Causal Machine Learning for Cost-Effective Allocation of Development Aid
2401.16986
0
0
👀
Abstract
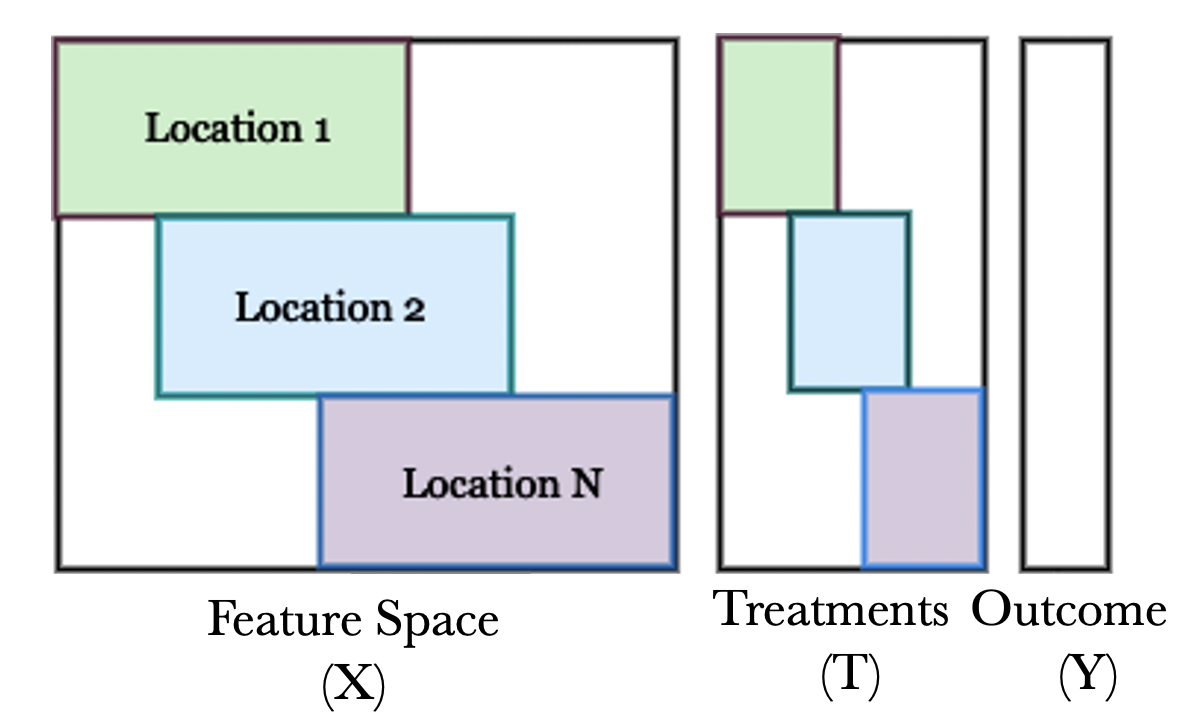
The Sustainable Development Goals (SDGs) of the United Nations provide a blueprint of a better future by 'leaving no one behind', and, to achieve the SDGs by 2030, poor countries require immense volumes of development aid. In this paper, we develop a causal machine learning framework for predicting heterogeneous treatment effects of aid disbursements to inform effective aid allocation. Specifically, our framework comprises three components: (i) a balancing autoencoder that uses representation learning to embed high-dimensional country characteristics while addressing treatment selection bias; (ii) a counterfactual generator to compute counterfactual outcomes for varying aid volumes to address small sample-size settings; and (iii) an inference model that is used to predict heterogeneous treatment-response curves. We demonstrate the effectiveness of our framework using data with official development aid earmarked to end HIV/AIDS in 105 countries, amounting to more than USD 5.2 billion. For this, we first show that our framework successfully computes heterogeneous treatment-response curves using semi-synthetic data. Then, we demonstrate our framework using real-world HIV data. Our framework points to large opportunities for a more effective aid allocation, suggesting that the total number of new HIV infections could be reduced by up to 3.3% (~50,000 cases) compared to the current allocation practice.
Create account to get full access
Overview
- The United Nations Sustainable Development Goals (SDGs) aim to create a better future for all, but achieving them by 2030 requires significant development aid for poorer countries.
- This paper proposes a causal machine learning framework to predict the heterogeneous treatment effects of aid disbursements, which can inform more effective allocation of development aid.
- The framework includes three key components: a balancing autoencoder for representation learning and addressing treatment selection bias, a counterfactual generator to handle small sample sizes, and an inference model to predict heterogeneous treatment-response curves.
- The researchers demonstrate the effectiveness of their framework using data on over $5.2 billion in official development aid for ending HIV/AIDS in 105 countries.
Plain English Explanation
The United Nations has set ambitious Sustainable Development Goals (SDGs) to create a better world by 2030, but achieving these goals will require huge amounts of development aid for poorer countries. This paper introduces a new machine learning approach to help make sure that aid money is used as effectively as possible.
The key idea is to build a system that can predict how different amounts of aid will impact different countries. This is important because the effects of aid can vary a lot depending on the country's specific circumstances. The researchers' framework has three main parts:
-
A balancing autoencoder that learns a compact representation of each country's characteristics while also accounting for how countries are selected to receive aid. This helps address the problem of "selection bias" - the fact that aid isn't randomly distributed but goes to countries with certain traits.
-
A "counterfactual generator" that can estimate what would happen in a country if it received a different amount of aid than it actually did. This is important because we can't directly observe these counterfactual scenarios in the real world.
-
An inference model that uses the first two components to predict how a country's outcomes (like the number of new HIV cases) would change with different levels of aid.
The researchers tested this framework on data about over $5.2 billion in aid for fighting HIV/AIDS in 105 countries. They found that their approach could identify ways to allocate the aid more effectively, potentially reducing new HIV infections by up to 3.3% (about 50,000 cases) compared to the current approach.
Technical Explanation
The paper proposes a causal machine learning framework for predicting heterogeneous treatment effects of development aid disbursements. This can inform more effective allocation of aid to achieve the UN's Sustainable Development Goals.
The framework has three key components:
-
A balancing autoencoder that uses representation learning to embed high-dimensional country characteristics while addressing treatment selection bias. This helps account for the fact that aid is not randomly distributed but goes to countries with certain attributes.
-
A counterfactual generator that can compute counterfactual outcomes for varying aid volumes. This addresses the challenge of small sample sizes, as we can't directly observe what would have happened in a country under different aid levels.
-
An inference model that predicts heterogeneous treatment-response curves, showing how country outcomes would change with different aid amounts.
The researchers demonstrate the effectiveness of this framework using data on over $5.2 billion in official development aid for ending HIV/AIDS in 105 countries. They first validate the framework on semi-synthetic data, then apply it to the real-world HIV data.
The results suggest that the current aid allocation could be improved. The framework indicates that the total number of new HIV infections could be reduced by up to 3.3% (around 50,000 cases) compared to the status quo approach.
Critical Analysis
The paper makes a valuable contribution by developing a comprehensive causal machine learning framework to inform more effective allocation of development aid. The use of a balancing autoencoder to address treatment selection bias is a strong technical innovation, as is the integration of a counterfactual generator to handle small sample sizes.
However, the paper does acknowledge some limitations. The framework relies on the availability of detailed country-level data, which may not always be the case, especially for poorer nations. There are also challenges in accurately modeling complex real-world socioeconomic dynamics that influence the impact of aid.
Additionally, the paper focuses on predicting heterogeneous treatment effects at the country level. Further research could explore how to translate these insights into actionable aid allocation strategies, taking into account implementation feasibility and political constraints.
Other recent works have also explored causal machine learning approaches for estimating treatment effects. Comparing the strengths and weaknesses of different frameworks could yield valuable insights.
Overall, this paper presents a promising step forward in using data-driven techniques to improve the effectiveness of development aid. But more research is needed to fully realize the potential of these methods in real-world aid allocation decisions.
Conclusion
This paper introduces a novel causal machine learning framework for predicting heterogeneous treatment effects of development aid. By accounting for factors like selection bias and small sample sizes, the framework can identify opportunities to allocate aid more effectively and maximize its impact.
The researchers demonstrate the effectiveness of their approach using data on over $5.2 billion in aid for fighting HIV/AIDS in 105 countries. Their results suggest that smarter aid allocation could reduce new HIV infections by up to 3.3%, a significant improvement.
While the framework has some limitations, it represents an important advance in using data-driven techniques to inform development aid decisions. As countries work towards the UN's ambitious Sustainable Development Goals, tools like this could play a crucial role in ensuring limited resources are used as effectively as possible to create a better future for all.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Uplift Modeling Under Limited Supervision
George Panagopoulos, Daniele Malitesta, Fragkiskos D. Malliaros, Jun Pang
0
0
Estimating causal effects in e-commerce tends to involve costly treatment assignments which can be impractical in large-scale settings. Leveraging machine learning to predict such treatment effects without actual intervention is a standard practice to diminish the risk. However, existing methods for treatment effect prediction tend to rely on training sets of substantial size, which are built from real experiments and are thus inherently risky to create. In this work we propose a graph neural network to diminish the required training set size, relying on graphs that are common in e-commerce data. Specifically, we view the problem as node regression with a restricted number of labeled instances, develop a two-model neural architecture akin to previous causal effect estimators, and test varying message-passing layers for encoding. Furthermore, as an extra step, we combine the model with an acquisition function to guide the creation of the training set in settings with extremely low experimental budget. The framework is flexible since each step can be used separately with other models or treatment policies. The experiments on real large-scale networks indicate a clear advantage of our methodology over the state of the art, which in many cases performs close to random, underlining the need for models that can generalize with limited supervision to reduce experimental risks.
6/10/2024
🎲
Metalearners for Ranking Treatment Effects
Toon Vanderschueren, Wouter Verbeke, Felipe Moraes, Hugo Manuel Proenc{c}a
0
0
Efficiently allocating treatments with a budget constraint constitutes an important challenge across various domains. In marketing, for example, the use of promotions to target potential customers and boost conversions is limited by the available budget. While much research focuses on estimating causal effects, there is relatively limited work on learning to allocate treatments while considering the operational context. Existing methods for uplift modeling or causal inference primarily estimate treatment effects, without considering how this relates to a profit maximizing allocation policy that respects budget constraints. The potential downside of using these methods is that the resulting predictive model is not aligned with the operational context. Therefore, prediction errors are propagated to the optimization of the budget allocation problem, subsequently leading to a suboptimal allocation policy. We propose an alternative approach based on learning to rank. Our proposed methodology directly learns an allocation policy by prioritizing instances in terms of their incremental profit. We propose an efficient sampling procedure for the optimization of the ranking model to scale our methodology to large-scale data sets. Theoretically, we show how learning to rank can maximize the area under a policy's incremental profit curve. Empirically, we validate our methodology and show its effectiveness in practice through a series of experiments on both synthetic and real-world data.
5/6/2024

Estimating Causal Effects with Double Machine Learning -- A Method Evaluation
Jonathan Fuhr, Philipp Berens, Dominik Papies
0
0
The estimation of causal effects with observational data continues to be a very active research area. In recent years, researchers have developed new frameworks which use machine learning to relax classical assumptions necessary for the estimation of causal effects. In this paper, we review one of the most prominent methods - double/debiased machine learning (DML) - and empirically evaluate it by comparing its performance on simulated data relative to more traditional statistical methods, before applying it to real-world data. Our findings indicate that the application of a suitably flexible machine learning algorithm within DML improves the adjustment for various nonlinear confounding relationships. This advantage enables a departure from traditional functional form assumptions typically necessary in causal effect estimation. However, we demonstrate that the method continues to critically depend on standard assumptions about causal structure and identification. When estimating the effects of air pollution on housing prices in our application, we find that DML estimates are consistently larger than estimates of less flexible methods. From our overall results, we provide actionable recommendations for specific choices researchers must make when applying DML in practice.
5/1/2024
Federated Learning for Estimating Heterogeneous Treatment Effects
Disha Makhija, Joydeep Ghosh, Yejin Kim
0
0
Machine learning methods for estimating heterogeneous treatment effects (HTE) facilitate large-scale personalized decision-making across various domains such as healthcare, policy making, education, and more. Current machine learning approaches for HTE require access to substantial amounts of data per treatment, and the high costs associated with interventions makes centrally collecting so much data for each intervention a formidable challenge. To overcome this obstacle, in this work, we propose a novel framework for collaborative learning of HTE estimators across institutions via Federated Learning. We show that even under a diversity of interventions and subject populations across clients, one can jointly learn a common feature representation, while concurrently and privately learning the specific predictive functions for outcomes under distinct interventions across institutions. Our framework and the associated algorithm are based on this insight, and leverage tabular transformers to map multiple input data to feature representations which are then used for outcome prediction via multi-task learning. We also propose a novel way of federated training of personalised transformers that can work with heterogeneous input feature spaces. Experimental results on real-world clinical trial data demonstrate the effectiveness of our method.
6/26/2024