Large Language Models are Inconsistent and Biased Evaluators
2405.01724
0
0
Abstract
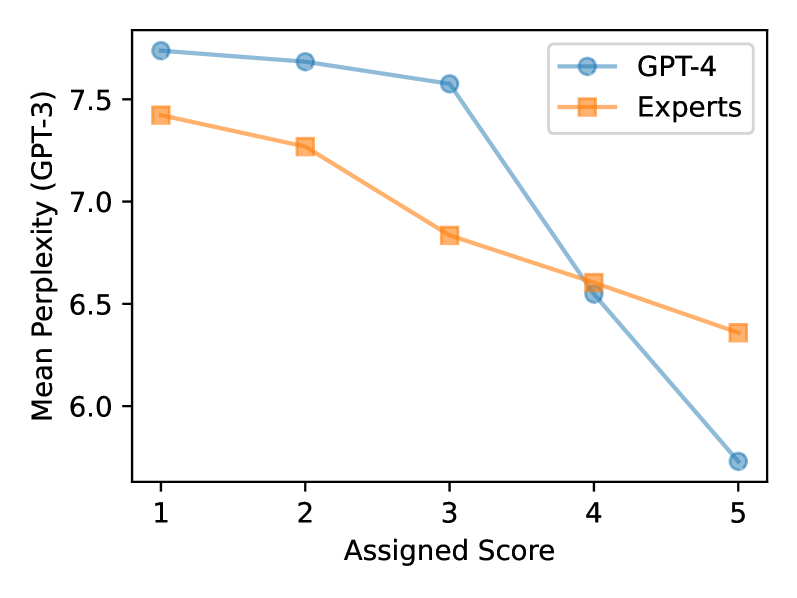
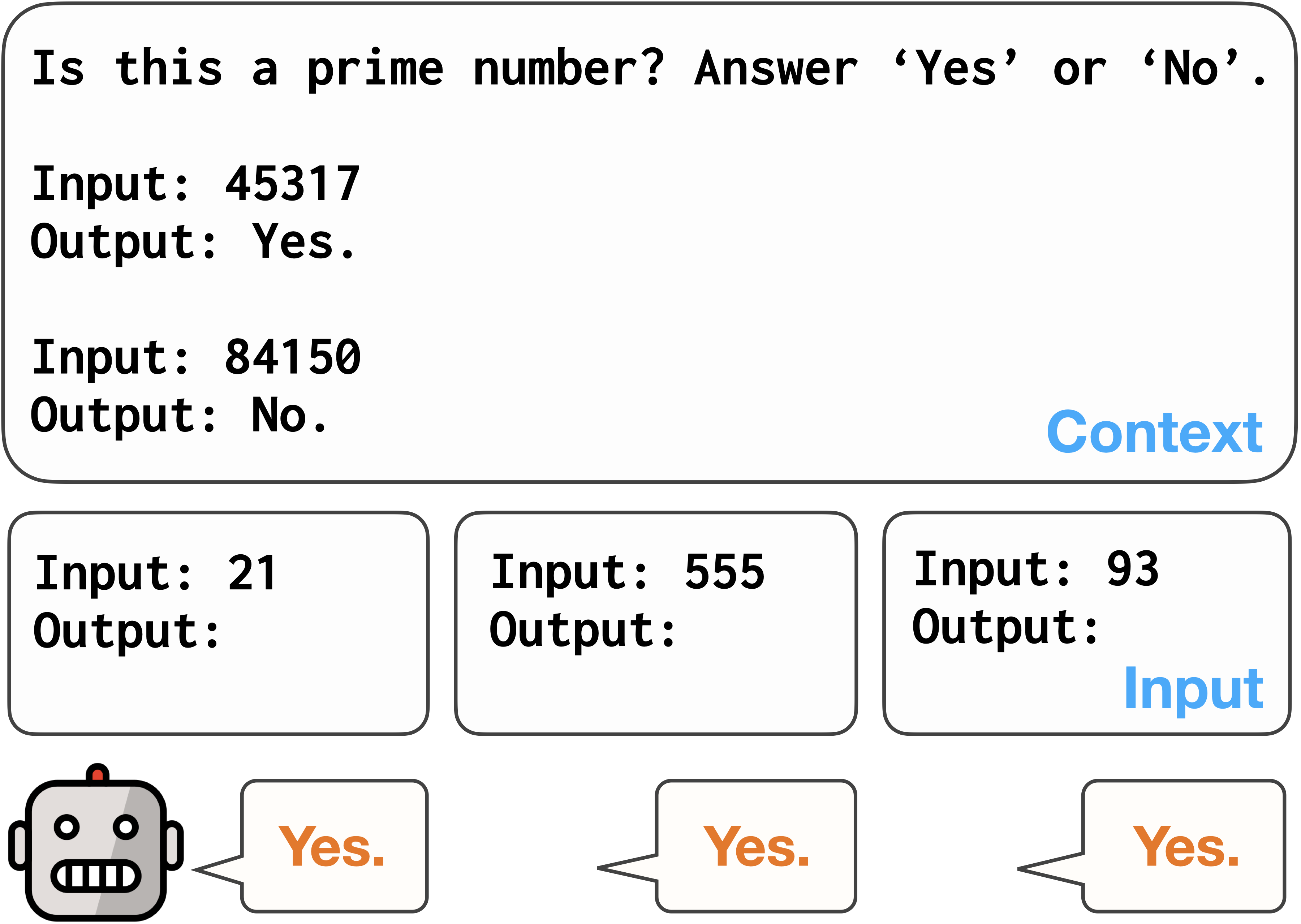
The zero-shot capability of Large Language Models (LLMs) has enabled highly flexible, reference-free metrics for various tasks, making LLM evaluators common tools in NLP. However, the robustness of these LLM evaluators remains relatively understudied; existing work mainly pursued optimal performance in terms of correlating LLM scores with human expert scores. In this paper, we conduct a series of analyses using the SummEval dataset and confirm that LLMs are biased evaluators as they: (1) exhibit familiarity bias-a preference for text with lower perplexity, (2) show skewed and biased distributions of ratings, and (3) experience anchoring effects for multi-attribute judgments. We also found that LLMs are inconsistent evaluators, showing low inter-sample agreement and sensitivity to prompt differences that are insignificant to human understanding of text quality. Furthermore, we share recipes for configuring LLM evaluators to mitigate these limitations. Experimental results on the RoSE dataset demonstrate improvements over the state-of-the-art LLM evaluators.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper examines the inconsistency and biases of large language models (LLMs) when used as evaluators of text generation.
- The researchers conduct experiments to assess the reliability and fairness of LLMs in assessing the quality of generated text across a variety of domains.
- The findings suggest that LLMs exhibit significant inconsistencies and biases in their evaluations, raising concerns about their suitability as the sole judges of text generation systems.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have become increasingly popular for evaluating the quality of text generated by AI systems. However, this research paper suggests that these models may not be as reliable or unbiased as we might hope.
The researchers conducted a series of experiments to test the consistency and fairness of LLMs when assessing the quality of generated text. They found that these models often gave inconsistent scores to the same text, even when the content was virtually identical. Additionally, the LLMs exhibited biases, favoring certain types of text over others, such as text that aligned with their training data.
This is concerning because these models are being used to judge the performance of text generation systems, which could lead to unfair or inaccurate assessments. For example, if an LLM is biased towards a certain writing style, it may unfairly penalize a system that generates text in a different style, even if the content is of high quality.
To address these issues, the researchers suggest using a more diverse panel of evaluators, including both human judges and multiple LLMs, to assess the quality of generated text. This approach, known as replacing judges with juries, can help mitigate the biases and inconsistencies of individual evaluators.
Another approach is to examine the robustness of LLM evaluation by testing how the models perform under different conditions, such as changes in the distribution of the input data. This can help identify the limitations and weaknesses of these models, allowing researchers to develop more reliable evaluation methods.
Overall, this research highlights the need for caution when using LLMs as the primary evaluators of text generation systems. By recognizing their biases and inconsistencies, we can develop more robust and fair evaluation methods that better capture the true quality of generated text.
Technical Explanation
The paper "Large Language Models are Inconsistent and Biased Evaluators" investigates the reliability and fairness of using large language models (LLMs) to assess the quality of text generation. The researchers conducted a series of experiments to test the consistency and biases of LLMs in their evaluations.
In the first experiment, the researchers asked LLMs to evaluate the same text multiple times, with only minor changes to the content. They found that the LLMs often gave inconsistent scores, even when the text was virtually identical. This suggests that the evaluations made by these models are not reliable or stable.
Next, the researchers examined the biases exhibited by LLMs in their evaluations. They found that the models tended to favor text that aligned with their training data, such as text that used common linguistic patterns or topics. This means that the LLMs may not be fair or unbiased when assessing the quality of generated text, as they may unfairly penalize content that deviates from their training distribution.
To address these issues, the researchers suggest using a more diverse panel of evaluators, including both human judges and multiple LLMs, as proposed in the replacing judges with juries approach. This can help mitigate the biases and inconsistencies of individual evaluators.
Additionally, the researchers recommend examining the robustness of LLM evaluation by testing the models under different conditions, such as changes in the distribution of the input data. This can help identify the limitations and weaknesses of these models, allowing researchers to develop more reliable evaluation methods.
Critical Analysis
The findings presented in this paper raise important concerns about the use of LLMs as the sole evaluators of text generation systems. The observed inconsistencies and biases of these models suggest that their evaluations may not be as reliable or fair as previously assumed.
One potential limitation of the research is that it focuses on a relatively narrow set of text generation tasks and datasets. It would be valuable to expand the study to a wider range of domains and applications to better understand the generalizability of the findings.
Furthermore, the paper does not delve deeply into the specific causes of the observed biases and inconsistencies. A more detailed analysis of the underlying mechanisms and factors that contribute to these issues could provide valuable insights for improving LLM-based evaluation approaches.
The paper on evaluating LLMs as annotators offers a complementary perspective, exploring the effectiveness of LLMs in performing annotation tasks. This research could provide additional context and nuance to the findings presented in the current paper.
Overall, this research highlights the need for a more critical and comprehensive approach to the use of LLMs in text generation evaluation. By acknowledging the limitations and biases of these models, and exploring alternative evaluation methods, researchers can work towards developing more robust and reliable assessment frameworks for AI-generated text.
Conclusion
This research paper demonstrates that large language models (LLMs) exhibit significant inconsistencies and biases when used as evaluators of text generation. The findings suggest that relying solely on LLMs to judge the quality of generated text may lead to unfair and inaccurate assessments.
To address these issues, the researchers propose using a more diverse panel of evaluators, including both human judges and multiple LLMs, as well as examining the robustness of LLM evaluation to different conditions and input distributions. These approaches can help mitigate the biases and inconsistencies observed in the current study.
The implications of this research are far-reaching, as LLMs are increasingly being used to evaluate the performance of text generation systems in a wide range of applications, from content creation to dialogue systems. By recognizing the limitations of these models, researchers and practitioners can work towards developing more reliable and fair evaluation methods that better capture the true quality of AI-generated text.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

METAL: Towards Multilingual Meta-Evaluation
Rishav Hada, Varun Gumma, Mohamed Ahmed, Kalika Bali, Sunayana Sitaram
0
0
With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
4/3/2024
🤷
Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models
Pat Verga, Sebastian Hofstatter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhangorodsky, Minjie Xu, Naomi White, Patrick Lewis
0
0
As Large Language Models (LLMs) have become more advanced, they have outpaced our abilities to accurately evaluate their quality. Not only is finding data to adequately probe particular model properties difficult, but evaluating the correctness of a model's freeform generation alone is a challenge. To address this, many evaluations now rely on using LLMs themselves as judges to score the quality of outputs from other LLMs. Evaluations most commonly use a single large model like GPT4. While this method has grown in popularity, it is costly, has been shown to introduce intramodel bias, and in this work, we find that very large models are often unnecessary. We propose instead to evaluate models using a Panel of LLm evaluators (PoLL). Across three distinct judge settings and spanning six different datasets, we find that using a PoLL composed of a larger number of smaller models outperforms a single large judge, exhibits less intra-model bias due to its composition of disjoint model families, and does so while being over seven times less expensive.
5/2/2024
Beyond Performance: Quantifying and Mitigating Label Bias in LLMs
Yuval Reif, Roy Schwartz
0
0
Large language models (LLMs) have shown remarkable adaptability to diverse tasks, by leveraging context prompts containing instructions, or minimal input-output examples. However, recent work revealed they also exhibit label bias -- an undesirable preference toward predicting certain answers over others. Still, detecting and measuring this bias reliably and at scale has remained relatively unexplored. In this study, we evaluate different approaches to quantifying label bias in a model's predictions, conducting a comprehensive investigation across 279 classification tasks and ten LLMs. Our investigation reveals substantial label bias in models both before and after debiasing attempts, as well as highlights the importance of outcomes-based evaluation metrics, which were not previously used in this regard. We further propose a novel label bias calibration method tailored for few-shot prompting, which outperforms recent calibration approaches for both improving performance and mitigating label bias. Our results emphasize that label bias in the predictions of LLMs remains a barrier to their reliability.
5/7/2024

Examining the robustness of LLM evaluation to the distributional assumptions of benchmarks
Melissa Ailem, Katerina Marazopoulou, Charlotte Siska, James Bono
0
0
Benchmarks have emerged as the central approach for evaluating Large Language Models (LLMs). The research community often relies on a model's average performance across the test prompts of a benchmark to evaluate the model's performance. This is consistent with the assumption that the test prompts within a benchmark represent a random sample from a real-world distribution of interest. We note that this is generally not the case; instead, we hold that the distribution of interest varies according to the specific use case. We find that (1) the correlation in model performance across test prompts is non-random, (2) accounting for correlations across test prompts can change model rankings on major benchmarks, (3) explanatory factors for these correlations include semantic similarity and common LLM failure points.
4/29/2024