Cascaded Multi-path Shortcut Diffusion Model for Medical Image Translation
2405.12223
0
0
📈
Abstract
Image-to-image translation is a vital component in medical imaging processing, with many uses in a wide range of imaging modalities and clinical scenarios. Previous methods include Generative Adversarial Networks (GANs) and Diffusion Models (DMs), which offer realism but suffer from instability and lack uncertainty estimation. Even though both GAN and DM methods have individually exhibited their capability in medical image translation tasks, the potential of combining a GAN and DM to further improve translation performance and to enable uncertainty estimation remains largely unexplored. In this work, we address these challenges by proposing a Cascade Multi-path Shortcut Diffusion Model (CMDM) for high-quality medical image translation and uncertainty estimation. To reduce the required number of iterations and ensure robust performance, our method first obtains a conditional GAN-generated prior image that will be used for the efficient reverse translation with a DM in the subsequent step. Additionally, a multi-path shortcut diffusion strategy is employed to refine translation results and estimate uncertainty. A cascaded pipeline further enhances translation quality, incorporating residual averaging between cascades. We collected three different medical image datasets with two sub-tasks for each dataset to test the generalizability of our approach. Our experimental results found that CMDM can produce high-quality translations comparable to state-of-the-art methods while providing reasonable uncertainty estimations that correlate well with the translation error.
Create account to get full access
Overview
- This paper tackles the challenge of medical image translation, which is crucial for various medical imaging applications.
- Previous methods like Generative Adversarial Networks (GANs) and Diffusion Models (DMs) have shown promise, but suffer from instability and lack of uncertainty estimation.
- The authors propose a novel approach called Cascade Multi-path Shortcut Diffusion Model (CMDM) to address these issues and improve medical image translation performance.
Plain English Explanation
The paper focuses on improving the process of converting one type of medical image into another, a task known as "medical image translation." This is important for various medical applications, like helping doctors better diagnose and treat patients.
Previous methods, such as GANs and DMs, have been able to generate realistic-looking medical images, but they have some problems. They can be unstable, meaning the results can be unpredictable, and they don't provide a way to measure how confident the model is in its translations.
To address these issues, the researchers developed a new method called CMDM. This approach first uses a type of AI called a GAN to create an initial, rough translation. It then uses a DM to refine the translation and provide an estimate of how certain the model is about the final result.
By combining these two techniques, the researchers were able to create high-quality medical image translations while also giving users a sense of how reliable the translations are. This can be very useful for medical professionals who need to make important decisions based on these translated images.
Technical Explanation
The authors propose a Cascade Multi-path Shortcut Diffusion Model (CMDM) to address the limitations of previous medical image translation methods. CMDM uses a two-step approach:
- It first generates a conditional GAN-based prior image, which serves as a starting point for the efficient reverse translation process with a Diffusion Model in the subsequent step.
- The multi-path shortcut diffusion strategy is then employed to refine the translation results and estimate the uncertainty associated with the translations.
Additionally, the authors implement a cascaded pipeline to further enhance the translation quality by incorporating residual averaging between cascades.
The researchers evaluated CMDM on three different medical imaging datasets, each with two sub-tasks, to test the generalizability of their approach. Their experiments found that CMDM can produce high-quality translations comparable to state-of-the-art methods while also providing reasonable uncertainty estimations that correlate well with the translation error.
Critical Analysis
The paper presents a novel and promising approach to medical image translation, addressing the key limitations of previous methods. However, there are a few areas that could be explored further:
- The authors mention that the cascaded pipeline and residual averaging help improve translation quality, but they don't provide a detailed analysis of how much these components contribute to the overall performance.
- While the uncertainty estimation provided by CMDM is a valuable feature, the paper doesn't explore how this could be used in practical medical applications, such as assisting doctors in their decision-making process.
- The authors tested CMDM on three medical imaging datasets, but it would be interesting to see how the model performs on a wider range of medical imaging modalities and clinical scenarios.
Overall, the CMDM approach represents a significant advancement in the field of medical image translation, and the authors have done a commendable job in developing and evaluating their solution. Further research into the practical implications and broader applicability of this method could yield important insights for the medical community.
Conclusion
The paper presents a novel Cascade Multi-path Shortcut Diffusion Model (CMDM) that addresses the limitations of previous medical image translation methods. By combining the strengths of Generative Adversarial Networks and Diffusion Models, CMDM can generate high-quality translations while also providing reliable uncertainty estimates.
The authors' extensive evaluation on multiple medical imaging datasets demonstrates the generalizability and effectiveness of their approach. This work represents an important step forward in the field of medical image translation, with the potential to enhance diagnostic accuracy and decision-making in various clinical scenarios.
As medical imaging technologies continue to advance, tools like CMDM will become increasingly valuable in helping healthcare professionals extract meaningful insights from complex visual data. Further research in this direction could lead to even more powerful and versatile medical image translation solutions that can truly transform the way we approach medical diagnosis and treatment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
New!FDDM: Unsupervised Medical Image Translation with a Frequency-Decoupled Diffusion Model
Yunxiang Li, Hua-Chieh Shao, Xiaoxue Qian, You Zhang
0
0
Diffusion models have demonstrated significant potential in producing high-quality images in medical image translation to aid disease diagnosis, localization, and treatment. Nevertheless, current diffusion models have limited success in achieving faithful image translations that can accurately preserve the anatomical structures of medical images, especially for unpaired datasets. The preservation of structural and anatomical details is essential to reliable medical diagnosis and treatment planning, as structural mismatches can lead to disease misidentification and treatment errors. In this study, we introduce the Frequency Decoupled Diffusion Model (FDDM) for MR-to-CT conversion. FDDM first obtains the anatomical information of the CT image from the MR image through an initial conversion module. This anatomical information then guides a subsequent diffusion model to generate high-quality CT images. Our diffusion model uses a dual-path reverse diffusion process for low-frequency and high-frequency information, achieving a better balance between image quality and anatomical accuracy. We extensively evaluated FDDM using public datasets for brain MR-to-CT and pelvis MR-to-CT translations, demonstrating its superior performance to other GAN-based, VAE-based, and diffusion-based models. The evaluation metrics included Frechet Inception Distance (FID), Peak Signal-to-Noise Ratio (PSNR), and Structural Similarity Index Measure (SSIM). FDDM achieved the best scores on all metrics for both datasets, particularly excelling in FID, with scores of 25.9 for brain data and 29.2 for pelvis data, significantly outperforming other methods. These results demonstrate that FDDM can generate high-quality target domain images while maintaining the accuracy of translated anatomical structures.
6/28/2024

Similarity-aware Syncretic Latent Diffusion Model for Medical Image Translation with Representation Learning
Tingyi Lin, Pengju Lyu, Jie Zhang, Yuqing Wang, Cheng Wang, Jianjun Zhu
0
0
Non-contrast CT (NCCT) imaging may reduce image contrast and anatomical visibility, potentially increasing diagnostic uncertainty. In contrast, contrast-enhanced CT (CECT) facilitates the observation of regions of interest (ROI). Leading generative models, especially the conditional diffusion model, demonstrate remarkable capabilities in medical image modality transformation. Typical conditional diffusion models commonly generate images with guidance of segmentation labels for medical modal transformation. Limited access to authentic guidance and its low cardinality can pose challenges to the practical clinical application of conditional diffusion models. To achieve an equilibrium of generative quality and clinical practices, we propose a novel Syncretic generative model based on the latent diffusion model for medical image translation (S$^2$LDM), which can realize high-fidelity reconstruction without demand of additional condition during inference. S$^2$LDM enhances the similarity in distinct modal images via syncretic encoding and diffusing, promoting amalgamated information in the latent space and generating medical images with more details in contrast-enhanced regions. However, syncretic latent spaces in the frequency domain tend to favor lower frequencies, commonly locate in identical anatomic structures. Thus, S$^2$LDM applies adaptive similarity loss and dynamic similarity to guide the generation and supplements the shortfall in high-frequency details throughout the training process. Quantitative experiments confirm the effectiveness of our approach in medical image translation. Our code will release lately.
6/21/2024
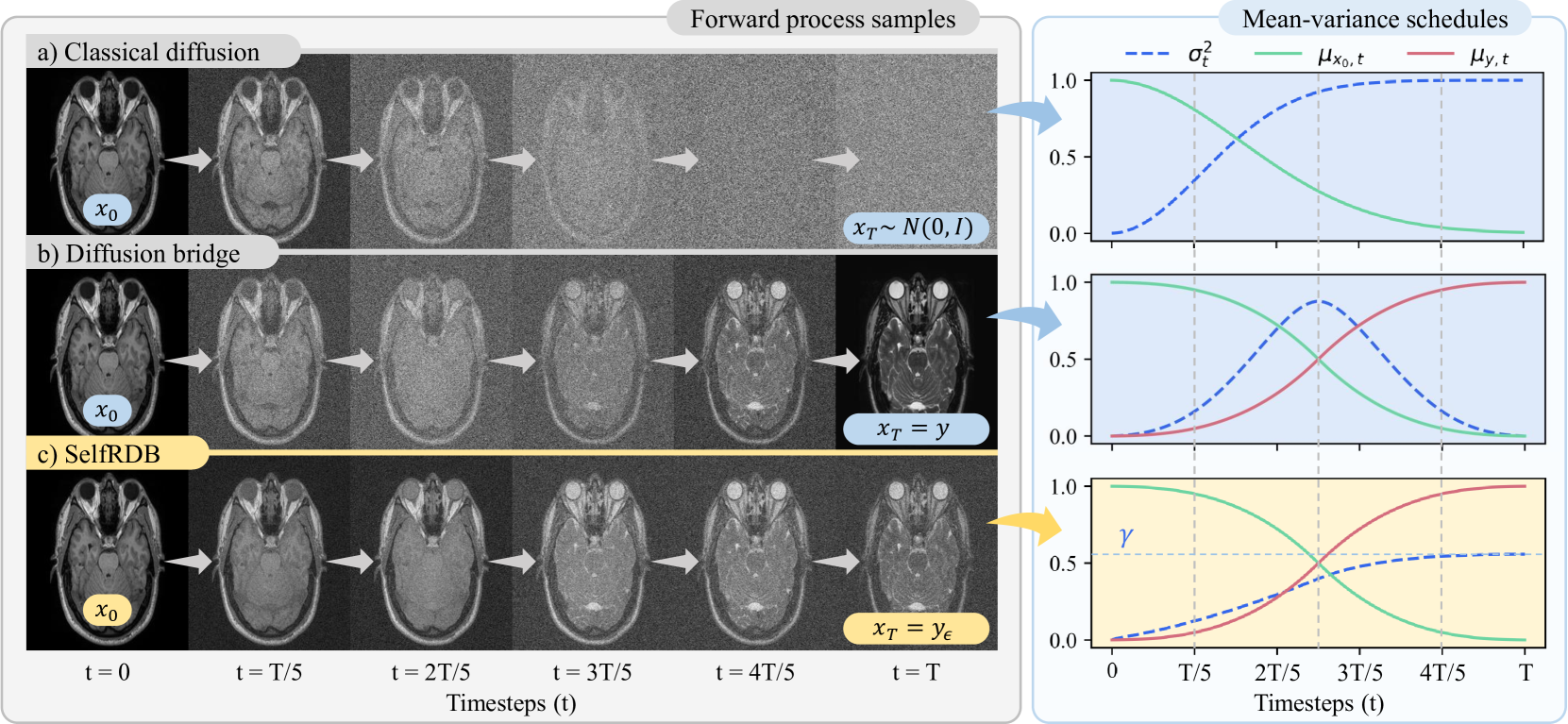
Self-Consistent Recursive Diffusion Bridge for Medical Image Translation
Fuat Arslan, Bilal Kabas, Onat Dalmaz, Muzaffer Ozbey, Tolga c{C}ukur
0
0
Denoising diffusion models (DDM) have gained recent traction in medical image translation given improved training stability over adversarial models. DDMs learn a multi-step denoising transformation to progressively map random Gaussian-noise images onto target-modality images, while receiving stationary guidance from source-modality images. As this denoising transformation diverges significantly from the task-relevant source-to-target transformation, DDMs can suffer from weak source-modality guidance. Here, we propose a novel self-consistent recursive diffusion bridge (SelfRDB) for improved performance in medical image translation. Unlike DDMs, SelfRDB employs a novel forward process with start- and end-points defined based on target and source images, respectively. Intermediate image samples across the process are expressed via a normal distribution with mean taken as a convex combination of start-end points, and variance from additive noise. Unlike regular diffusion bridges that prescribe zero variance at start-end points and high variance at mid-point of the process, we propose a novel noise scheduling with monotonically increasing variance towards the end-point in order to boost generalization performance and facilitate information transfer between the two modalities. To further enhance sampling accuracy in each reverse step, we propose a novel sampling procedure where the network recursively generates a transient-estimate of the target image until convergence onto a self-consistent solution. Comprehensive analyses in multi-contrast MRI and MRI-CT translation indicate that SelfRDB offers superior performance against competing methods.
5/14/2024

2.5D Multi-view Averaging Diffusion Model for 3D Medical Image Translation: Application to Low-count PET Reconstruction with CT-less Attenuation Correction
Tianqi Chen, Jun Hou, Yinchi Zhou, Huidong Xie, Xiongchao Chen, Qiong Liu, Xueqi Guo, Menghua Xia, James S. Duncan, Chi Liu, Bo Zhou
0
0
Positron Emission Tomography (PET) is an important clinical imaging tool but inevitably introduces radiation hazards to patients and healthcare providers. Reducing the tracer injection dose and eliminating the CT acquisition for attenuation correction can reduce the overall radiation dose, but often results in PET with high noise and bias. Thus, it is desirable to develop 3D methods to translate the non-attenuation-corrected low-dose PET (NAC-LDPET) into attenuation-corrected standard-dose PET (AC-SDPET). Recently, diffusion models have emerged as a new state-of-the-art deep learning method for image-to-image translation, better than traditional CNN-based methods. However, due to the high computation cost and memory burden, it is largely limited to 2D applications. To address these challenges, we developed a novel 2.5D Multi-view Averaging Diffusion Model (MADM) for 3D image-to-image translation with application on NAC-LDPET to AC-SDPET translation. Specifically, MADM employs separate diffusion models for axial, coronal, and sagittal views, whose outputs are averaged in each sampling step to ensure the 3D generation quality from multiple views. To accelerate the 3D sampling process, we also proposed a strategy to use the CNN-based 3D generation as a prior for the diffusion model. Our experimental results on human patient studies suggested that MADM can generate high-quality 3D translation images, outperforming previous CNN-based and Diffusion-based baseline methods.
6/18/2024