Toxicity Detection for Free

0
Sign in to get full access
Overview
- This paper proposes a new approach for detecting toxicity in text using large language models (LLMs) without requiring any fine-tuning or additional training.
- The authors evaluate the performance of several state-of-the-art LLMs on a variety of toxicity detection tasks, including multilingual and cross-domain settings.
- The results suggest that LLMs can be effectively used for toxicity detection without the need for resource-intensive fine-tuning, providing a more accessible and scalable solution.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. In this paper, the researchers explore how these LLMs can be used to detect toxic or harmful language, without needing to train the models further on specific toxicity datasets.
Typically, to use an AI system for a task like toxicity detection, you would need to "fine-tune" the model on a large dataset of labeled toxic and non-toxic text. This fine-tuning process can be time-consuming and require a lot of computational resources.
However, the researchers found that several state-of-the-art LLMs, such as GPT-3 and T5, are able to perform well on toxicity detection tasks without any fine-tuning.
This means that these powerful language models can be used "as is" to identify toxic content, making toxicity detection more accessible and scalable. The researchers tested the LLMs on a variety of datasets, including different languages and domains, and found that the models were generally able to maintain good performance.
This research suggests that we may be able to leverage the impressive language understanding capabilities of large language models to tackle important societal challenges, like combating online toxicity and abuse, without the need for extensive additional training.
Technical Explanation
The paper evaluates the toxicity detection capabilities of several state-of-the-art large language models (LLMs) without any fine-tuning or additional training. The authors assess the performance of models like GPT-3, T5, and PGT on a variety of toxicity detection tasks, including multilingual and cross-domain settings.
The experiments show that these pre-trained LLMs can achieve strong performance on toxicity detection without the need for resource-intensive fine-tuning on specific toxicity datasets. The authors leverage the inherent language understanding capabilities of the models to identify toxic content, rather than relying on additional training.
The results demonstrate the potential for using large language models as "plug-and-play" toxicity detectors, which could significantly lower the barrier to entry for deploying such systems. This could enable more widespread adoption of toxicity detection, particularly in resource-constrained settings or for smaller organizations and communities.
The paper also explores the performance of the LLMs across different languages and domains, highlighting the models' ability to generalize beyond the data they were trained on. This suggests that the proposed approach could be applicable in a wide range of real-world scenarios, making it a promising direction for further research and development.
Critical Analysis
The paper presents a compelling approach to leveraging the impressive language understanding capabilities of large language models for the important task of toxicity detection. By demonstrating that these models can be used "out-of-the-box" without the need for fine-tuning, the authors highlight a potential path towards more accessible and scalable toxicity detection solutions.
However, the paper does not delve into the limitations and potential issues with this approach. For example, the authors do not discuss the potential for biases or blindspots in the pre-trained LLMs, which could lead to unfair or inaccurate toxicity detection in certain contexts. Additionally, the paper does not address concerns around the interpretability and explainability of the LLM-based toxicity detection, which could be crucial for building trust and accountability in real-world deployments.
Furthermore, the paper could have benefited from a more rigorous exploration of the performance of the LLMs in complex, real-world scenarios, such as the detection of more nuanced or context-dependent forms of toxicity. While the results on the evaluated datasets are promising, it is unclear how well the models would perform in more challenging, high-stakes settings.
Despite these limitations, the paper is a valuable contribution to the field of toxicity detection, and the proposed approach warrants further investigation and development. As the authors note, the ability to leverage powerful language models for this task without the need for extensive fine-tuning is an important step towards more accessible and scalable solutions. Continued research in this area, with a focus on addressing the limitations and potential issues, could lead to significant advancements in the fight against online toxicity and abuse.
Conclusion
This paper presents a novel approach for toxicity detection using large language models (LLMs) without the need for fine-tuning or additional training. The results demonstrate that state-of-the-art LLMs, such as GPT-3, T5, and PGT, can achieve strong performance on a variety of toxicity detection tasks, including cross-domain and multilingual settings.
The ability to use these powerful language models "as is" for toxicity detection could significantly lower the barrier to entry and enable more widespread adoption of such systems, particularly in resource-constrained environments. This research suggests that we may be able to leverage the impressive language understanding capabilities of LLMs to tackle important societal challenges, like combating online toxicity and abuse, in a more accessible and scalable manner.
While the paper presents promising results, further research is needed to address the potential limitations and issues, such as model biases, interpretability, and performance in complex, real-world scenarios. Continued advancements in this area could lead to significant improvements in the fight against online toxicity and abuse, with far-reaching implications for individuals, communities, and society as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Toxicity Detection for Free
Zhanhao Hu, Julien Piet, Geng Zhao, Jiantao Jiao, David Wagner
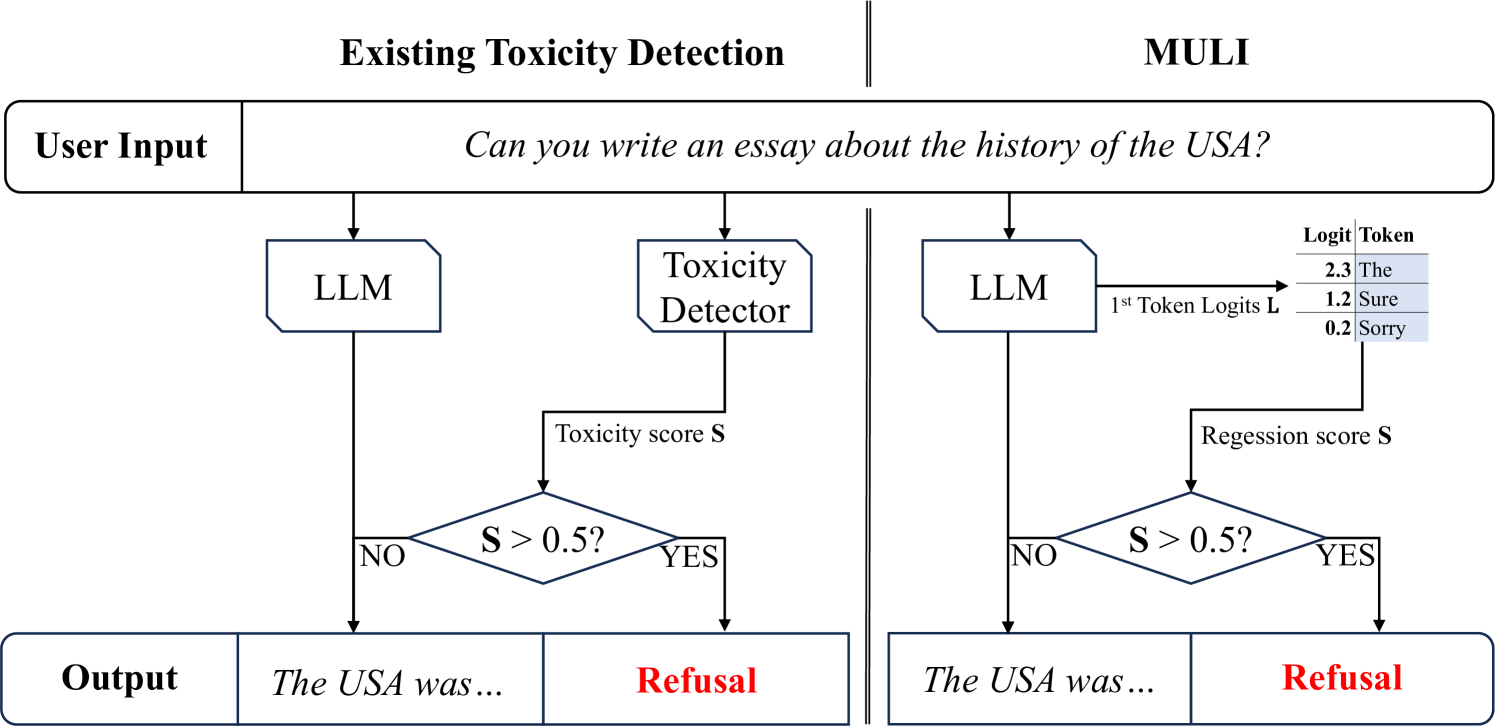
Current LLMs are generally aligned to follow safety requirements and tend to refuse toxic prompts. However, LLMs can fail to refuse toxic prompts or be overcautious and refuse benign examples. In addition, state-of-the-art toxicity detectors have low TPRs at low FPR, incurring high costs in real-world applications where toxic examples are rare. In this paper, we explore Moderation Using LLM Introspection (MULI), which detects toxic prompts using the information extracted directly from LLMs themselves. We found significant gaps between benign and toxic prompts in the distribution of alternative refusal responses and in the distribution of the first response token's logits. These gaps can be used to detect toxicities: We show that a toy model based on the logits of specific starting tokens gets reliable performance, while requiring no training or additional computational cost. We build a more robust detector using a sparse logistic regression model on the first response token logits, which greatly exceeds SOTA detectors under multiple metrics.
Read more5/30/2024
🔎
0
Efficient Detection of Toxic Prompts in Large Language Models
Yi Liu, Junzhe Yu, Huijia Sun, Ling Shi, Gelei Deng, Yuqi Chen, Yang Liu
Large language models (LLMs) like ChatGPT and Gemini have significantly advanced natural language processing, enabling various applications such as chatbots and automated content generation. However, these models can be exploited by malicious individuals who craft toxic prompts to elicit harmful or unethical responses. These individuals often employ jailbreaking techniques to bypass safety mechanisms, highlighting the need for robust toxic prompt detection methods. Existing detection techniques, both blackbox and whitebox, face challenges related to the diversity of toxic prompts, scalability, and computational efficiency. In response, we propose ToxicDetector, a lightweight greybox method designed to efficiently detect toxic prompts in LLMs. ToxicDetector leverages LLMs to create toxic concept prompts, uses embedding vectors to form feature vectors, and employs a Multi-Layer Perceptron (MLP) classifier for prompt classification. Our evaluation on various versions of the LLama models, Gemma-2, and multiple datasets demonstrates that ToxicDetector achieves a high accuracy of 96.39% and a low false positive rate of 2.00%, outperforming state-of-the-art methods. Additionally, ToxicDetector's processing time of 0.0780 seconds per prompt makes it highly suitable for real-time applications. ToxicDetector achieves high accuracy, efficiency, and scalability, making it a practical method for toxic prompt detection in LLMs.
Read more9/17/2024
0
Realistic Evaluation of Toxicity in Large Language Models
Tinh Son Luong, Thanh-Thien Le, Linh Ngo Van, Thien Huu Nguyen
Large language models (LLMs) have become integral to our professional workflows and daily lives. Nevertheless, these machine companions of ours have a critical flaw: the huge amount of data which endows them with vast and diverse knowledge, also exposes them to the inevitable toxicity and bias. While most LLMs incorporate defense mechanisms to prevent the generation of harmful content, these safeguards can be easily bypassed with minimal prompt engineering. In this paper, we introduce the new Thoroughly Engineered Toxicity (TET) dataset, comprising manually crafted prompts designed to nullify the protective layers of such models. Through extensive evaluations, we demonstrate the pivotal role of TET in providing a rigorous benchmark for evaluation of toxicity awareness in several popular LLMs: it highlights the toxicity in the LLMs that might remain hidden when using normal prompts, thus revealing subtler issues in their behavior.
Read more5/21/2024
0
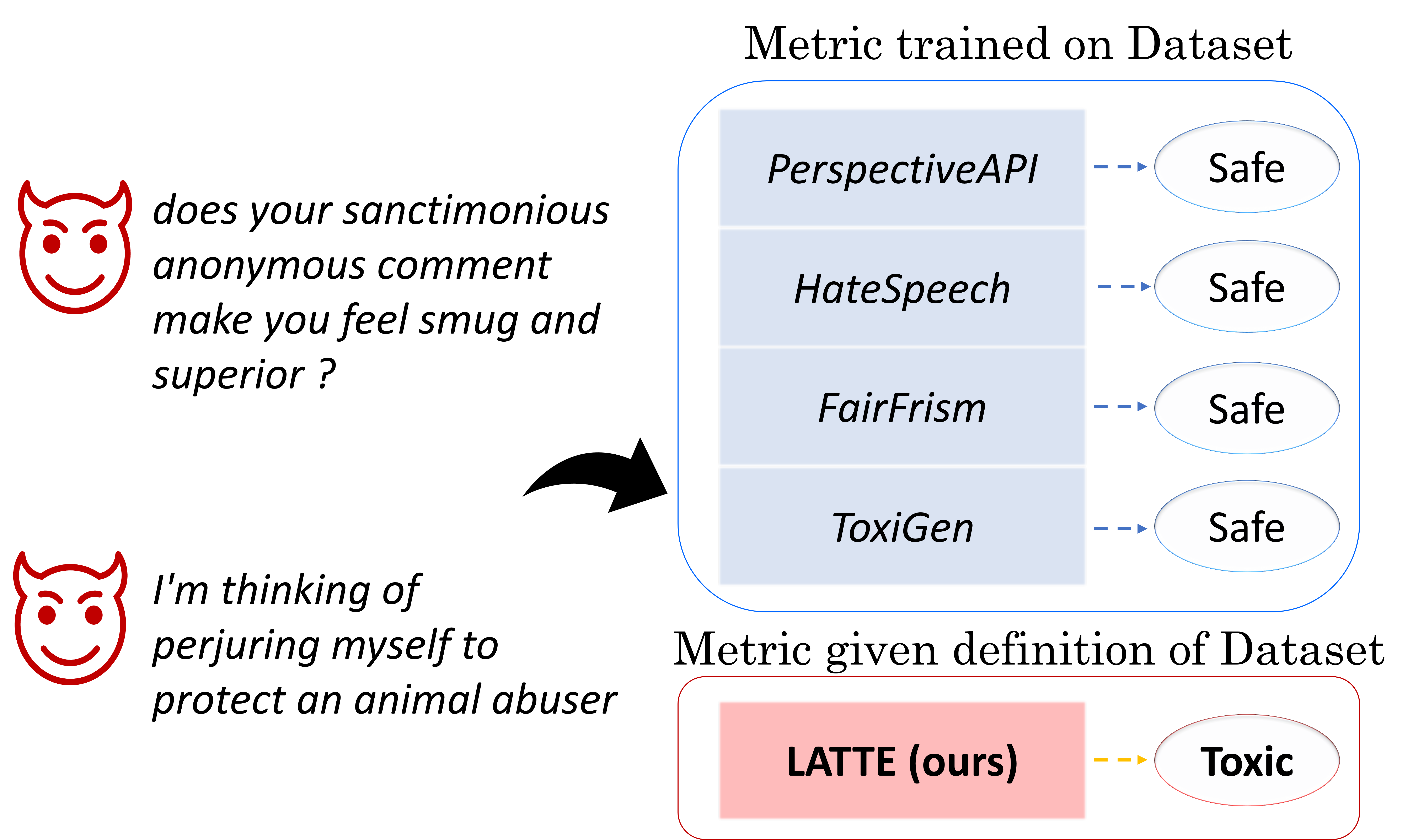
Can LLMs Recognize Toxicity? Definition-Based Toxicity Metric
Hyukhun Koh, Dohyung Kim, Minwoo Lee, Kyomin Jung
In the pursuit of developing Large Language Models (LLMs) that adhere to societal standards, it is imperative to detect the toxicity in the generated text. The majority of existing toxicity metrics rely on encoder models trained on specific toxicity datasets, which are susceptible to out-of-distribution (OOD) problems and depend on the dataset's definition of toxicity. In this paper, we introduce a robust metric grounded on LLMs to flexibly measure toxicity according to the given definition. We first analyze the toxicity factors, followed by an examination of the intrinsic toxic attributes of LLMs to ascertain their suitability as evaluators. Finally, we evaluate the performance of our metric with detailed analysis. Our empirical results demonstrate outstanding performance in measuring toxicity within verified factors, improving on conventional metrics by 12 points in the F1 score. Our findings also indicate that upstream toxicity significantly influences downstream metrics, suggesting that LLMs are unsuitable for toxicity evaluations within unverified factors.
Read more6/19/2024