Dredge Word, Social Media, and Webgraph Networks for Unreliable Website Classification and Identification

0
Sign in to get full access
Overview
- This paper explores the use of dredge word analysis, social media data, and web graph networks to classify and identify unreliable websites.
- The researchers developed a novel approach to detect misinformation and low-quality websites by leveraging various data sources and machine learning techniques.
- The paper presents a comprehensive study on the effectiveness of this approach in distinguishing between reliable and unreliable websites, with potential applications in misinformation-resilient search rankings, fake news detection, and other areas of online content moderation.
Plain English Explanation
The paper focuses on the problem of identifying unreliable or low-quality websites on the internet. These types of websites can be a source of misinformation, propaganda, or other harmful content that can mislead or manipulate readers.
To address this issue, the researchers used a combination of different data sources and analysis techniques. They looked at the actual words and language used on the websites (dredge word analysis), the way these websites are discussed and shared on social media, and the network of links between different websites (web graph networks).
By analyzing these different data sources, the researchers were able to develop a more comprehensive understanding of a website's reliability and quality. For example, websites that use a lot of sensationalized or emotionally charged language may be more likely to be spreading misinformation, while websites that are heavily shared and discussed on social media may be more trustworthy.
The researchers then used machine learning algorithms to automatically classify websites as either reliable or unreliable based on this data. This could be useful for misinformation-resilient search rankings, detecting fake news, and other applications where it's important to identify and filter out low-quality or unreliable online content.
Overall, this research represents an important step towards developing more effective tools for managing the spread of misinformation and low-quality information on the internet.
Technical Explanation
The paper proposes a novel approach for classifying and identifying unreliable websites by leveraging dredge word analysis, social media data, and web graph networks.
The researchers first collected a dataset of websites labeled as either reliable or unreliable based on a combination of manual and automated assessments. They then extracted various features from this dataset, including:
- Dredge word analysis: The researchers analyzed the language used on the websites, looking for the presence of sensationalized, emotionally-charged, or misleading words and phrases.
- Social media data: The researchers examined how these websites were discussed and shared on social media platforms, using metrics like engagement levels and sentiment analysis.
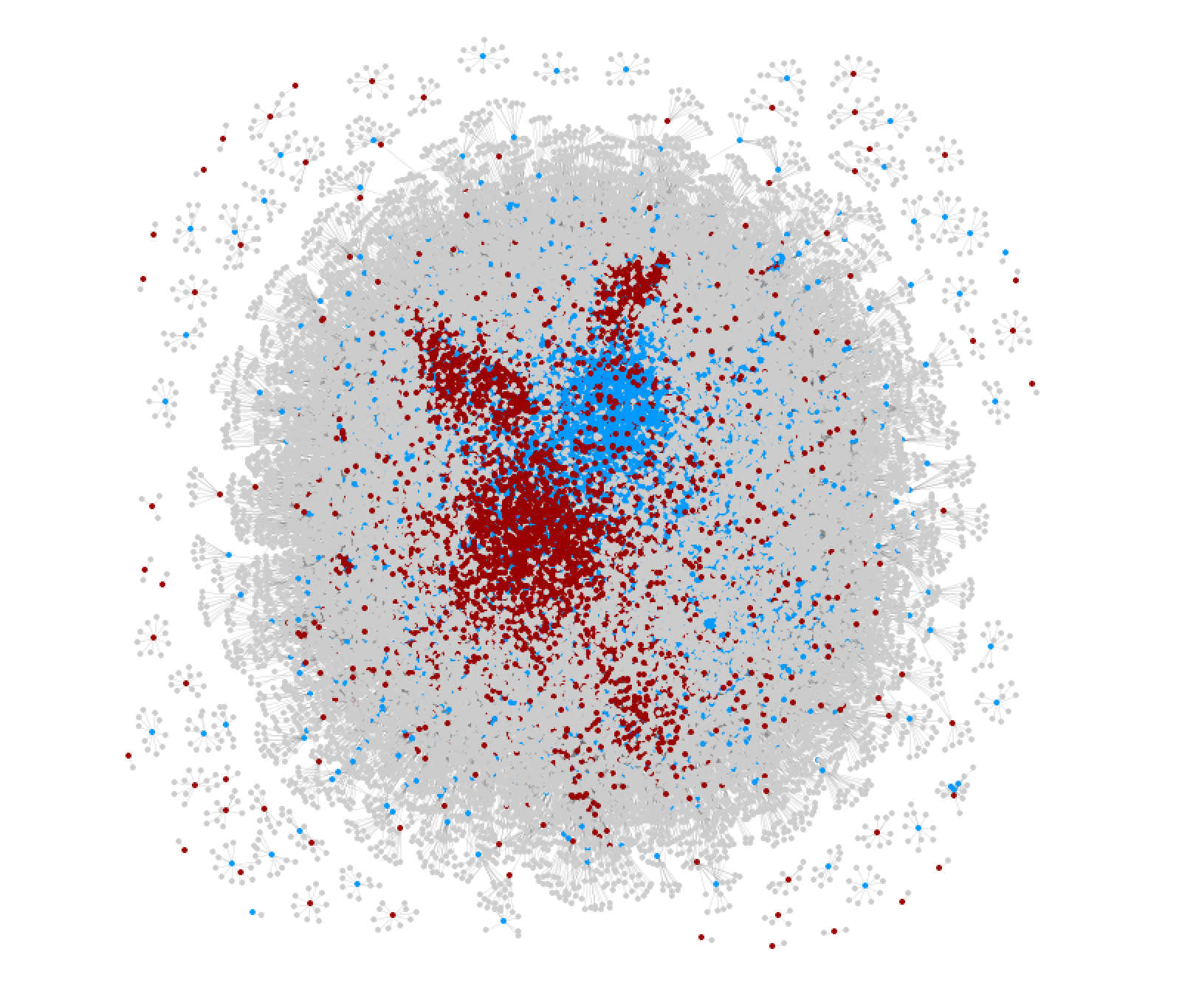
- Web graph networks: The researchers studied the network of links between the websites, looking for patterns that might indicate unreliable or low-quality sources.
Using these features, the researchers trained a series of machine learning models to classify the websites as either reliable or unreliable. They experimented with different algorithms, including logistic regression, decision trees, and random forests, and evaluated the performance of these models using various metrics, such as accuracy, precision, recall, and F1-score.
The results of their experiments showed that the combination of dredge word analysis, social media data, and web graph networks was effective in distinguishing between reliable and unreliable websites. The models achieved high levels of classification accuracy, demonstrating the potential of this approach for detecting fake news, early-stage debunking of rumors on Twitter, and other applications related to online content moderation.
Critical Analysis
The paper presents a comprehensive and well-designed study, with a clear methodology and robust experimental evaluation. However, there are a few potential limitations and areas for further research that could be considered:
- Generalizability: The dataset used in the study may not be fully representative of the diverse landscape of websites on the internet. It would be important to test the approach on a larger and more diverse set of websites to ensure its generalizability.
- Temporal dynamics: The paper does not address how website reliability and the associated features may change over time. Incorporating temporal analysis could provide valuable insights into the dynamic nature of online content.
- Ethical considerations: As with any system for content moderation, there are important ethical considerations around bias, fairness, and transparency that should be carefully examined.
- Real-world deployment: While the results are promising, the practical deployment of such a system would require addressing challenges related to scalability, real-time processing, and integration with existing content moderation workflows.
Overall, this paper presents a promising approach for classifying and identifying unreliable websites, with potential applications in misinformation-resilient search rankings, fake news detection, and other areas of online content moderation. The researchers have made a valuable contribution to the field, and the proposed techniques could be further refined and extended in future studies.
Conclusion
This paper introduces a novel approach for classifying and identifying unreliable websites by leveraging dredge word analysis, social media data, and web graph networks. The researchers demonstrate the effectiveness of this approach in distinguishing between reliable and unreliable websites, with potential applications in mitigating the spread of misinformation and low-quality content online.
The study represents an important step forward in the development of more sophisticated tools for online content moderation and curation. By combining multiple data sources and machine learning techniques, the researchers have created a more comprehensive and robust system for identifying unreliable websites, which could have significant implications for misinformation-resilient search rankings, fake news detection, and other areas of content moderation and analysis.
While the paper presents a promising approach, further research is needed to address the potential limitations and ethical considerations highlighted in the critical analysis. As the online landscape continues to evolve, the development of reliable and transparent systems for content moderation will become increasingly important for maintaining the integrity and trustworthiness of the internet.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dredge Word, Social Media, and Webgraph Networks for Unreliable Website Classification and Identification
Evan M. Williams, Peter Carragher, Kathleen M. Carley
Proactive content moderation requires platforms to rapidly and continuously evaluate the credibility of websites. Leveraging the direct and indirect paths users follow to unreliable websites, we develop a website credibility classification and discovery system that integrates both webgraph and large-scale social media contexts. We additionally introduce the concept of dredge words, terms or phrases for which unreliable domains rank highly on search engines, and provide the first exploration of their usage on social media. Our graph neural networks that combine webgraph and social media contexts generate to state-of-the-art results in website credibility classification and significantly improves the top-k identification of unreliable domains. Additionally, we release a novel dataset of dredge words, highlighting their strong connections to both social media and online commerce platforms.
Read more9/18/2024

0
Misinformation Resilient Search Rankings with Webgraph-based Interventions
Peter Carragher, Evan M. Williams, Kathleen M. Carley
The proliferation of unreliable news domains on the internet has had wide-reaching negative impacts on society. We introduce and evaluate interventions aimed at reducing traffic to unreliable news domains from search engines while maintaining traffic to reliable domains. We build these interventions on the principles of fairness (penalize sites for what is in their control), generality (label/fact-check agnostic), targeted (increase the cost of adversarial behavior), and scalability (works at webscale). We refine our methods on small-scale webdata as a testbed and then generalize the interventions to a large-scale webgraph containing 93.9M domains and 1.6B edges. We demonstrate that our methods penalize unreliable domains far more than reliable domains in both settings and we explore multiple avenues to mitigate unintended effects on both the small-scale and large-scale webgraph experiments. These results indicate the potential of our approach to reduce the spread of misinformation and foster a more reliable online information ecosystem. This research contributes to the development of targeted strategies to enhance the trustworthiness and quality of search engine results, ultimately benefiting users and the broader digital community.
Read more4/16/2024

0
Exposing and Explaining Fake News On-the-Fly
Francisco de Arriba-P'erez, Silvia Garc'ia-M'endez, F'atima Leal, Benedita Malheiro, Juan Carlos Burguillo
Social media platforms enable the rapid dissemination and consumption of information. However, users instantly consume such content regardless of the reliability of the shared data. Consequently, the latter crowdsourcing model is exposed to manipulation. This work contributes with an explainable and online classification method to recognize fake news in real-time. The proposed method combines both unsupervised and supervised Machine Learning approaches with online created lexica. The profiling is built using creator-, content- and context-based features using Natural Language Processing techniques. The explainable classification mechanism displays in a dashboard the features selected for classification and the prediction confidence. The performance of the proposed solution has been validated with real data sets from Twitter and the results attain 80 % accuracy and macro F-measure. This proposal is the first to jointly provide data stream processing, profiling, classification and explainability. Ultimately, the proposed early detection, isolation and explanation of fake news contribute to increase the quality and trustworthiness of social media contents.
Read more9/6/2024

0
Finding Fake News Websites in the Wild
Leandro Araujo, Joao M. M. Couto, Luiz Felipe Nery, Isadora C. Rodrigues, Jussara M. Almeida, Julio C. S. Reis, Fabricio Benevenuto
The battle against the spread of misinformation on the Internet is a daunting task faced by modern society. Fake news content is primarily distributed through digital platforms, with websites dedicated to producing and disseminating such content playing a pivotal role in this complex ecosystem. Therefore, these websites are of great interest to misinformation researchers. However, obtaining a comprehensive list of websites labeled as producers and/or spreaders of misinformation can be challenging, particularly in developing countries. In this study, we propose a novel methodology for identifying websites responsible for creating and disseminating misinformation content, which are closely linked to users who share confirmed instances of fake news on social media. We validate our approach on Twitter by examining various execution modes and contexts. Our findings demonstrate the effectiveness of the proposed methodology in identifying misinformation websites, which can aid in gaining a better understanding of this phenomenon and enabling competent entities to tackle the problem in various areas of society.
Read more7/16/2024