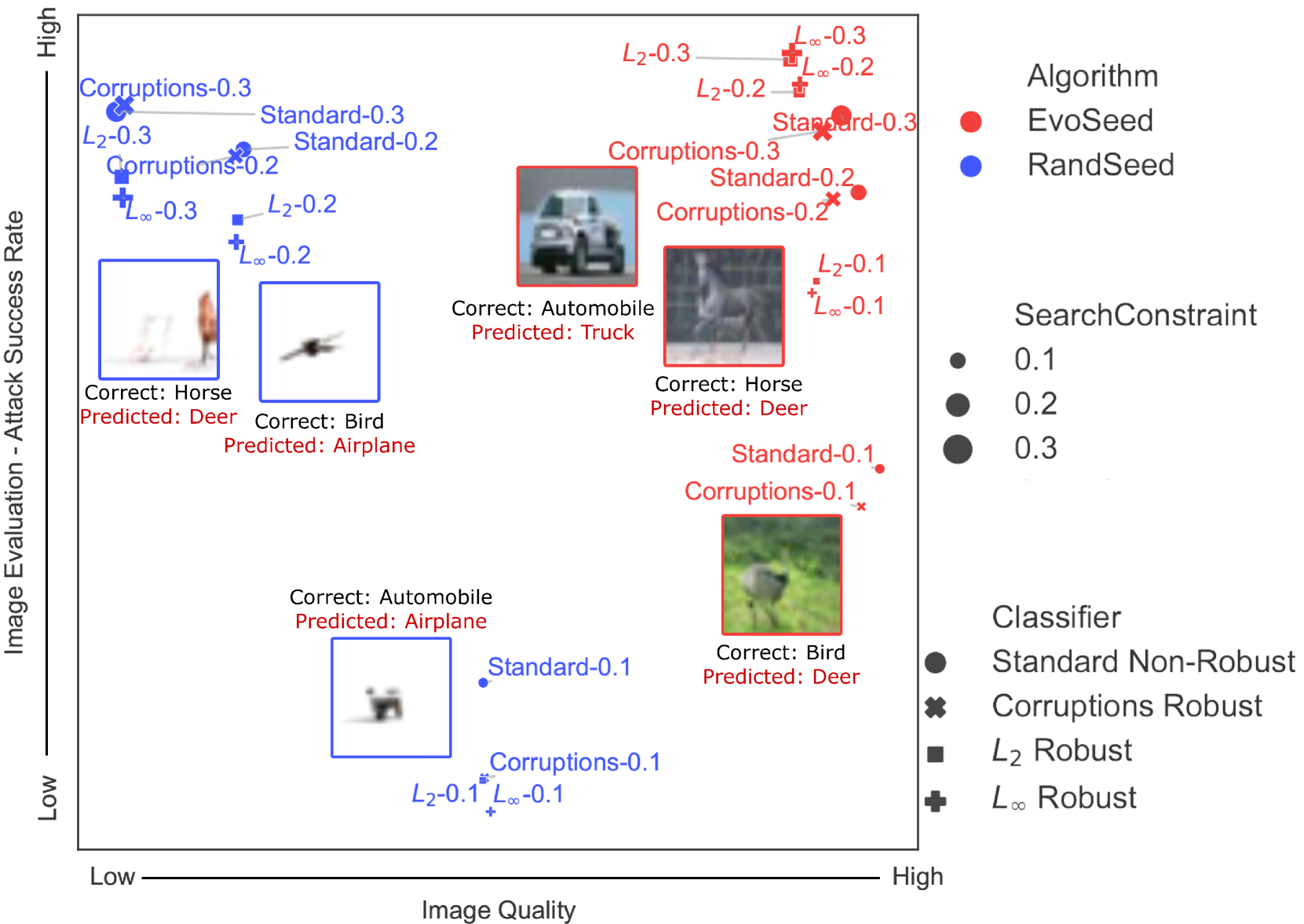
- This research paper, titled "EvoSeed: Unveiling the Threat on Deep Neural Networks with Real-World Illusions," explores the vulnerability of deep neural networks (DNNs) to adversarial attacks in the real world.
- The authors introduce a novel technique called "EvoSeed" that can generate adversarial examples that reliably fool state-of-the-art DNN image classifiers, even in physical environments.
- The research highlights the potential security risks posed by such adversarial attacks and the need for more robust DNN models that can withstand these threats.
Plain English Explanation
Deep neural networks (DNNs) are powerful machine learning models that have revolutionized many fields, including computer vision. However, these models can be highly susceptible to adversarial attacks, where small, imperceptible changes to an input can cause the model to make completely different predictions. This is a significant concern, as it could allow attackers to potentially fool DNN-based systems in real-world applications, such as self-driving cars or facial recognition systems.
The researchers in this study developed a technique called "EvoSeed" that can generate adversarial examples that reliably fool state-of-the-art DNN image classifiers, even in physical environments. [This research builds on previous work on adversarial attacks and defenses, such as the "From Attack to Defense: Insights into Deep Learning Security" and "A Novel Approach to Guard from Adversarial Attacks" papers.]
The key idea behind EvoSeed is to use a combination of optimization techniques, including CMA-ES and diffusion models, to generate adversarial examples that can effectively fool DNN models in the real world, even when the model is shown physical objects. [This builds on research into the strengths and weaknesses of diffusion models, such as the "Intriguing Properties of Diffusion Models: An Empirical Study on Natural and Adversarial Tasks" and "Diffusion Models Can Be Hacked: Probing and Attacking Diffusion Models with Transferable Adversarial Examples" papers, as well as research into using diffusion models for DeepFakes.]
The findings of this research highlight the need for more robust and secure DNN models that can better withstand these types of adversarial attacks, especially in critical real-world applications. The authors suggest that further research is needed to develop more effective defenses against these types of threats.
Technical Explanation
The researchers in this study propose a novel technique called "EvoSeed" for generating adversarial examples that can reliably fool state-of-the-art DNN image classifiers, even in physical environments.
The key components of the EvoSeed approach are:
-
Optimization Techniques: The researchers use a combination of optimization techniques, including Covariance Matrix Adaptation Evolution Strategy (CMA-ES) and diffusion models, to generate adversarial examples that can effectively fool DNN models in the real world.
-
Adversarial Example Generation: The EvoSeed method leverages these optimization techniques to generate adversarial examples that can reliably fool DNN image classifiers, even when the model is shown physical objects.
-
Evaluation in Physical Environments: The researchers extensively evaluate the performance of the EvoSeed approach in physical environments, demonstrating its ability to successfully attack DNN models in real-world settings.
The results of the study show that the EvoSeed technique can generate adversarial examples that are highly effective at fooling state-of-the-art DNN image classifiers, even when the models are presented with physical objects. This highlights the significant security risks posed by such adversarial attacks and the need for more robust DNN models that can better withstand these threats.
Critical Analysis
The research presented in this paper makes important contributions to the field of DNN security and adversarial attacks. The authors have developed a novel technique, EvoSeed, that can effectively generate adversarial examples that reliably fool state-of-the-art DNN image classifiers, even in physical environments.
However, the paper also acknowledges several limitations and areas for further research. For example, the authors note that the EvoSeed approach may be computationally expensive and time-consuming, which could limit its practical applicability. Additionally, the researchers suggest that further work is needed to develop more robust DNN models that can better withstand these types of adversarial attacks, especially in critical real-world applications.
[While the research on adversarial attacks and defenses, such as the "From Attack to Defense: Insights into Deep Learning Security" and "A Novel Approach to Guard from Adversarial Attacks" papers, provides important insights, the findings in this study highlight the ongoing challenges in this area and the need for continued research.]
It is also worth considering the potential societal implications of this research, as adversarial attacks on DNN-based systems could have significant real-world consequences, especially in critical applications like self-driving cars or facial recognition systems. The authors emphasize the need for more robust and secure DNN models, but further work may be needed to address these broader concerns.
Conclusion
This research paper introduces a novel technique called "EvoSeed" that can effectively generate adversarial examples that reliably fool state-of-the-art DNN image classifiers, even in physical environments. The findings highlight the significant security risks posed by such adversarial attacks and the need for more robust and secure DNN models that can better withstand these threats, especially in critical real-world applications.
[While this research builds on previous work on adversarial attacks and defenses, as well as research into the strengths and weaknesses of diffusion models, the EvoSeed approach introduces new techniques that can generate highly effective adversarial examples. The critical analysis suggests that further research is needed to address the limitations of the EvoSeed approach and develop more comprehensive solutions to the problem of adversarial attacks on DNN models.]
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Breaking Free: How to Hack Safety Guardrails in Black-Box Diffusion Models!
Shashank Kotyan, Po-Yuan Mao, Pin-Yu Chen, Danilo Vasconcellos Vargas
Deep neural networks can be exploited using natural adversarial samples, which do not impact human perception. Current approaches often rely on deep neural networks' white-box nature to generate these adversarial samples or synthetically alter the distribution of adversarial samples compared to the training distribution. In contrast, we propose EvoSeed, a novel evolutionary strategy-based algorithmic framework for generating photo-realistic natural adversarial samples. Our EvoSeed framework uses auxiliary Conditional Diffusion and Classifier models to operate in a black-box setting. We employ CMA-ES to optimize the search for an initial seed vector, which, when processed by the Conditional Diffusion Model, results in the natural adversarial sample misclassified by the Classifier Model. Experiments show that generated adversarial images are of high image quality, raising concerns about generating harmful content bypassing safety classifiers. Our research opens new avenues to understanding the limitations of current safety mechanisms and the risk of plausible attacks against classifier systems using image generation. Project Website can be accessed at: https://shashankkotyan.github.io/EvoSeed.
Read more5/24/2024
🤖
0
AdvDiff: Generating Unrestricted Adversarial Examples using Diffusion Models
Xuelong Dai, Kaisheng Liang, Bin Xiao
Unrestricted adversarial attacks present a serious threat to deep learning models and adversarial defense techniques. They pose severe security problems for deep learning applications because they can effectively bypass defense mechanisms. However, previous attack methods often directly inject Projected Gradient Descent (PGD) gradients into the sampling of generative models, which are not theoretically provable and thus generate unrealistic examples by incorporating adversarial objectives, especially for GAN-based methods on large-scale datasets like ImageNet. In this paper, we propose a new method, called AdvDiff, to generate unrestricted adversarial examples with diffusion models. We design two novel adversarial guidance techniques to conduct adversarial sampling in the reverse generation process of diffusion models. These two techniques are effective and stable in generating high-quality, realistic adversarial examples by integrating gradients of the target classifier interpretably. Experimental results on MNIST and ImageNet datasets demonstrate that AdvDiff is effective in generating unrestricted adversarial examples, which outperforms state-of-the-art unrestricted adversarial attack methods in terms of attack performance and generation quality.
Read more7/16/2024

0
EvolBA: Evolutionary Boundary Attack under Hard-label Black Box condition
Ayane Tajima, Satoshi Ono
Research has shown that deep neural networks (DNNs) have vulnerabilities that can lead to the misrecognition of Adversarial Examples (AEs) with specifically designed perturbations. Various adversarial attack methods have been proposed to detect vulnerabilities under hard-label black box (HL-BB) conditions in the absence of loss gradients and confidence scores.However, these methods fall into local solutions because they search only local regions of the search space. Therefore, this study proposes an adversarial attack method named EvolBA to generate AEs using Covariance Matrix Adaptation Evolution Strategy (CMA-ES) under the HL-BB condition, where only a class label predicted by the target DNN model is available. Inspired by formula-driven supervised learning, the proposed method introduces domain-independent operators for the initialization process and a jump that enhances search exploration. Experimental results confirmed that the proposed method could determine AEs with smaller perturbations than previous methods in images where the previous methods have difficulty.
Read more7/10/2024
📉
0
To Generate or Not? Safety-Driven Unlearned Diffusion Models Are Still Easy To Generate Unsafe Images ... For Now
Yimeng Zhang, Jinghan Jia, Xin Chen, Aochuan Chen, Yihua Zhang, Jiancheng Liu, Ke Ding, Sijia Liu
The recent advances in diffusion models (DMs) have revolutionized the generation of realistic and complex images. However, these models also introduce potential safety hazards, such as producing harmful content and infringing data copyrights. Despite the development of safety-driven unlearning techniques to counteract these challenges, doubts about their efficacy persist. To tackle this issue, we introduce an evaluation framework that leverages adversarial prompts to discern the trustworthiness of these safety-driven DMs after they have undergone the process of unlearning harmful concepts. Specifically, we investigated the adversarial robustness of DMs, assessed by adversarial prompts, when eliminating unwanted concepts, styles, and objects. We develop an effective and efficient adversarial prompt generation approach for DMs, termed UnlearnDiffAtk. This method capitalizes on the intrinsic classification abilities of DMs to simplify the creation of adversarial prompts, thereby eliminating the need for auxiliary classification or diffusion models. Through extensive benchmarking, we evaluate the robustness of widely-used safety-driven unlearned DMs (i.e., DMs after unlearning undesirable concepts, styles, or objects) across a variety of tasks. Our results demonstrate the effectiveness and efficiency merits of UnlearnDiffAtk over the state-of-the-art adversarial prompt generation method and reveal the lack of robustness of current safetydriven unlearning techniques when applied to DMs. Codes are available at https://github.com/OPTML-Group/Diffusion-MU-Attack. WARNING: There exist AI generations that may be offensive in nature.
Read more7/9/2024