CascadedGaze: Efficiency in Global Context Extraction for Image Restoration

0

Sign in to get full access
Overview
- This paper proposes a novel image restoration technique called "CascadedGaze" that leverages efficient global context extraction for improved performance.
- The method aims to address the challenge of effectively capturing global information in image restoration tasks, which is crucial for generating high-quality results.
- CascadedGaze introduces a cascaded architecture that progressively refines the global context representation, leading to efficient and effective image restoration.
Plain English Explanation
The paper describes a new approach called "CascadedGaze" for improving image restoration, which is the process of enhancing or reconstructing degraded or low-quality images. The key idea is to efficiently capture the overall context of the image, which can provide valuable information for generating high-quality restored images.
Traditional image restoration methods may struggle to effectively incorporate global context, as they often focus on local details. CascadedGaze addresses this by using a cascaded architecture, where the global context is refined and improved in multiple stages. This allows the system to gradually build up a more comprehensive understanding of the entire image, which can then be used to produce better restored outputs.
The authors argue that this approach of progressively refining the global context representation leads to more efficient and effective image restoration compared to other methods. By efficiently capturing the broader context of the image, CascadedGaze can generate higher-quality results than techniques that rely more heavily on local information.
Technical Explanation
The paper introduces the CascadedGaze framework, which utilizes a cascaded architecture to efficiently extract and refine the global context of an image for improved image restoration performance.
The core innovation of CascadedGaze is its cascaded design, where the global context representation is progressively refined through multiple stages. This contrasts with traditional approaches that often struggle to effectively capture global information, as they tend to focus more on local details.
The CascadedGaze architecture consists of several key components:
- Global Context Extractor: This module is responsible for extracting the initial global context representation from the input image.
- Cascaded Refinement Modules: These modules sequentially refine the global context representation, gradually improving its quality and effectiveness.
- Restoration Network: The final component takes the refined global context and combines it with local information to produce the restored output image.
The authors demonstrate the effectiveness of CascadedGaze through extensive experiments on various image restoration tasks, such as single-image super-resolution, saliency prediction, and blind video face restoration. The results show that CascadedGaze outperforms state-of-the-art methods, highlighting the benefits of its efficient global context extraction approach.
Critical Analysis
The paper presents a well-designed and comprehensive study on the CascadedGaze framework for image restoration. The authors have carefully addressed the limitations of existing methods in effectively capturing global context and have proposed a novel cascaded architecture to address this challenge.
One potential concern is the computational complexity of the cascaded refinement process, as it may add additional overhead compared to simpler global context extraction approaches. The authors should provide more details on the trade-off between the performance gains and the computational cost of their method.
Additionally, the paper could have discussed the limitations of the CascadedGaze approach, such as its performance on specific types of image restoration tasks or its sensitivity to certain types of image degradations. Exploring these aspects could help researchers and practitioners better understand the strengths and weaknesses of the proposed technique.
Conclusion
The CascadedGaze framework introduced in this paper represents a significant advancement in the field of image restoration. By effectively leveraging efficient global context extraction, the proposed method is able to outperform state-of-the-art techniques across various restoration tasks.
The cascaded architecture's ability to progressively refine the global context representation is a key innovation that allows CascadedGaze to capture comprehensive image information and generate high-quality restored outputs. This approach has the potential to drive further advancements in image restoration and related fields, where efficiently utilizing global context can lead to substantial performance improvements.
Overall, the CascadedGaze paper presents a well-designed and impactful contribution to the image restoration literature, and its findings are likely to inspire future research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CascadedGaze: Efficiency in Global Context Extraction for Image Restoration
Amirhosein Ghasemabadi, Muhammad Kamran Janjua, Mohammad Salameh, Chunhua Zhou, Fengyu Sun, Di Niu
Image restoration tasks traditionally rely on convolutional neural networks. However, given the local nature of the convolutional operator, they struggle to capture global information. The promise of attention mechanisms in Transformers is to circumvent this problem, but it comes at the cost of intensive computational overhead. Many recent studies in image restoration have focused on solving the challenge of balancing performance and computational cost via Transformer variants. In this paper, we present CascadedGaze Network (CGNet), an encoder-decoder architecture that employs Global Context Extractor (GCE), a novel and efficient way to capture global information for image restoration. The GCE module leverages small kernels across convolutional layers to learn global dependencies, without requiring self-attention. Extensive experimental results show that our computationally efficient approach performs competitively to a range of state-of-the-art methods on synthetic image denoising and single image deblurring tasks, and pushes the performance boundary further on the real image denoising task.
Read more5/8/2024
0
A Scalable and Effective Alternative to Graph Transformers
Kaan Sancak, Zhigang Hua, Jin Fang, Yan Xie, Andrey Malevich, Bo Long, Muhammed Fatih Balin, Umit V. c{C}atalyurek
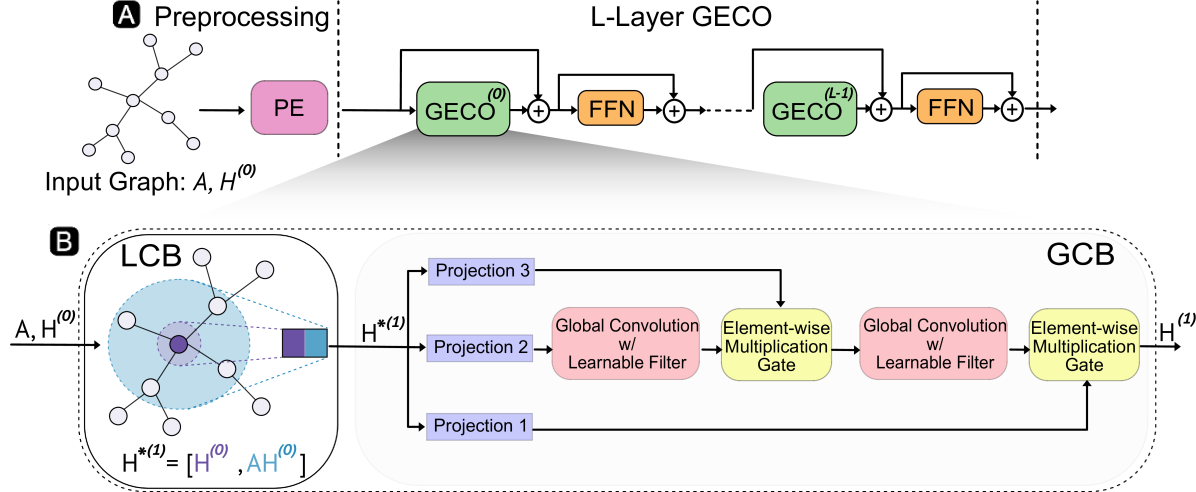
Graph Neural Networks (GNNs) have shown impressive performance in graph representation learning, but they face challenges in capturing long-range dependencies due to their limited expressive power. To address this, Graph Transformers (GTs) were introduced, utilizing self-attention mechanism to effectively model pairwise node relationships. Despite their advantages, GTs suffer from quadratic complexity w.r.t. the number of nodes in the graph, hindering their applicability to large graphs. In this work, we present Graph-Enhanced Contextual Operator (GECO), a scalable and effective alternative to GTs that leverages neighborhood propagation and global convolutions to effectively capture local and global dependencies in quasilinear time. Our study on synthetic datasets reveals that GECO reaches 169x speedup on a graph with 2M nodes w.r.t. optimized attention. Further evaluations on diverse range of benchmarks showcase that GECO scales to large graphs where traditional GTs often face memory and time limitations. Notably, GECO consistently achieves comparable or superior quality compared to baselines, improving the SOTA up to 4.5%, and offering a scalable and effective solution for large-scale graph learning.
Read more6/19/2024

0
Single Image Super-Resolution Based on Global-Local Information Synergy
Nianzu Qiao, Lamei Di, Changyin Sun
Although several image super-resolution solutions exist, they still face many challenges. CNN-based algorithms, despite the reduction in computational complexity, still need to improve their accuracy. While Transformer-based algorithms have higher accuracy, their ultra-high computational complexity makes them difficult to be accepted in practical applications. To overcome the existing challenges, a novel super-resolution reconstruction algorithm is proposed in this paper. The algorithm achieves a significant increase in accuracy through a unique design while maintaining a low complexity. The core of the algorithm lies in its cleverly designed Global-Local Information Extraction Module and Basic Block Module. By combining global and local information, the Global-Local Information Extraction Module aims to understand the image content more comprehensively so as to recover the global structure and local details in the image more accurately, which provides rich information support for the subsequent reconstruction process. Experimental results show that the comprehensive performance of the algorithm proposed in this paper is optimal, providing an efficient and practical new solution in the field of super-resolution reconstruction.
Read more5/3/2024
🌐
0
Contextual Encoder-Decoder Network for Visual Saliency Prediction
Alexander Kroner, Mario Senden, Kurt Driessens, Rainer Goebel
Predicting salient regions in natural images requires the detection of objects that are present in a scene. To develop robust representations for this challenging task, high-level visual features at multiple spatial scales must be extracted and augmented with contextual information. However, existing models aimed at explaining human fixation maps do not incorporate such a mechanism explicitly. Here we propose an approach based on a convolutional neural network pre-trained on a large-scale image classification task. The architecture forms an encoder-decoder structure and includes a module with multiple convolutional layers at different dilation rates to capture multi-scale features in parallel. Moreover, we combine the resulting representations with global scene information for accurately predicting visual saliency. Our model achieves competitive and consistent results across multiple evaluation metrics on two public saliency benchmarks and we demonstrate the effectiveness of the suggested approach on five datasets and selected examples. Compared to state of the art approaches, the network is based on a lightweight image classification backbone and hence presents a suitable choice for applications with limited computational resources, such as (virtual) robotic systems, to estimate human fixations across complex natural scenes.
Read more4/8/2024