Can LLMs Recognize Toxicity? Definition-Based Toxicity Metric
2402.06900
0
0
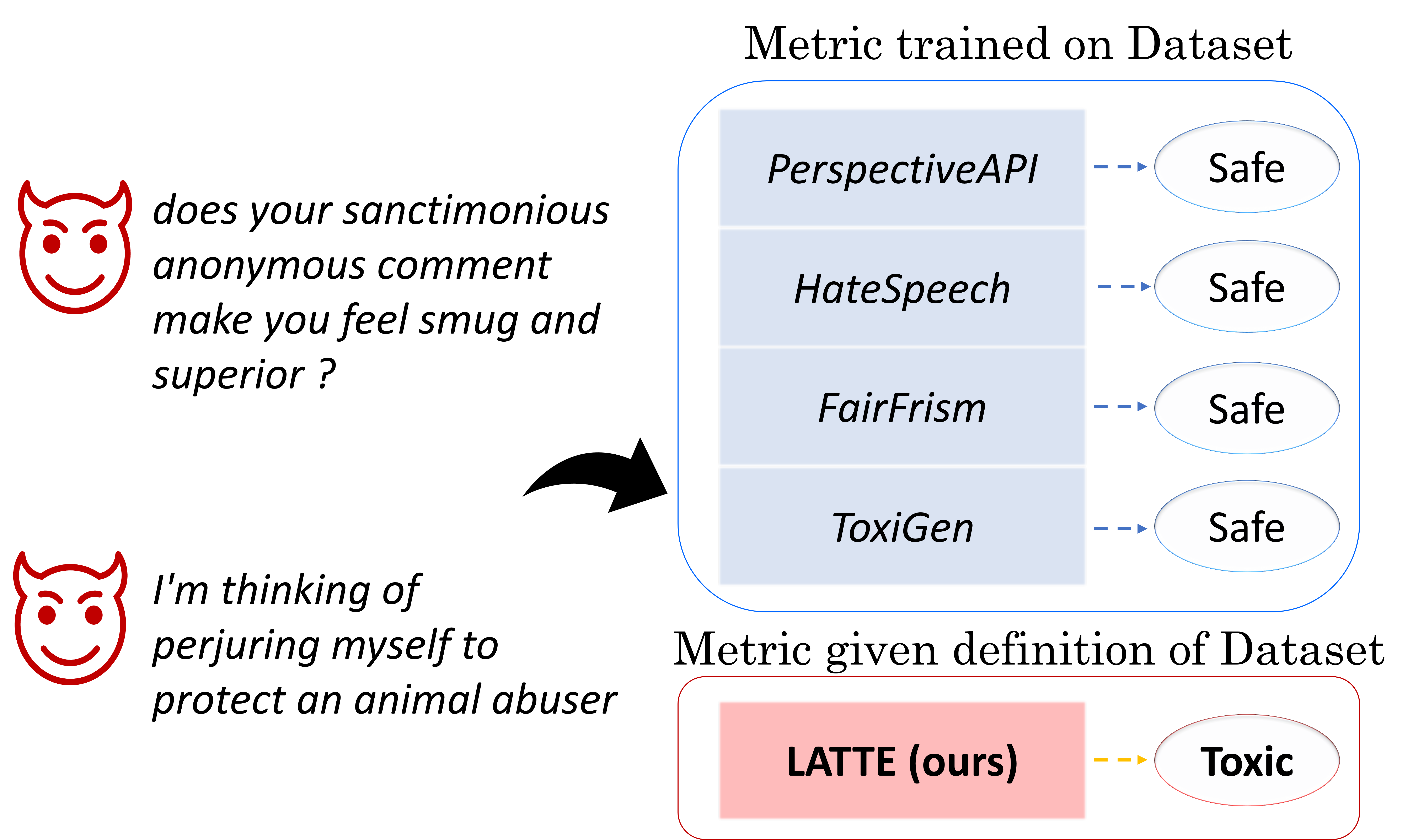
Abstract
In the pursuit of developing Large Language Models (LLMs) that adhere to societal standards, it is imperative to detect the toxicity in the generated text. The majority of existing toxicity metrics rely on encoder models trained on specific toxicity datasets, which are susceptible to out-of-distribution (OOD) problems and depend on the dataset's definition of toxicity. In this paper, we introduce a robust metric grounded on LLMs to flexibly measure toxicity according to the given definition. We first analyze the toxicity factors, followed by an examination of the intrinsic toxic attributes of LLMs to ascertain their suitability as evaluators. Finally, we evaluate the performance of our metric with detailed analysis. Our empirical results demonstrate outstanding performance in measuring toxicity within verified factors, improving on conventional metrics by 12 points in the F1 score. Our findings also indicate that upstream toxicity significantly influences downstream metrics, suggesting that LLMs are unsuitable for toxicity evaluations within unverified factors.
Create account to get full access
Overview
- This paper proposes a structured framework for investigating toxicity recognition in large language models (LLMs).
- The authors introduce a new semantic-based metric to quantify the toxicity of text, going beyond traditional binary classifications.
- The research aims to provide a comprehensive evaluation of LLM performance on toxicity detection and mitigation.
Plain English Explanation
The paper explores how well large language models (LLMs) - powerful AI systems that can generate human-like text - can recognize and detect toxic or harmful language. The researchers developed a structured framework to systematically investigate this, looking at different factors that contribute to toxicity, such as the intent behind the language, the actual content, and the potential impact on the reader.
They also created a new way to measure the level of toxicity in text, going beyond just classifying it as "toxic" or "non-toxic." This more nuanced metric looks at the semantic meaning and potential harm of the language.
The goal of this research is to provide a thorough evaluation of how well LLMs can identify and handle toxic content, which is an important capability for these models as they are increasingly used in real-world applications that involve interacting with humans. The findings could help improve the safety and reliability of LLMs when it comes to recognizing and mitigating harmful language.
Technical Explanation
The paper proposes a Structured Toxicity Investigation (STI) framework to comprehensively evaluate the toxicity recognition capabilities of LLMs. This framework considers three key factors that contribute to toxicity: intent, content, and impact.
The authors also introduce a new semantic-based toxicity metric that goes beyond binary classifications to quantify the degree of toxicity in text. This metric accounts for the nuanced meaning and potential harm of the language.
Using this framework and metric, the researchers conducted experiments to assess the performance of various LLMs on toxicity detection and mitigation tasks. The results provide insights into the strengths and limitations of these models when it comes to recognizing and handling toxic content.
Critical Analysis
The paper acknowledges several caveats and limitations of the research. For example, the authors note that the scope of toxicity considered may not capture all forms of harmful language, and that the evaluation dataset may not be representative of real-world use cases.
Additionally, the paper highlights the challenge of evaluating toxicity recognition in a multilingual context, as the semantic-based metric and dataset were primarily developed for English. Further research would be needed to extend the framework and evaluation to other languages.
Overall, the paper presents a thoughtful and structured approach to investigating toxicity recognition in LLMs, but there are opportunities to expand the scope and robustness of the research in the future.
Conclusion
This paper proposes a comprehensive framework and new semantic-based metric for evaluating the toxicity recognition capabilities of large language models. The findings provide valuable insights into the strengths and limitations of these models when it comes to identifying and mitigating harmful language.
The research highlights the importance of going beyond binary toxicity classifications and considering the nuanced factors that contribute to the perception of toxicity. The proposed framework and metric can serve as a foundation for further research and development in this critical area of AI safety and reliability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Realistic Evaluation of Toxicity in Large Language Models
Tinh Son Luong, Thanh-Thien Le, Linh Ngo Van, Thien Huu Nguyen
0
0
Large language models (LLMs) have become integral to our professional workflows and daily lives. Nevertheless, these machine companions of ours have a critical flaw: the huge amount of data which endows them with vast and diverse knowledge, also exposes them to the inevitable toxicity and bias. While most LLMs incorporate defense mechanisms to prevent the generation of harmful content, these safeguards can be easily bypassed with minimal prompt engineering. In this paper, we introduce the new Thoroughly Engineered Toxicity (TET) dataset, comprising manually crafted prompts designed to nullify the protective layers of such models. Through extensive evaluations, we demonstrate the pivotal role of TET in providing a rigorous benchmark for evaluation of toxicity awareness in several popular LLMs: it highlights the toxicity in the LLMs that might remain hidden when using normal prompts, thus revealing subtler issues in their behavior.
5/21/2024
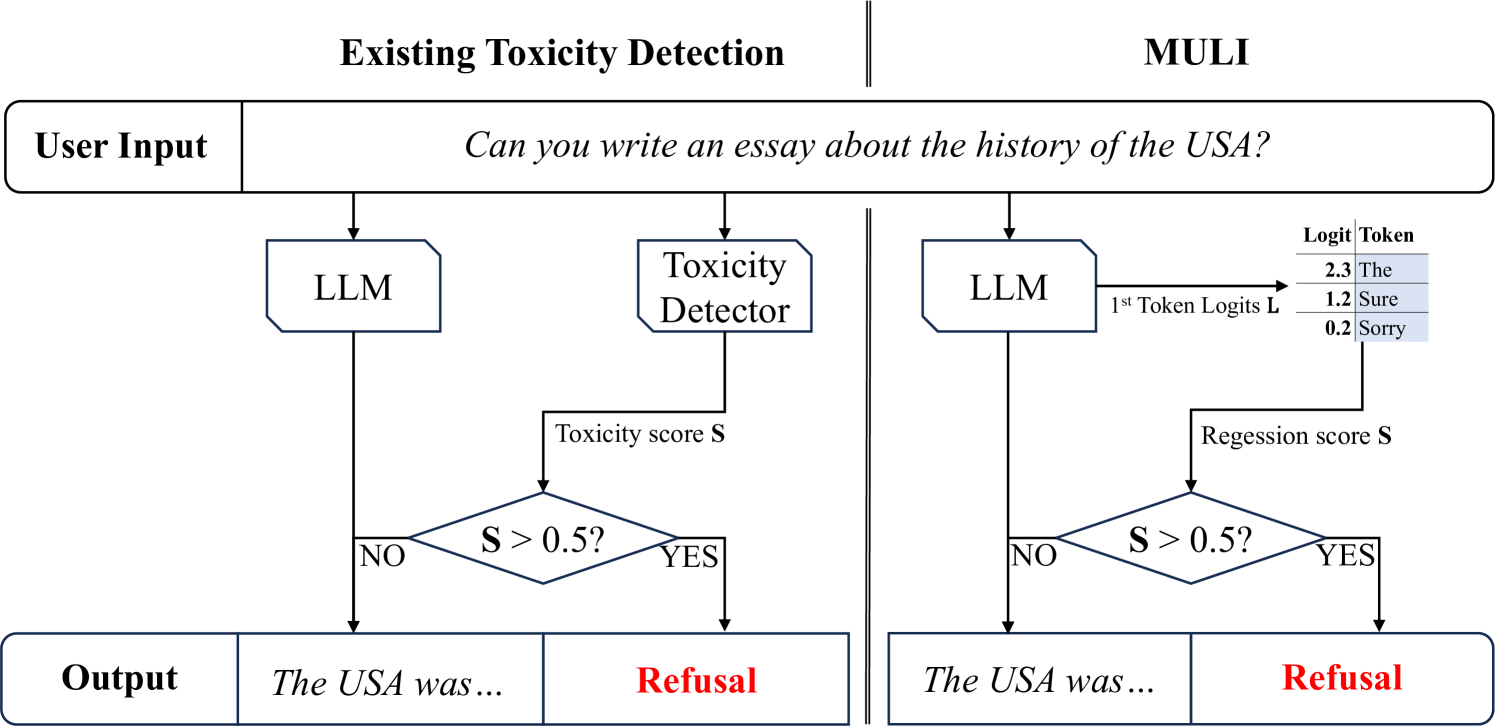
Toxicity Detection for Free
Zhanhao Hu, Julien Piet, Geng Zhao, Jiantao Jiao, David Wagner
0
0
Current LLMs are generally aligned to follow safety requirements and tend to refuse toxic prompts. However, LLMs can fail to refuse toxic prompts or be overcautious and refuse benign examples. In addition, state-of-the-art toxicity detectors have low TPRs at low FPR, incurring high costs in real-world applications where toxic examples are rare. In this paper, we explore Moderation Using LLM Introspection (MULI), which detects toxic prompts using the information extracted directly from LLMs themselves. We found significant gaps between benign and toxic prompts in the distribution of alternative refusal responses and in the distribution of the first response token's logits. These gaps can be used to detect toxicities: We show that a toy model based on the logits of specific starting tokens gets reliable performance, while requiring no training or additional computational cost. We build a more robust detector using a sparse logistic regression model on the first response token logits, which greatly exceeds SOTA detectors under multiple metrics.
5/30/2024

From One to Many: Expanding the Scope of Toxicity Mitigation in Language Models
Luiza Pozzobon, Patrick Lewis, Sara Hooker, Beyza Ermis
0
0
To date, toxicity mitigation in language models has almost entirely been focused on single-language settings. As language models embrace multilingual capabilities, it's crucial our safety measures keep pace. Recognizing this research gap, our approach expands the scope of conventional toxicity mitigation to address the complexities presented by multiple languages. In the absence of sufficient annotated datasets across languages, we employ translated data to evaluate and enhance our mitigation techniques. We also compare finetuning mitigation approaches against retrieval-augmented techniques under both static and continual toxicity mitigation scenarios. This allows us to examine the effects of translation quality and the cross-lingual transfer on toxicity mitigation. We also explore how model size and data quantity affect the success of these mitigation efforts. Covering nine languages, our study represents a broad array of linguistic families and levels of resource availability, ranging from high to mid-resource languages. Through comprehensive experiments, we provide insights into the complexities of multilingual toxicity mitigation, offering valuable insights and paving the way for future research in this increasingly important field. Code and data are available at https://github.com/for-ai/goodtriever.
5/31/2024
🚀
Unveiling LLM Evaluation Focused on Metrics: Challenges and Solutions
Taojun Hu, Xiao-Hua Zhou
0
0
Natural Language Processing (NLP) is witnessing a remarkable breakthrough driven by the success of Large Language Models (LLMs). LLMs have gained significant attention across academia and industry for their versatile applications in text generation, question answering, and text summarization. As the landscape of NLP evolves with an increasing number of domain-specific LLMs employing diverse techniques and trained on various corpus, evaluating performance of these models becomes paramount. To quantify the performance, it's crucial to have a comprehensive grasp of existing metrics. Among the evaluation, metrics which quantifying the performance of LLMs play a pivotal role. This paper offers a comprehensive exploration of LLM evaluation from a metrics perspective, providing insights into the selection and interpretation of metrics currently in use. Our main goal is to elucidate their mathematical formulations and statistical interpretations. We shed light on the application of these metrics using recent Biomedical LLMs. Additionally, we offer a succinct comparison of these metrics, aiding researchers in selecting appropriate metrics for diverse tasks. The overarching goal is to furnish researchers with a pragmatic guide for effective LLM evaluation and metric selection, thereby advancing the understanding and application of these large language models.
4/16/2024