A Case Study of Large Language Models (ChatGPT and CodeBERT) for Security-Oriented Code Analysis
2307.12488
0
0
💬
Abstract
LLMs can be used on code analysis tasks like code review, vulnerabilities analysis and etc. However, the strengths and limitations of adopting these LLMs to the code analysis are still unclear. In this paper, we delve into LLMs' capabilities in security-oriented program analysis, considering perspectives from both attackers and security analysts. We focus on two representative LLMs, ChatGPT and CodeBert, and evaluate their performance in solving typical analytic tasks with varying levels of difficulty. Our study demonstrates the LLM's efficiency in learning high-level semantics from code, positioning ChatGPT as a potential asset in security-oriented contexts. However, it is essential to acknowledge certain limitations, such as the heavy reliance on well-defined variable and function names, making them unable to learn from anonymized code. For example, the performance of these LLMs heavily relies on the well-defined variable and function names, therefore, will not be able to learn anonymized code. We believe that the concerns raised in this case study deserve in-depth investigation in the future.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Evaluates the capabilities and limitations of large language models (LLMs) like ChatGPT and CodeBERT in security-oriented program analysis tasks
- Focuses on how these models perform on tasks like code review, vulnerability analysis, and other security-related code analysis
- Examines the models' strengths in learning high-level code semantics as well as their weaknesses, such as reliance on well-defined variable and function names
Plain English Explanation
Large language models (LLMs) like ChatGPT and CodeBERT have shown promise in code analysis tasks, but their specific strengths and limitations in the security domain are not yet fully understood. This paper delves into how these LLMs perform on typical security-focused code analysis tasks, such as reviewing code for vulnerabilities or identifying security issues.
The researchers found that the LLMs are quite effective at understanding the high-level meaning and semantics of code, making them potentially useful tools for security analysts. For example, ChatGPT was able to efficiently identify and explain security-related problems in code.
However, the models also have significant limitations. They rely heavily on the quality of variable and function names in the code, and struggle to learn from code that has been anonymized or obfuscated. This means the models may not be able to effectively analyze code that has been intentionally obscured, as is common in malicious software.
Overall, the paper suggests that LLMs can be valuable assets in security-oriented code analysis, but also highlights important areas for further research and development to address the current limitations.
Technical Explanation
The researchers evaluated the performance of two representative LLMs, ChatGPT and CodeBERT, on a variety of security-focused code analysis tasks. These tasks ranged in difficulty and were designed to assess the models' capabilities from the perspectives of both attackers and security analysts.
The results showed that the LLMs were quite effective at learning high-level semantic information from the code, allowing them to efficiently identify and explain security-related issues. For example, ChatGPT was able to accurately detect common vulnerabilities like SQL injection and buffer overflow, and provide detailed explanations of the problems.
However, the models' performance was heavily dependent on the quality of the variable and function names in the code. When the code was anonymized or obfuscated, the LLMs struggled to learn the necessary information, limiting their effectiveness. This is a significant limitation, as code obfuscation is a common technique used by malicious actors to evade detection.
The researchers also found that the LLMs performed better on tasks that required high-level understanding of code semantics, rather than low-level, detailed analysis. This suggests that the models may be more useful for tasks like code review and vulnerability identification, rather than more complex security analysis.
Critical Analysis
The paper highlights important strengths and limitations of using LLMs for security-oriented code analysis, and raises several critical questions for further research.
One key limitation is the models' heavy reliance on well-defined variable and function names. This makes them vulnerable to techniques like code obfuscation, which are commonly used by malicious actors to evade detection. Addressing this limitation would be crucial for the effective deployment of LLMs in security-critical applications.
Additionally, the paper notes that the LLMs performed better on tasks requiring high-level understanding of code semantics, rather than low-level, detailed analysis. This suggests that the models may have limitations in more complex security analysis tasks, and raises questions about their suitability for certain security-critical applications.
The researchers also acknowledge the need for further investigation into the safety and generalization challenges of using LLMs in security-oriented contexts. As these models become more widely adopted, it will be crucial to carefully evaluate their robustness and reliability in the face of adversarial attacks or unexpected inputs.
Overall, the paper provides a valuable starting point for understanding the potential and limitations of LLMs in security-oriented code analysis. However, the concerns raised deserve in-depth investigation to ensure the responsible and effective deployment of these models in security-critical applications.
Conclusion
This study offers important insights into the capabilities and limitations of using large language models like ChatGPT and CodeBERT for security-oriented code analysis. While the LLMs demonstrate efficiency in learning high-level code semantics, their heavy reliance on well-defined variable and function names poses a significant limitation, particularly in the face of common obfuscation techniques used by malicious actors.
The findings suggest that these LLMs may be valuable assets in certain security-focused tasks, such as code review and vulnerability identification. However, their suitability for more complex security analysis remains an open question that requires further investigation. As the use of LLMs in security-critical applications continues to grow, it will be crucial to address the concerns raised in this study to ensure the responsible and effective deployment of these powerful models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Evaluation of LLM Chatbots for OSINT-based Cyber Threat Awareness
Samaneh Shafee, Alysson Bessani, Pedro M. Ferreira
0
0
Knowledge sharing about emerging threats is crucial in the rapidly advancing field of cybersecurity and forms the foundation of Cyber Threat Intelligence (CTI). In this context, Large Language Models are becoming increasingly significant in the field of cybersecurity, presenting a wide range of opportunities. This study surveys the performance of ChatGPT, GPT4all, Dolly, Stanford Alpaca, Alpaca-LoRA, Falcon, and Vicuna chatbots in binary classification and Named Entity Recognition (NER) tasks performed using Open Source INTelligence (OSINT). We utilize well-established data collected in previous research from Twitter to assess the competitiveness of these chatbots when compared to specialized models trained for those tasks. In binary classification experiments, Chatbot GPT-4 as a commercial model achieved an acceptable F1 score of 0.94, and the open-source GPT4all model achieved an F1 score of 0.90. However, concerning cybersecurity entity recognition, all evaluated chatbots have limitations and are less effective. This study demonstrates the capability of chatbots for OSINT binary classification and shows that they require further improvement in NER to effectively replace specially trained models. Our results shed light on the limitations of the LLM chatbots when compared to specialized models, and can help researchers improve chatbots technology with the objective to reduce the required effort to integrate machine learning in OSINT-based CTI tools.
4/22/2024
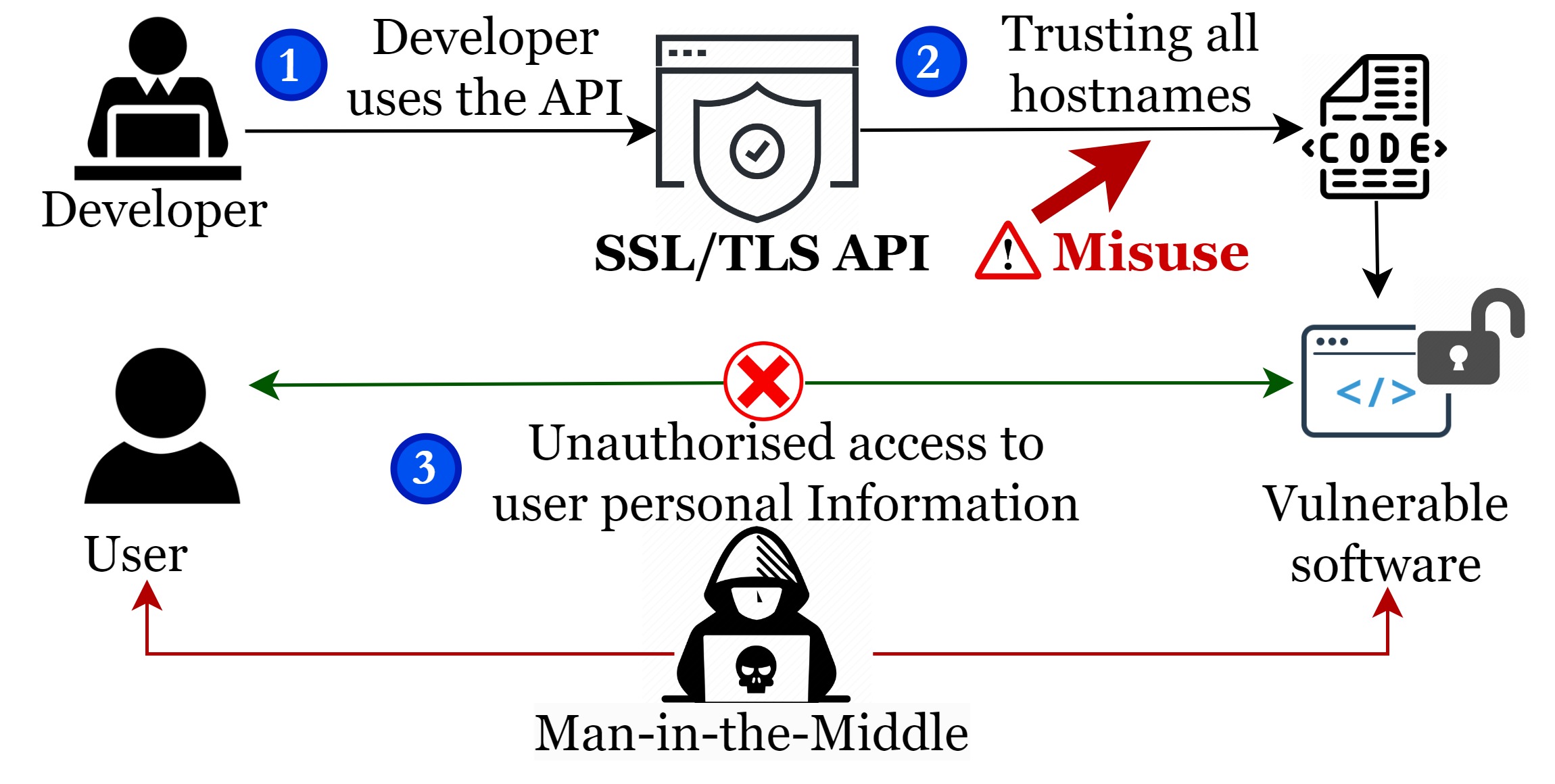
An Investigation into Misuse of Java Security APIs by Large Language Models
Zahra Mousavi, Chadni Islam, Kristen Moore, Alsharif Abuadbba, Muhammad Ali Babar
0
0
The increasing trend of using Large Language Models (LLMs) for code generation raises the question of their capability to generate trustworthy code. While many researchers are exploring the utility of code generation for uncovering software vulnerabilities, one crucial but often overlooked aspect is the security Application Programming Interfaces (APIs). APIs play an integral role in upholding software security, yet effectively integrating security APIs presents substantial challenges. This leads to inadvertent misuse by developers, thereby exposing software to vulnerabilities. To overcome these challenges, developers may seek assistance from LLMs. In this paper, we systematically assess ChatGPT's trustworthiness in code generation for security API use cases in Java. To conduct a thorough evaluation, we compile an extensive collection of 48 programming tasks for 5 widely used security APIs. We employ both automated and manual approaches to effectively detect security API misuse in the code generated by ChatGPT for these tasks. Our findings are concerning: around 70% of the code instances across 30 attempts per task contain security API misuse, with 20 distinct misuse types identified. Moreover, for roughly half of the tasks, this rate reaches 100%, indicating that there is a long way to go before developers can rely on ChatGPT to securely implement security API code.
4/8/2024
✨
Beyond Code Generation: An Observational Study of ChatGPT Usage in Software Engineering Practice
Ranim Khojah, Mazen Mohamad, Philipp Leitner, Francisco Gomes de Oliveira Neto
0
0
Large Language Models (LLMs) are frequently discussed in academia and the general public as support tools for virtually any use case that relies on the production of text, including software engineering. Currently there is much debate, but little empirical evidence, regarding the practical usefulness of LLM-based tools such as ChatGPT for engineers in industry. We conduct an observational study of 24 professional software engineers who have been using ChatGPT over a period of one week in their jobs, and qualitatively analyse their dialogues with the chatbot as well as their overall experience (as captured by an exit survey). We find that, rather than expecting ChatGPT to generate ready-to-use software artifacts (e.g., code), practitioners more often use ChatGPT to receive guidance on how to solve their tasks or learn about a topic in more abstract terms. We also propose a theoretical framework for how (i) purpose of the interaction, (ii) internal factors (e.g., the user's personality), and (iii) external factors (e.g., company policy) together shape the experience (in terms of perceived usefulness and trust). We envision that our framework can be used by future research to further the academic discussion on LLM usage by software engineering practitioners, and to serve as a reference point for the design of future empirical LLM research in this domain.
4/24/2024

Exploring Safety Generalization Challenges of Large Language Models via Code
Qibing Ren, Chang Gao, Jing Shao, Junchi Yan, Xin Tan, Yu Qiao, Wai Lam, Lizhuang Ma
0
0
The rapid advancement of Large Language Models (LLMs) has brought about remarkable generative capabilities but also raised concerns about their potential misuse. While strategies like supervised fine-tuning and reinforcement learning from human feedback have enhanced their safety, these methods primarily focus on natural languages, which may not generalize to other domains. This paper introduces CodeAttack, a framework that transforms natural language inputs into code inputs, presenting a novel environment for testing the safety generalization of LLMs. Our comprehensive studies on state-of-the-art LLMs including GPT-4, Claude-2, and Llama-2 series reveal a common safety vulnerability of these models against code input: CodeAttack bypasses the safety guardrails of all models more than 80% of the time. We find that a larger distribution gap between CodeAttack and natural language leads to weaker safety generalization, such as encoding natural language input with data structures. Furthermore, we give two hypotheses about the success of CodeAttack: (1) the misaligned bias acquired by LLMs during code training, prioritizing code completion over avoiding the potential safety risk; (2) the limited self-evaluation capability regarding the safety of their code outputs. Finally, we analyze potential mitigation measures. These findings highlight new safety risks in the code domain and the need for more robust safety alignment algorithms to match the code capabilities of LLMs.
4/9/2024