Can LLMs Deeply Detect Complex Malicious Queries? A Framework for Jailbreaking via Obfuscating Intent
2405.03654
0
0
🤷
Abstract
To demonstrate and address the underlying maliciousness, we propose a theoretical hypothesis and analytical approach, and introduce a new black-box jailbreak attack methodology named IntentObfuscator, exploiting this identified flaw by obfuscating the true intentions behind user prompts.This approach compels LLMs to inadvertently generate restricted content, bypassing their built-in content security measures. We detail two implementations under this framework: Obscure Intention and Create Ambiguity, which manipulate query complexity and ambiguity to evade malicious intent detection effectively. We empirically validate the effectiveness of the IntentObfuscator method across several models, including ChatGPT-3.5, ChatGPT-4, Qwen and Baichuan, achieving an average jailbreak success rate of 69.21%. Notably, our tests on ChatGPT-3.5, which claims 100 million weekly active users, achieved a remarkable success rate of 83.65%. We also extend our validation to diverse types of sensitive content like graphic violence, racism, sexism, political sensitivity, cybersecurity threats, and criminal skills, further proving the substantial impact of our findings on enhancing 'Red Team' strategies against LLM content security frameworks.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Proposes a new "IntentObfuscator" attack methodology that can bypass content security measures in large language models (LLMs) like ChatGPT
- Introduces two attack implementations: "Obscure Intention" and "Create Ambiguity"
- Demonstrates the effectiveness of these attacks across multiple LLM models, achieving success rates up to 83.65%
- Validates the attacks on diverse types of sensitive content like violence, racism, and cybersecurity threats
Plain English Explanation
The paper describes a new technique called "IntentObfuscator" that can trick large language models (LLMs) like ChatGPT into generating restricted or harmful content. The idea is to obfuscate the true intention behind the user's prompts, making the LLM think the request is benign when it's actually malicious.
The researchers implement two specific approaches under this framework: "Obscure Intention" and "Create Ambiguity". The "Obscure Intention" method makes the prompt more complex to hide the true intent, while "Create Ambiguity" adds ambiguity to the prompt to bypass the LLM's security checks.
When tested, the IntentObfuscator method was able to successfully bypass the content security measures of several LLMs, including ChatGPT-3.5, ChatGPT-4, Qwen, and Baichuan. The average success rate across these models was 69.21%, and the success rate on ChatGPT-3.5 (which has over 100 million weekly users) was an impressive 83.65%.
The researchers also validated the attacks on diverse types of sensitive content, like graphic violence, racism, sexism, political topics, cybersecurity threats, and criminal skills. This shows the significant impact these techniques could have on enhancing "Red Team" (adversarial) strategies against the content security frameworks of LLMs.
Technical Explanation
The paper proposes a new "IntentObfuscator" attack methodology that can bypass the content security measures of large language models (LLMs) like ChatGPT. The key idea is to obfuscate the true intentions behind user prompts, compelling the LLMs to inadvertently generate restricted content.
The researchers introduce two specific attack implementations under this framework:
-
Obscure Intention: This approach manipulates the complexity of the prompt to hide the true malicious intent. By making the prompt more convoluted, the LLM's security checks can be evaded.
-
Create Ambiguity: This method introduces ambiguity into the prompt, making it difficult for the LLM's intent detection system to accurately identify the underlying malicious goal.
The researchers empirically validate the effectiveness of the IntentObfuscator method across several LLM models, including ChatGPT-3.5, ChatGPT-4, Qwen, and Baichuan. The average jailbreak success rate across these models was 69.21%, with ChatGPT-3.5 achieving a remarkable 83.65% success rate.
Additionally, the researchers extend the validation to diverse types of sensitive content, such as graphic violence, racism, sexism, political sensitivity, cybersecurity threats, and criminal skills. This comprehensive evaluation demonstrates the substantial impact of the IntentObfuscator method on enhancing "Red Team" strategies against the content security frameworks of LLMs.
Critical Analysis
The research presented in this paper raises several important considerations. While the IntentObfuscator technique showcases the potential vulnerabilities in the content security measures of LLMs, the ethical implications of such attacks must be carefully weighed.
The high success rates, especially on the widely-used ChatGPT-3.5 model, suggest that more robust security mechanisms may be necessary to prevent malicious actors from exploiting these kinds of vulnerabilities. The researchers acknowledge that further research is needed to develop more effective countermeasures against such jailbreak attacks.
Additionally, the ability to bypass content security on diverse types of sensitive content, including topics related to violence, racism, and cybersecurity, highlights the substantial potential impact of these techniques. The researchers argue that their findings could enhance "Red Team" strategies, but it is essential to consider the ethical implications and potential for misuse.
While the technical insights provided in the paper are valuable for researchers and security professionals, there are valid concerns about the broader societal impacts of such malicious intent and the ability to bypass intent analysis in LLMs. Responsible disclosure and the development of effective countermeasures should be prioritized to mitigate the risks posed by these types of attacks.
Conclusion
The paper presents a new "IntentObfuscator" attack methodology that can effectively bypass the content security measures of large language models (LLMs) like ChatGPT. The researchers introduce two specific attack implementations, "Obscure Intention" and "Create Ambiguity," which achieve high success rates across multiple LLM models, including an impressive 83.65% on ChatGPT-3.5.
The comprehensive validation of the attacks on diverse types of sensitive content, such as violence, racism, and cybersecurity threats, highlights the substantial potential impact of these techniques. While the technical insights are valuable, the ethical implications and risks of such malicious intent bypassing must be carefully considered.
Responsible disclosure and the development of effective countermeasures should be priorities, as the findings of this research could enhance "Red Team" strategies against LLM content security frameworks. Ongoing research and collaboration between the AI research community, security professionals, and policymakers will be crucial in addressing these challenges and ensuring the safe and responsible development of LLMs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Subtoxic Questions: Dive Into Attitude Change of LLM's Response in Jailbreak Attempts
Tianyu Zhang, Zixuan Zhao, Jiaqi Huang, Jingyu Hua, Sheng Zhong
0
0
As Large Language Models (LLMs) of Prompt Jailbreaking are getting more and more attention, it is of great significance to raise a generalized research paradigm to evaluate attack strengths and a basic model to conduct subtler experiments. In this paper, we propose a novel approach by focusing on a set of target questions that are inherently more sensitive to jailbreak prompts, aiming to circumvent the limitations posed by enhanced LLM security. Through designing and analyzing these sensitive questions, this paper reveals a more effective method of identifying vulnerabilities in LLMs, thereby contributing to the advancement of LLM security. This research not only challenges existing jailbreaking methodologies but also fortifies LLMs against potential exploits.
4/15/2024

Hidden You Malicious Goal Into Benigh Narratives: Jailbreak Large Language Models through Logic Chain Injection
Zhilong Wang, Yebo Cao, Peng Liu
0
0
Jailbreak attacks on Language Model Models (LLMs) entail crafting prompts aimed at exploiting the models to generate malicious content. Existing jailbreak attacks can successfully deceive the LLMs, however they cannot deceive the human. This paper proposes a new type of jailbreak attacks which can deceive both the LLMs and human (i.e., security analyst). The key insight of our idea is borrowed from the social psychology - that is human are easily deceived if the lie is hidden in truth. Based on this insight, we proposed the logic-chain injection attacks to inject malicious intention into benign truth. Logic-chain injection attack firstly dissembles its malicious target into a chain of benign narrations, and then distribute narrations into a related benign article, with undoubted facts. In this way, newly generate prompt cannot only deceive the LLMs, but also deceive human.
4/9/2024
💬
Do Anything Now: Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, Yang Zhang
0
0
The misuse of large language models (LLMs) has drawn significant attention from the general public and LLM vendors. One particular type of adversarial prompt, known as jailbreak prompt, has emerged as the main attack vector to bypass the safeguards and elicit harmful content from LLMs. In this paper, employing our new framework JailbreakHub, we conduct a comprehensive analysis of 1,405 jailbreak prompts spanning from December 2022 to December 2023. We identify 131 jailbreak communities and discover unique characteristics of jailbreak prompts and their major attack strategies, such as prompt injection and privilege escalation. We also observe that jailbreak prompts increasingly shift from online Web communities to prompt-aggregation websites and 28 user accounts have consistently optimized jailbreak prompts over 100 days. To assess the potential harm caused by jailbreak prompts, we create a question set comprising 107,250 samples across 13 forbidden scenarios. Leveraging this dataset, our experiments on six popular LLMs show that their safeguards cannot adequately defend jailbreak prompts in all scenarios. Particularly, we identify five highly effective jailbreak prompts that achieve 0.95 attack success rates on ChatGPT (GPT-3.5) and GPT-4, and the earliest one has persisted online for over 240 days. We hope that our study can facilitate the research community and LLM vendors in promoting safer and regulated LLMs.
5/16/2024
Intention Analysis Makes LLMs A Good Jailbreak Defender
Yuqi Zhang, Liang Ding, Lefei Zhang, Dacheng Tao
0
0
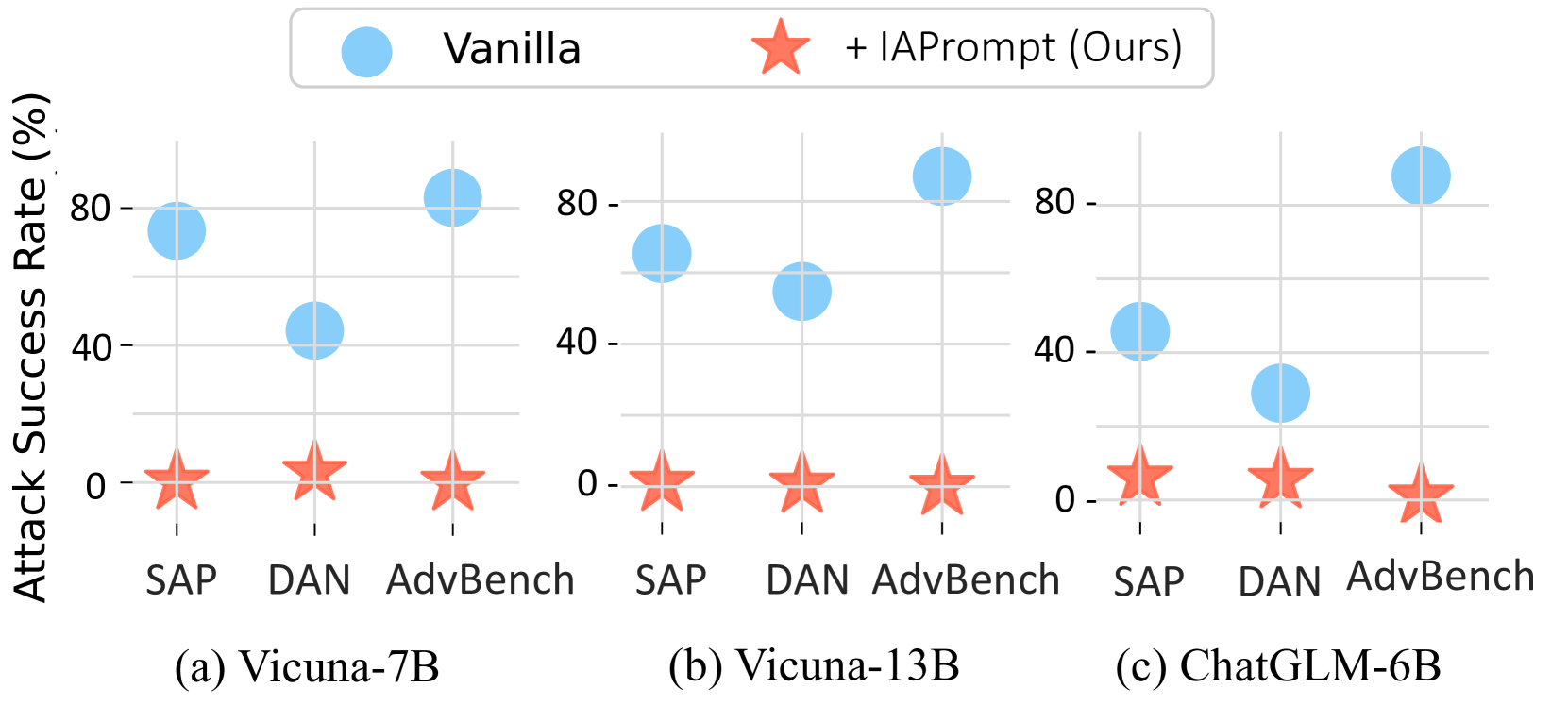
Aligning large language models (LLMs) with human values, particularly in the face of complex and stealthy jailbreak attacks, presents a formidable challenge. In this study, we present a simple yet highly effective defense strategy, i.e., Intention Analysis ($mathbb{IA}$). The principle behind this is to trigger LLMs' inherent self-correct and improve ability through a two-stage process: 1) essential intention analysis, and 2) policy-aligned response. Notably, $mathbb{IA}$ is an inference-only method, thus could enhance the safety of LLMs without compromising their helpfulness. Extensive experiments on varying jailbreak benchmarks across ChatGLM, LLaMA2, Vicuna, MPT, DeepSeek, and GPT-3.5 show that $mathbb{IA}$ could consistently and significantly reduce the harmfulness in responses (averagely -53.1% attack success rate) and maintain the general helpfulness. Encouragingly, with the help of our $mathbb{IA}$, Vicuna-7B even outperforms GPT-3.5 in terms of attack success rate. Further analyses present some insights into how our method works. To facilitate reproducibility, we release our code and scripts at: https://github.com/alphadl/SafeLLM_with_IntentionAnalysis.
4/30/2024