Can Large Language Models Assess Serendipity in Recommender Systems?
2404.07499
0
0
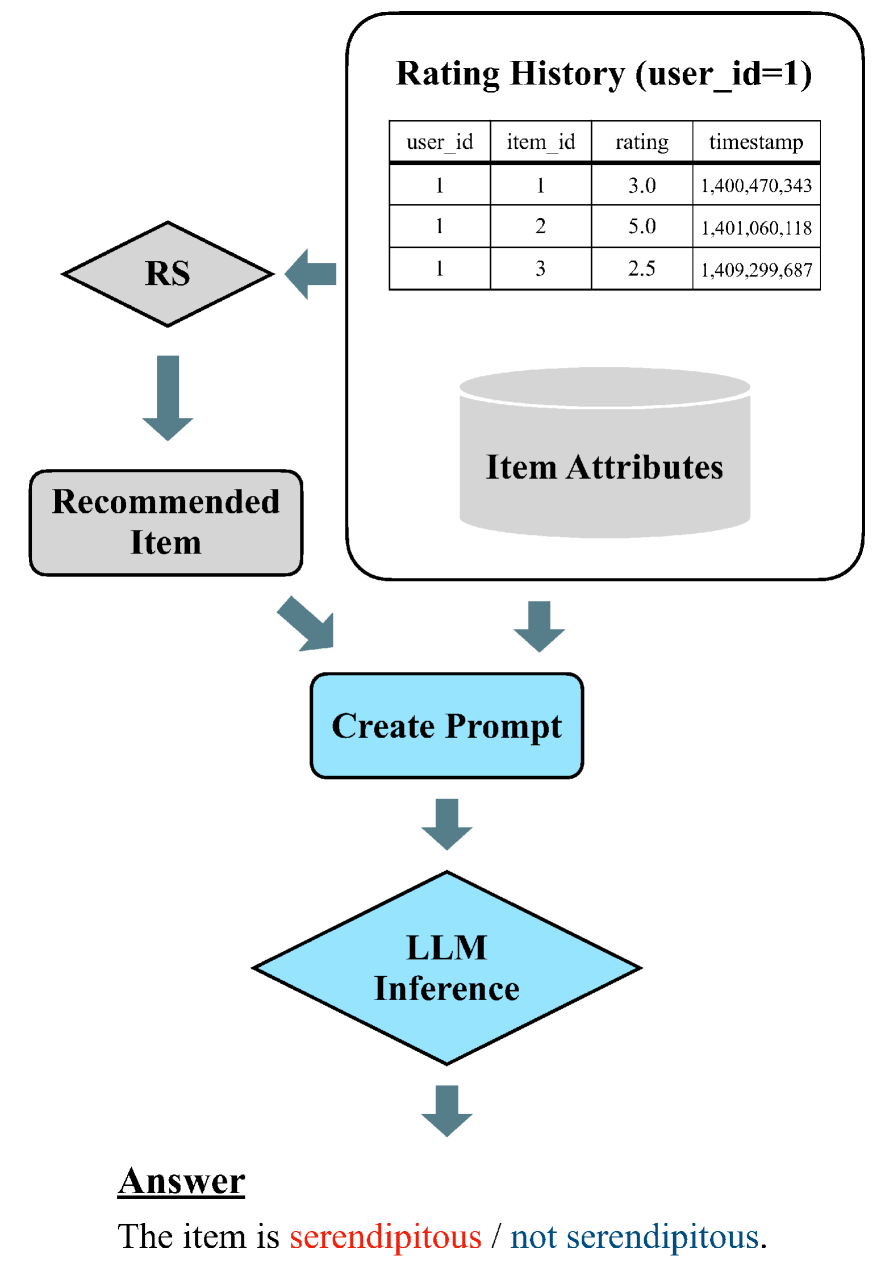
Abstract
Serendipity-oriented recommender systems aim to counteract over-specialization in user preferences. However, evaluating a user's serendipitous response towards a recommended item can be challenging because of its emotional nature. In this study, we address this issue by leveraging the rich knowledge of large language models (LLMs), which can perform a variety of tasks. First, this study explored the alignment between serendipitous evaluations made by LLMs and those made by humans. In this investigation, a binary classification task was given to the LLMs to predict whether a user would find the recommended item serendipitously. The predictive performances of three LLMs on a benchmark dataset in which humans assigned the ground truth of serendipitous items were measured. The experimental findings reveal that LLM-based assessment methods did not have a very high agreement rate with human assessments. However, they performed as well as or better than the baseline methods. Further validation results indicate that the number of user rating histories provided to LLM prompts should be carefully chosen to avoid both insufficient and excessive inputs and that the output of LLMs that show high classification performance is difficult to interpret.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper investigates whether large language models (LLMs) can be used to assess the serendipity of recommendations in recommender systems.
- Serendipity refers to the ability of a recommender system to suggest unexpected yet relevant and valuable items to users.
- Assessing serendipity is a challenging task, and the paper explores if LLMs can be leveraged to address this challenge.
Plain English Explanation
Recommender systems are software tools that suggest products, services, or content to users based on their preferences and past behavior. These systems aim to provide personalized recommendations that are relevant and useful to the user.
One important aspect of a good recommender system is its ability to suggest unexpected yet valuable items, a quality known as "serendipity." Serendipitous recommendations can introduce users to new and interesting things they may not have discovered on their own, leading to a more engaging and enriching experience.
However, measuring serendipity is a complex task, as it involves evaluating the novelty, relevance, and value of recommendations from the user's perspective. This paper explores whether large language models (LLMs) - powerful AI systems trained on vast amounts of text data - can be leveraged to assess the serendipity of recommendations.
The researchers investigate if LLMs can accurately capture the user's perception of serendipity, which could help improve the design and evaluation of recommender systems. By using LLMs to assess serendipity, the researchers aim to make this important quality more measurable and actionable for developers of recommender systems.
Technical Explanation
The paper begins by reviewing the existing research on serendipity in recommender systems, highlighting the challenges in defining and measuring this elusive quality. The authors note that while several approaches have been proposed, there is still a need for more robust and scalable methods to assess serendipity.
To address this, the researchers explore the use of large language models (LLMs) as a tool for evaluating serendipity. LLMs, such as GPT-3, are AI systems trained on massive amounts of text data, which allows them to understand and generate human-like language. The authors hypothesize that LLMs could be used to capture the nuanced and subjective nature of serendipity, as they are skilled at understanding context and interpreting the semantic meaning of text.
The paper presents a series of experiments where the researchers use an LLM to assess the serendipity of recommended items in two real-world datasets. They compare the LLM's serendipity scores to human judgments, as well as other existing serendipity metrics, to evaluate the model's performance.
The results show that the LLM-based serendipity assessment correlates well with human evaluations, outperforming traditional serendipity metrics. The authors also demonstrate that the LLM-based approach can provide insights into the specific factors that contribute to serendipitous recommendations, such as the novelty and relevance of the recommended items.
Overall, the paper suggests that large language models have the potential to serve as a powerful tool for measuring and understanding serendipity in recommender systems. This could lead to the development of more effective and engaging recommendation algorithms that better cater to users' diverse interests and discovery needs.
Critical Analysis
The paper presents a novel and promising approach to assessing serendipity in recommender systems using large language models. The authors provide a thorough review of the existing research, highlighting the challenges in this area and the need for more robust and scalable solutions.
One of the key strengths of the paper is the strong experimental design, which involves comparing the LLM-based serendipity assessment to both human judgments and established serendipity metrics. This helps to validate the effectiveness of the proposed approach and provides insights into its potential advantages over other methods.
However, the paper does acknowledge some limitations of the LLM-based approach. For example, the authors note that the performance of the LLM may be influenced by the specific dataset and task at hand, and that further research is needed to understand the generalizability of the method.
Additionally, the paper does not delve into the potential biases or limitations of the language models themselves, which is an important consideration when using these systems for sensitive tasks such as evaluating user experiences. Future research could explore ways to mitigate these potential issues and ensure the fairness and reliability of the LLM-based serendipity assessment.
Overall, the paper represents a significant contribution to the field of recommender systems research, demonstrating the potential of large language models to address the challenge of measuring serendipity. The findings could have important implications for the design and optimization of recommender systems, ultimately leading to more engaging and valuable user experiences.
Conclusion
This paper explores the use of large language models (LLMs) to assess the serendipity of recommendations in recommender systems. Serendipity refers to the ability of a recommender system to suggest unexpected yet relevant and valuable items to users, which is a desirable quality but difficult to measure.
The researchers demonstrate that LLMs, with their deep understanding of language and context, can effectively capture the subjective and nuanced nature of serendipity. Their experiments show that an LLM-based serendipity assessment correlates well with human judgments and outperforms traditional serendipity metrics.
The findings suggest that leveraging LLMs could be a promising approach for measuring and understanding serendipity in recommender systems. This could lead to the development of more effective and engaging recommendation algorithms that better cater to users' diverse interests and discovery needs.
While the paper acknowledges some limitations of the LLM-based approach, it represents a significant step forward in addressing a longstanding challenge in the field of recommender systems research. The insights and methods presented in this work could have important implications for the design and optimization of recommender systems, ultimately enhancing the user experience and fostering serendipitous discoveries.
Related Papers
Recommender Systems in the Era of Large Language Models (LLMs)
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, Qing Li
0
0
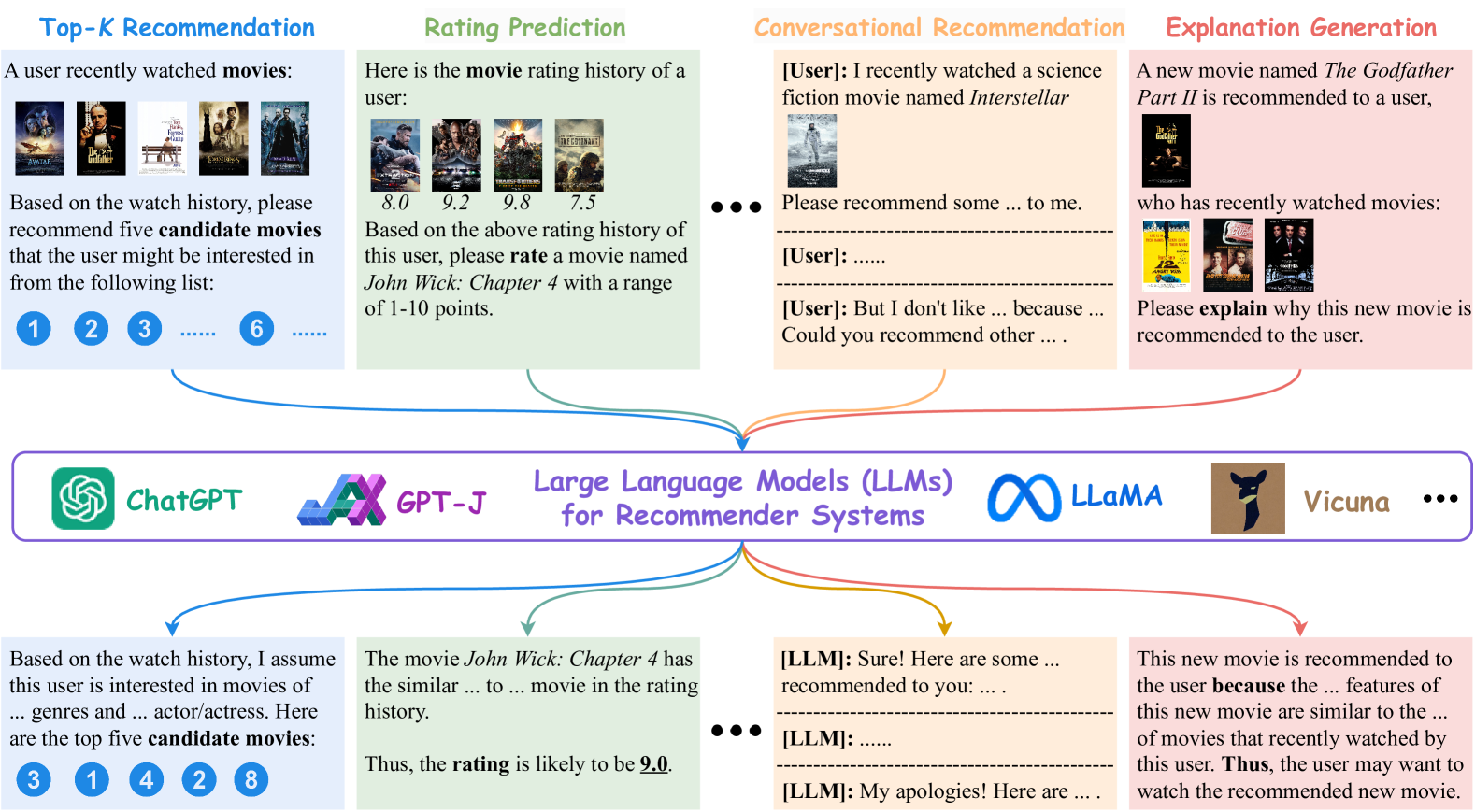
With the prosperity of e-commerce and web applications, Recommender Systems (RecSys) have become an important component of our daily life, providing personalized suggestions that cater to user preferences. While Deep Neural Networks (DNNs) have made significant advancements in enhancing recommender systems by modeling user-item interactions and incorporating textual side information, DNN-based methods still face limitations, such as difficulties in understanding users' interests and capturing textual side information, inabilities in generalizing to various recommendation scenarios and reasoning on their predictions, etc. Meanwhile, the emergence of Large Language Models (LLMs), such as ChatGPT and GPT4, has revolutionized the fields of Natural Language Processing (NLP) and Artificial Intelligence (AI), due to their remarkable abilities in fundamental responsibilities of language understanding and generation, as well as impressive generalization and reasoning capabilities. As a result, recent studies have attempted to harness the power of LLMs to enhance recommender systems. Given the rapid evolution of this research direction in recommender systems, there is a pressing need for a systematic overview that summarizes existing LLM-empowered recommender systems, to provide researchers in relevant fields with an in-depth understanding. Therefore, in this paper, we conduct a comprehensive review of LLM-empowered recommender systems from various aspects including Pre-training, Fine-tuning, and Prompting. More specifically, we first introduce representative methods to harness the power of LLMs (as a feature encoder) for learning representations of users and items. Then, we review recent techniques of LLMs for enhancing recommender systems from three paradigms, namely pre-training, fine-tuning, and prompting. Finally, we comprehensively discuss future directions in this emerging field.
4/23/2024
Large Language Models as Conversational Movie Recommenders: A User Study
Ruixuan Sun, Xinyi Li, Avinash Akella, Joseph A. Konstan
0
0
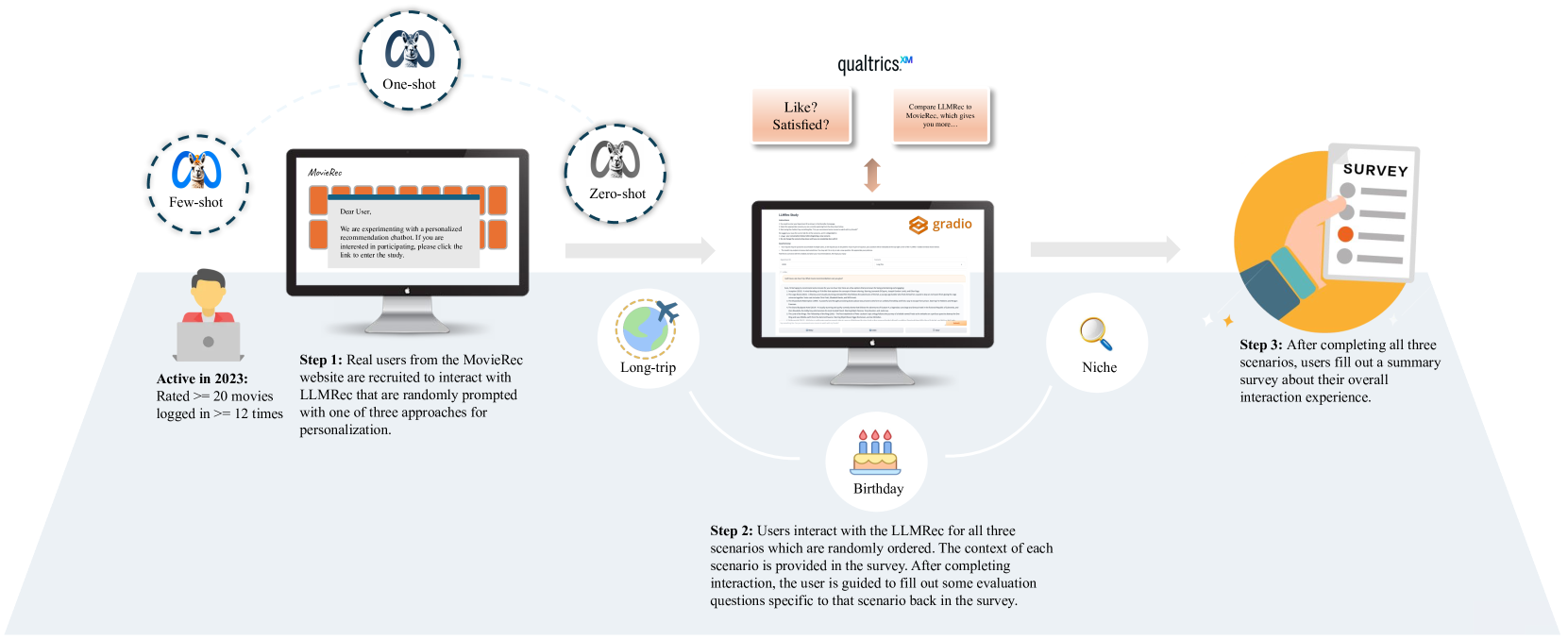
This paper explores the effectiveness of using large language models (LLMs) for personalized movie recommendations from users' perspectives in an online field experiment. Our study involves a combination of between-subject prompt and historic consumption assessments, along with within-subject recommendation scenario evaluations. By examining conversation and survey response data from 160 active users, we find that LLMs offer strong recommendation explainability but lack overall personalization, diversity, and user trust. Our results also indicate that different personalized prompting techniques do not significantly affect user-perceived recommendation quality, but the number of movies a user has watched plays a more significant role. Furthermore, LLMs show a greater ability to recommend lesser-known or niche movies. Through qualitative analysis, we identify key conversational patterns linked to positive and negative user interaction experiences and conclude that providing personal context and examples is crucial for obtaining high-quality recommendations from LLMs.
5/1/2024
💬
LLM-Rec: Personalized Recommendation via Prompting Large Language Models
Hanjia Lyu, Song Jiang, Hanqing Zeng, Yinglong Xia, Qifan Wang, Si Zhang, Ren Chen, Christopher Leung, Jiajie Tang, Jiebo Luo
0
0
Text-based recommendation holds a wide range of practical applications due to its versatility, as textual descriptions can represent nearly any type of item. However, directly employing the original item descriptions may not yield optimal recommendation performance due to the lack of comprehensive information to align with user preferences. Recent advances in large language models (LLMs) have showcased their remarkable ability to harness commonsense knowledge and reasoning. In this study, we introduce a novel approach, coined LLM-Rec, which incorporates four distinct prompting strategies of text enrichment for improving personalized text-based recommendations. Our empirical experiments reveal that using LLM-augmented text significantly enhances recommendation quality. Even basic MLP (Multi-Layer Perceptron) models achieve comparable or even better results than complex content-based methods. Notably, the success of LLM-Rec lies in its prompting strategies, which effectively tap into the language model's comprehension of both general and specific item characteristics. This highlights the importance of employing diverse prompts and input augmentation techniques to boost the recommendation effectiveness of LLMs.
4/3/2024
Large Language Models are Inconsistent and Biased Evaluators
Rickard Stureborg, Dimitris Alikaniotis, Yoshi Suhara
0
0
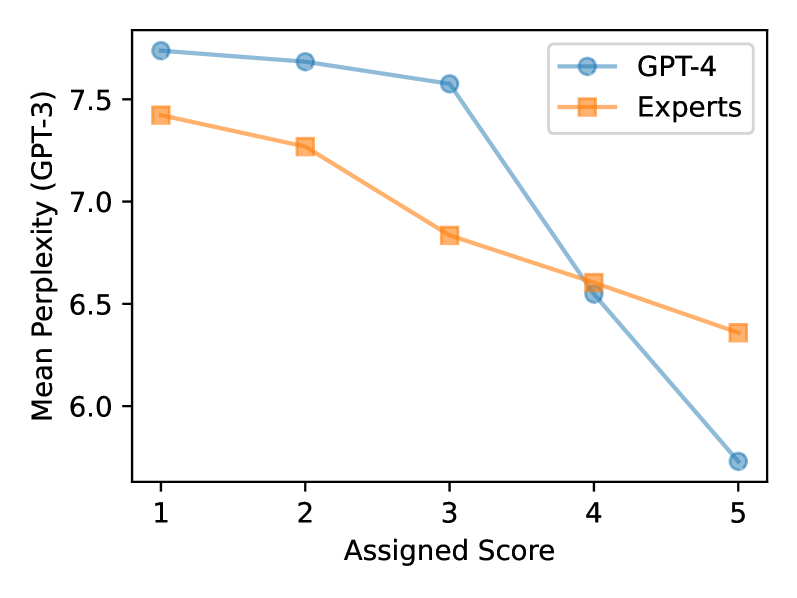
The zero-shot capability of Large Language Models (LLMs) has enabled highly flexible, reference-free metrics for various tasks, making LLM evaluators common tools in NLP. However, the robustness of these LLM evaluators remains relatively understudied; existing work mainly pursued optimal performance in terms of correlating LLM scores with human expert scores. In this paper, we conduct a series of analyses using the SummEval dataset and confirm that LLMs are biased evaluators as they: (1) exhibit familiarity bias-a preference for text with lower perplexity, (2) show skewed and biased distributions of ratings, and (3) experience anchoring effects for multi-attribute judgments. We also found that LLMs are inconsistent evaluators, showing low inter-sample agreement and sensitivity to prompt differences that are insignificant to human understanding of text quality. Furthermore, we share recipes for configuring LLM evaluators to mitigate these limitations. Experimental results on the RoSE dataset demonstrate improvements over the state-of-the-art LLM evaluators.
5/6/2024