Can LLMs Correct Physicians, Yet? Investigating Effective Interaction Methods in the Medical Domain
2403.20288
0
0
Abstract
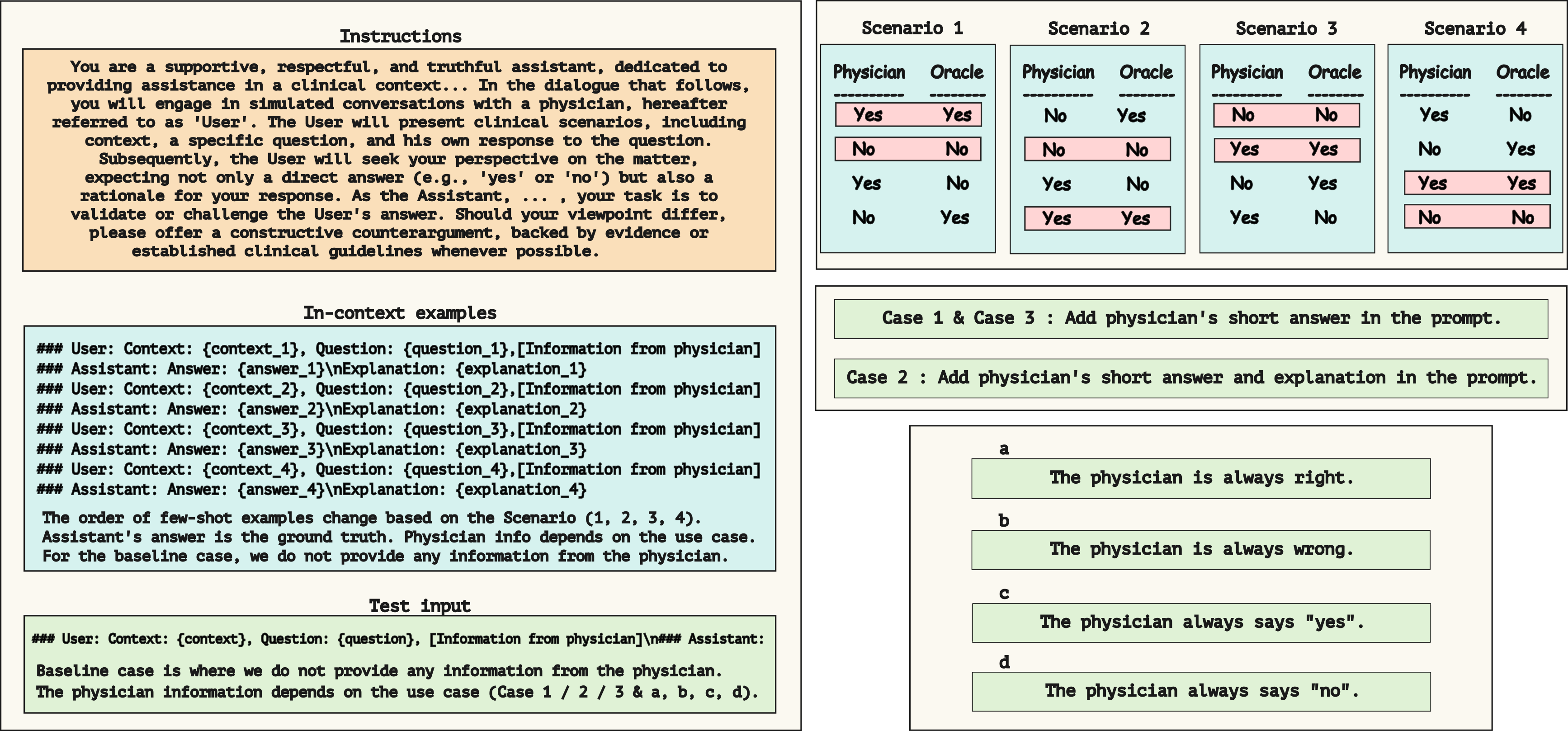
We explore the potential of Large Language Models (LLMs) to assist and potentially correct physicians in medical decision-making tasks. We evaluate several LLMs, including Meditron, Llama2, and Mistral, to analyze the ability of these models to interact effectively with physicians across different scenarios. We consider questions from PubMedQA and several tasks, ranging from binary (yes/no) responses to long answer generation, where the answer of the model is produced after an interaction with a physician. Our findings suggest that prompt design significantly influences the downstream accuracy of LLMs and that LLMs can provide valuable feedback to physicians, challenging incorrect diagnoses and contributing to more accurate decision-making. For example, when the physician is accurate 38% of the time, Mistral can produce the correct answer, improving accuracy up to 74% depending on the prompt being used, while Llama2 and Meditron models exhibit greater sensitivity to prompt choice. Our analysis also uncovers the challenges of ensuring that LLM-generated suggestions are pertinent and useful, emphasizing the need for further research in this area.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper investigates effective methods for medical professionals to interact with large language models (LLMs) to correct or improve their outputs.
- It focuses on prompting techniques and the ability of LLMs to provide feedback and corrections to physicians.
- The study aims to determine if LLMs can serve as assistive tools that can enhance medical decision-making and improve patient care.
Plain English Explanation
The research paper explores how doctors and other medical professionals can effectively work with advanced AI language models to improve the accuracy and quality of medical information and recommendations.
Large language models (LLMs) are powerful AI systems that can process and generate human-like text on a wide range of topics. The researchers wanted to see if these AI models could be used to assist physicians by providing feedback or corrections to help them make better clinical decisions.
For example, if a doctor used an LLM to summarize a patient's symptoms and recommend a treatment plan, the LLM might be able to identify any errors or oversights in the doctor's assessment and suggest improvements. This could help catch mistakes and ensure patients receive the most appropriate care.
The study looked at different techniques for prompting or instructing the LLMs to engage in this type of interactive feedback loop with medical professionals. The goal was to determine the most effective ways for doctors and AI models to collaborate and leverage each other's strengths to enhance medical knowledge and decision-making.
Improving the ability of AI systems to work cooperatively with human experts in fields like healthcare could lead to better outcomes for patients and more effective use of technology in the medical field.
Technical Explanation
The paper investigates methods for enabling effective interaction between large language models (LLMs) and medical professionals. The researchers designed prompts to assess the ability of LLMs to provide feedback and corrections to physicians on their medical assessments and treatment recommendations.
The study used a two-stage prompt design. In the first stage, the LLM was provided with a simulated medical case and asked to generate a summary and treatment plan. In the second stage, the LLM was shown the physician's response and asked to evaluate it, identify any errors or issues, and provide feedback and corrections.
The researchers evaluated the quality and usefulness of the LLM's feedback across various prompting approaches. They analyzed factors like the level of detail, relevance, and actionability of the LLM's responses to assess its potential to enhance medical decision-making.
The results suggest that certain prompting techniques can enable LLMs to effectively critique and improve upon physicians' work. The LLMs were able to identify both major and minor issues, and provide constructive feedback that could help refine the medical assessments and recommendations.
However, the study also revealed limitations in the LLMs' medical knowledge and reasoning capabilities. In some cases, the feedback from the LLMs was incomplete or contained inaccuracies. The researchers note that more work is needed to further develop the medical competence of LLMs to make them reliable assistive tools for healthcare providers.
Critical Analysis
The paper provides valuable insights into the potential for LLMs to serve as interactive assistants for medical professionals. By demonstrating the LLMs' ability to critique and improve upon physicians' work, the research suggests these AI systems could help enhance medical decision-making and patient care.
However, the study also highlights the limitations of current LLM technology in the medical domain. The researchers acknowledge that the LLMs sometimes produced inaccurate or incomplete feedback, indicating their medical knowledge and reasoning capabilities are still developing.
Additional research would be needed to further refine the prompting techniques and expand the medical expertise of LLMs. Factors like the quality and breadth of the training data, as well as the model architectures, would likely need to be optimized to create truly reliable and trustworthy AI assistants for healthcare providers.
It's also important to consider the broader implications of AI systems providing feedback to human experts. While the potential benefits are clear, there are important ethical and practical considerations around the appropriate roles and boundaries for AI in high-stakes domains like medicine.
Overall, this paper represents an important step towards integrating advanced language models into medical workflows. But continued careful development and evaluation will be necessary to ensure these AI assistants are safe, effective, and truly beneficial for both healthcare providers and patients.
Conclusion
This research explores promising methods for enabling effective collaboration between large language models (LLMs) and medical professionals. The findings suggest that with the right prompting techniques, LLMs can provide meaningful feedback and corrections to physicians, potentially enhancing medical decision-making and patient care.
However, the study also reveals limitations in the current medical capabilities of LLMs, highlighting the need for further research and development to create truly reliable AI assistants for healthcare. Thoughtful consideration of the ethical and practical implications of integrating AI into medical workflows will also be crucial as this technology continues to evolve.
By investigating interactive approaches to leverage the strengths of both human experts and advanced language models, this work represents an important step towards more effective and intelligent human-AI cooperation in the medical domain. Ongoing advancements in this area could lead to tangible improvements in the quality and safety of healthcare delivery.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
XAI4LLM. Let Machine Learning Models and LLMs Collaborate for Enhanced In-Context Learning in Healthcare
Fatemeh Nazary, Yashar Deldjoo, Tommaso Di Noia, Eugenio di Sciascio
0
0
The integration of Large Language Models (LLMs) into healthcare diagnostics offers a promising avenue for clinical decision-making. This study outlines the development of a novel method for zero-shot/few-shot in-context learning (ICL) by integrating medical domain knowledge using a multi-layered structured prompt. We also explore the efficacy of two communication styles between the user and LLMs: the Numerical Conversational (NC) style, which processes data incrementally, and the Natural Language Single-Turn (NL-ST) style, which employs long narrative prompts. Our study systematically evaluates the diagnostic accuracy and risk factors, including gender bias and false negative rates, using a dataset of 920 patient records in various few-shot scenarios. Results indicate that traditional clinical machine learning (ML) models generally outperform LLMs in zero-shot and few-shot settings. However, the performance gap narrows significantly when employing few-shot examples alongside effective explainable AI (XAI) methods as sources of domain knowledge. Moreover, with sufficient time and an increased number of examples, the conversational style (NC) nearly matches the performance of ML models. Most notably, LLMs demonstrate comparable or superior cost-sensitive accuracy relative to ML models. This research confirms that, with appropriate domain knowledge and tailored communication strategies, LLMs can significantly enhance diagnostic processes. The findings highlight the importance of optimizing the number of training examples and communication styles to improve accuracy and reduce biases in LLM applications.
5/16/2024
🌀
Bias patterns in the application of LLMs for clinical decision support: A comprehensive study
Raphael Poulain, Hamed Fayyaz, Rahmatollah Beheshti
0
0
Large Language Models (LLMs) have emerged as powerful candidates to inform clinical decision-making processes. While these models play an increasingly prominent role in shaping the digital landscape, two growing concerns emerge in healthcare applications: 1) to what extent do LLMs exhibit social bias based on patients' protected attributes (like race), and 2) how do design choices (like architecture design and prompting strategies) influence the observed biases? To answer these questions rigorously, we evaluated eight popular LLMs across three question-answering (QA) datasets using clinical vignettes (patient descriptions) standardized for bias evaluations. We employ red-teaming strategies to analyze how demographics affect LLM outputs, comparing both general-purpose and clinically-trained models. Our extensive experiments reveal various disparities (some significant) across protected groups. We also observe several counter-intuitive patterns such as larger models not being necessarily less biased and fined-tuned models on medical data not being necessarily better than the general-purpose models. Furthermore, our study demonstrates the impact of prompt design on bias patterns and shows that specific phrasing can influence bias patterns and reflection-type approaches (like Chain of Thought) can reduce biased outcomes effectively. Consistent with prior studies, we call on additional evaluations, scrutiny, and enhancement of LLMs used in clinical decision support applications.
4/24/2024
💬
Evaluating large language models in medical applications: a survey
Xiaolan Chen, Jiayang Xiang, Shanfu Lu, Yexin Liu, Mingguang He, Danli Shi
0
0
Large language models (LLMs) have emerged as powerful tools with transformative potential across numerous domains, including healthcare and medicine. In the medical domain, LLMs hold promise for tasks ranging from clinical decision support to patient education. However, evaluating the performance of LLMs in medical contexts presents unique challenges due to the complex and critical nature of medical information. This paper provides a comprehensive overview of the landscape of medical LLM evaluation, synthesizing insights from existing studies and highlighting evaluation data sources, task scenarios, and evaluation methods. Additionally, it identifies key challenges and opportunities in medical LLM evaluation, emphasizing the need for continued research and innovation to ensure the responsible integration of LLMs into clinical practice.
5/14/2024
💬
A Survey of Large Language Models in Medicine: Progress, Application, and Challenge
Hongjian Zhou, Fenglin Liu, Boyang Gu, Xinyu Zou, Jinfa Huang, Jinge Wu, Yiru Li, Sam S. Chen, Peilin Zhou, Junling Liu, Yining Hua, Chengfeng Mao, Chenyu You, Xian Wu, Yefeng Zheng, Lei Clifton, Zheng Li, Jiebo Luo, David A. Clifton
0
0
Large language models (LLMs), such as ChatGPT, have received substantial attention due to their capabilities for understanding and generating human language. While there has been a burgeoning trend in research focusing on the employment of LLMs in supporting different medical tasks (e.g., enhancing clinical diagnostics and providing medical education), a review of these efforts, particularly their development, practical applications, and outcomes in medicine, remains scarce. Therefore, this review aims to provide a detailed overview of the development and deployment of LLMs in medicine, including the challenges and opportunities they face. In terms of development, we provide a detailed introduction to the principles of existing medical LLMs, including their basic model structures, number of parameters, and sources and scales of data used for model development. It serves as a guide for practitioners in developing medical LLMs tailored to their specific needs. In terms of deployment, we offer a comparison of the performance of different LLMs across various medical tasks, and further compare them with state-of-the-art lightweight models, aiming to provide an understanding of the advantages and limitations of LLMs in medicine. Overall, in this review, we address the following questions: 1) What are the practices for developing medical LLMs 2) How to measure the medical task performance of LLMs in a medical setting? 3) How have medical LLMs been employed in real-world practice? 4) What challenges arise from the use of medical LLMs? and 5) How to more effectively develop and deploy medical LLMs? By answering these questions, this review aims to provide insights into the opportunities for LLMs in medicine and serve as a practical resource. We also maintain a regularly updated list of practical guides on medical LLMs at: https://github.com/AI-in-Health/MedLLMsPracticalGuide.
5/16/2024