Bias patterns in the application of LLMs for clinical decision support: A comprehensive study
2404.15149
0
0
🌀
Abstract
Large Language Models (LLMs) have emerged as powerful candidates to inform clinical decision-making processes. While these models play an increasingly prominent role in shaping the digital landscape, two growing concerns emerge in healthcare applications: 1) to what extent do LLMs exhibit social bias based on patients' protected attributes (like race), and 2) how do design choices (like architecture design and prompting strategies) influence the observed biases? To answer these questions rigorously, we evaluated eight popular LLMs across three question-answering (QA) datasets using clinical vignettes (patient descriptions) standardized for bias evaluations. We employ red-teaming strategies to analyze how demographics affect LLM outputs, comparing both general-purpose and clinically-trained models. Our extensive experiments reveal various disparities (some significant) across protected groups. We also observe several counter-intuitive patterns such as larger models not being necessarily less biased and fined-tuned models on medical data not being necessarily better than the general-purpose models. Furthermore, our study demonstrates the impact of prompt design on bias patterns and shows that specific phrasing can influence bias patterns and reflection-type approaches (like Chain of Thought) can reduce biased outcomes effectively. Consistent with prior studies, we call on additional evaluations, scrutiny, and enhancement of LLMs used in clinical decision support applications.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large Language Models (LLMs) are increasingly being used to assist in clinical decision-making, but two concerns have emerged:
- To what extent do LLMs exhibit social bias based on patients' protected attributes (like race)?
- How do design choices (like architecture and prompting strategies) influence the observed biases?
Plain English Explanation
Large Language Models (LLMs) are powerful computer programs that can understand and generate human-like text. They are starting to be used in healthcare to help doctors make decisions, but there are concerns about whether these models might be biased against certain groups of patients.
The researchers wanted to investigate two main questions:
- Bias: Do LLMs show different behavior or responses based on a patient's race, gender, or other protected characteristics?
- Design choices: How do the way the LLMs are built and the instructions given to them (called "prompts") affect the biases that appear in their outputs?
To answer these questions, the researchers evaluated eight popular LLMs using clinical test cases that were designed to assess bias. They looked at both general-purpose LLMs and ones that had been specially trained on medical data. The researchers used advanced techniques, like "red-teaming", to try to uncover biases in how the LLMs responded.
Technical Explanation
The researchers conducted a comprehensive evaluation of eight prominent LLMs across three clinical question-answering (QA) datasets. They used standardized patient vignettes (detailed descriptions) that were designed to assess bias based on protected attributes like race.
The team employed advanced "red-teaming" strategies to systematically analyze how the demographics of the patients affected the LLMs' outputs. They compared the biases exhibited by general-purpose LLMs versus those that had been fine-tuned on medical data.
The experiments revealed significant disparities in the LLMs' responses across different protected groups. Interestingly, the researchers observed some counterintuitive patterns, such as larger models not necessarily being less biased and fine-tuned medical models not always outperforming general-purpose LLMs.
Furthermore, the study demonstrated the substantial impact of prompt design on bias patterns. The researchers found that specific phrasing in the prompts could influence the biases, and that "reflection-type" approaches (like Chain of Thought) were effective in reducing biased outcomes.
Critical Analysis
The paper is a rigorous and important contribution to the growing body of research on bias in LLMs, particularly in the context of clinical decision-making. The authors' use of standardized vignettes and advanced evaluation techniques provides valuable insights into the complex relationship between model design, prompting, and biased outputs.
However, the study also highlights the need for further research and scrutiny. As the authors note, the findings suggest that simply fine-tuning LLMs on medical data may not be sufficient to eliminate biases, and that more targeted approaches to mitigating bias may be required.
Additionally, the paper does not delve deeply into the potential societal implications of these biases in clinical settings, nor does it provide clear guidance on how to address them. Future research could explore these areas further and propose more concrete solutions for safely deploying LLMs in healthcare applications.
Conclusion
This study underscores the pressing need to thoroughly evaluate the biases in LLMs, especially when they are being used in high-stakes domains like healthcare. The findings highlight the complex interplay between model design, prompting, and biased outputs, and call for increased scrutiny and enhancement of these systems before they are widely deployed.
As LLMs continue to advance and play a more prominent role in clinical decision-making, it is crucial that researchers, healthcare providers, and policymakers work together to ensure these powerful tools are used responsibly and equitably.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Evaluating large language models in medical applications: a survey
Xiaolan Chen, Jiayang Xiang, Shanfu Lu, Yexin Liu, Mingguang He, Danli Shi
0
0
Large language models (LLMs) have emerged as powerful tools with transformative potential across numerous domains, including healthcare and medicine. In the medical domain, LLMs hold promise for tasks ranging from clinical decision support to patient education. However, evaluating the performance of LLMs in medical contexts presents unique challenges due to the complex and critical nature of medical information. This paper provides a comprehensive overview of the landscape of medical LLM evaluation, synthesizing insights from existing studies and highlighting evaluation data sources, task scenarios, and evaluation methods. Additionally, it identifies key challenges and opportunities in medical LLM evaluation, emphasizing the need for continued research and innovation to ensure the responsible integration of LLMs into clinical practice.
5/14/2024
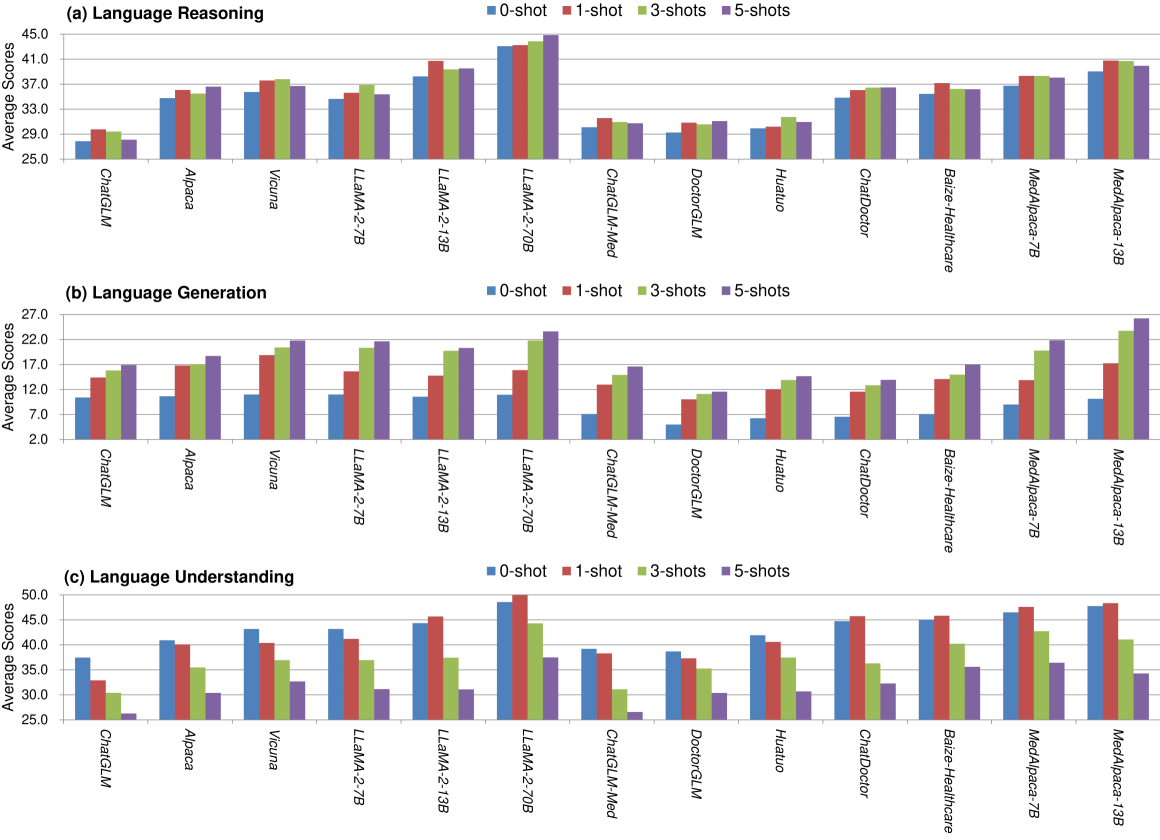
Large Language Models in Healthcare: A Comprehensive Benchmark
Andrew Liu, Hongjian Zhou, Yining Hua, Omid Rohanian, Lei Clifton, David A. Clifton
0
0
The adoption of large language models (LLMs) to assist clinicians has attracted remarkable attention. Existing works mainly adopt the close-ended question-answering task with answer options for evaluation. However, in real clinical settings, many clinical decisions, such as treatment recommendations, involve answering open-ended questions without pre-set options. Meanwhile, existing studies mainly use accuracy to assess model performance. In this paper, we comprehensively benchmark diverse LLMs in healthcare, to clearly understand their strengths and weaknesses. Our benchmark contains seven tasks and thirteen datasets across medical language generation, understanding, and reasoning. We conduct a detailed evaluation of the existing sixteen LLMs in healthcare under both zero-shot and few-shot (i.e., 1,3,5-shot) learning settings. We report the results on five metrics (i.e. matching, faithfulness, comprehensiveness, generalizability, and robustness) that are critical in achieving trust from clinical users. We further invite medical experts to conduct human evaluation.
5/3/2024
💬
Apprentices to Research Assistants: Advancing Research with Large Language Models
M. Namvarpour, A. Razi
0
0
Large Language Models (LLMs) have emerged as powerful tools in various research domains. This article examines their potential through a literature review and firsthand experimentation. While LLMs offer benefits like cost-effectiveness and efficiency, challenges such as prompt tuning, biases, and subjectivity must be addressed. The study presents insights from experiments utilizing LLMs for qualitative analysis, highlighting successes and limitations. Additionally, it discusses strategies for mitigating challenges, such as prompt optimization techniques and leveraging human expertise. This study aligns with the 'LLMs as Research Tools' workshop's focus on integrating LLMs into HCI data work critically and ethically. By addressing both opportunities and challenges, our work contributes to the ongoing dialogue on their responsible application in research.
4/10/2024
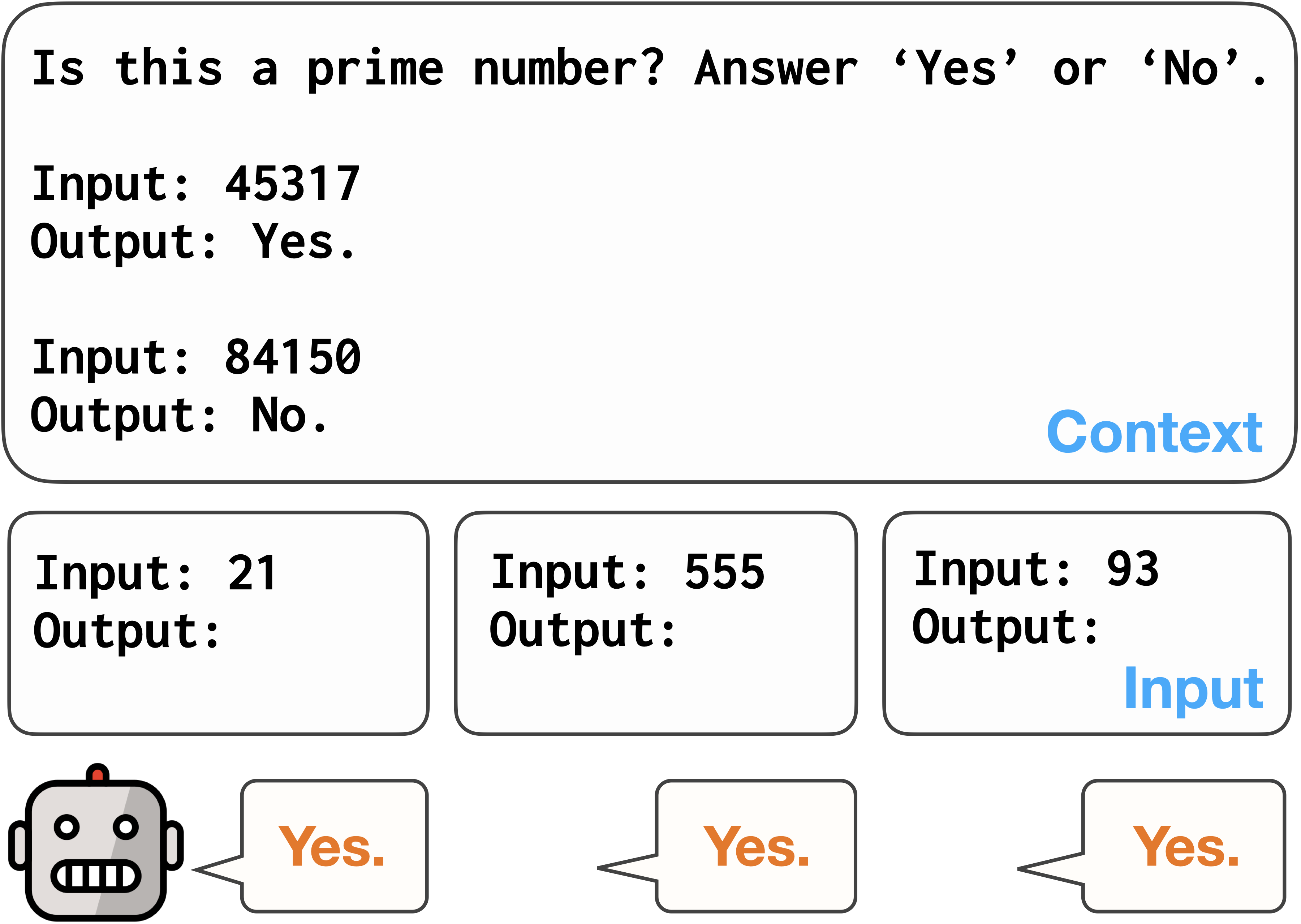
Beyond Performance: Quantifying and Mitigating Label Bias in LLMs
Yuval Reif, Roy Schwartz
0
0
Large language models (LLMs) have shown remarkable adaptability to diverse tasks, by leveraging context prompts containing instructions, or minimal input-output examples. However, recent work revealed they also exhibit label bias -- an undesirable preference toward predicting certain answers over others. Still, detecting and measuring this bias reliably and at scale has remained relatively unexplored. In this study, we evaluate different approaches to quantifying label bias in a model's predictions, conducting a comprehensive investigation across 279 classification tasks and ten LLMs. Our investigation reveals substantial label bias in models both before and after debiasing attempts, as well as highlights the importance of outcomes-based evaluation metrics, which were not previously used in this regard. We further propose a novel label bias calibration method tailored for few-shot prompting, which outperforms recent calibration approaches for both improving performance and mitigating label bias. Our results emphasize that label bias in the predictions of LLMs remains a barrier to their reliability.
5/7/2024