Causal Rule Forest: Toward Interpretable and Precise Treatment Effect Estimation

0
👨🏫
Sign in to get full access
Overview
- Personalized treatment recommendations require understanding and inferencing Heterogeneous Treatment Effects (HTE) and Conditional Average Treatment Effects (CATE)
- Many state-of-the-art approaches achieve good performance on benchmarks, but their complex models reduce interpretability
- To address this, the paper introduces Causal Rule Forest (CRF), a novel approach to learn interpretable multi-level Boolean rules from data
- Training other causal inference models with CRF-learned data representation can improve their predictive performance while maintaining interpretability
Plain English Explanation
When developing personalized treatments or interventions, it's important to understand how the effects of those treatments can vary across different people or groups. This is known as Heterogeneous Treatment Effects (HTE) and Conditional Average Treatment Effects (CATE). Many advanced techniques can estimate HTE well, but their complex models make it hard to interpret the underlying patterns and understand why some people respond differently to the treatment.
To address this, the researchers developed a new approach called Causal Rule Forest (CRF). CRF learns interpretable rules from the data that explain how the treatment effects vary. By using the data representations learned by CRF to train other causal inference models, the researchers were able to improve the predictive performance of those models while still keeping them interpretable. This allows us to both accurately estimate the personalized treatment effects and understand the underlying reasons for the differences.
The goal is to advance personalized interventions and policies by providing models that are both accurate and interpretable. This paves the way for future work to make these techniques even more scalable and applicable to complex real-world causal inference challenges.
Technical Explanation
The key technical contribution of the paper is the Causal Rule Forest (CRF) approach. CRF is a novel method for learning interpretable multi-level Boolean rules from data to capture hidden patterns related to Heterogeneous Treatment Effects (HTE) and Conditional Average Treatment Effects (CATE).
The CRF model consists of an ensemble of decision trees, where each tree represents a set of interpretable Boolean rules. By training CRF on data with treatment and outcome information, it can uncover the key factors that drive differences in treatment effects across individuals or subgroups.
The researchers then use the data representations learned by CRF to train other causal inference models, such as CATE estimators. This allows these models to achieve better predictive performance on HTE and CATE estimation, while retaining the interpretability provided by the CRF-derived rules.
The paper evaluates CRF and the CRF-enhanced causal inference models on both benchmark datasets and simulation studies, demonstrating their potential to advance personalized interventions and policies.
Critical Analysis
The paper makes a compelling case for the importance of developing interpretable causal inference models that can accurately estimate Heterogeneous Treatment Effects (HTE) and Conditional Average Treatment Effects (CATE). The Causal Rule Forest (CRF) approach represents a promising step towards this goal, as it is able to learn interpretable rules that explain the underlying drivers of personalized treatment effects.
One potential limitation of the CRF approach is that the rule-based interpretability may be less suitable for modeling highly complex, nonlinear relationships in the data. The authors acknowledge this and suggest that future work could explore ways to combine the interpretability of CRF with the flexibility of other machine learning techniques.
Additionally, the paper does not provide a deep analysis of the scalability of CRF to large-scale, real-world datasets. As the authors note, further research is needed to enhance the scalability and applicability of this approach across a wider range of causal inference challenges.
Overall, the Causal Rule Forest represents an important step forward in the field of interpretable causal inference. By bridging the gap between predictive performance and heterogeneity interpretability, this work paves the way for more effective and personalized interventions and policies.
Conclusion
The paper introduces the Causal Rule Forest (CRF), a novel approach for learning interpretable multi-level Boolean rules to capture Heterogeneous Treatment Effects (HTE) and Conditional Average Treatment Effects (CATE). By using CRF-learned data representations to train other causal inference models, the researchers were able to improve the predictive performance of these models while retaining their interpretability.
This work represents an important advancement in the field of personalized interventions and policies, as it provides a way to both accurately estimate the individualized treatment effects and understand the underlying reasons for the differences. The potential of CRF to enhance interpretability in causal inference paves the way for future research to further improve the scalability and applicability of these techniques across complex real-world challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
0
Causal Rule Forest: Toward Interpretable and Precise Treatment Effect Estimation
Chan Hsu, Jun-Ting Wu, Yihuang Kang
Understanding and inferencing Heterogeneous Treatment Effects (HTE) and Conditional Average Treatment Effects (CATE) are vital for developing personalized treatment recommendations. Many state-of-the-art approaches achieve inspiring performance in estimating HTE on benchmark datasets or simulation studies. However, the indirect predicting manner and complex model architecture reduce the interpretability of these approaches. To mitigate the gap between predictive performance and heterogeneity interpretability, we introduce the Causal Rule Forest (CRF), a novel approach to learning hidden patterns from data and transforming the patterns into interpretable multi-level Boolean rules. By training the other interpretable causal inference models with data representation learned by CRF, we can reduce the predictive errors of these models in estimating HTE and CATE, while keeping their interpretability for identifying subgroups that a treatment is more effective. Our experiments underscore the potential of CRF to advance personalized interventions and policies, paving the way for future research to enhance its scalability and application across complex causal inference challenges.
Read more8/28/2024

0
Distilling interpretable causal trees from causal forests
Patrick Rehill
Machine learning methods for estimating treatment effect heterogeneity promise greater flexibility than existing methods that test a few pre-specified hypotheses. However, one problem these methods can have is that it can be challenging to extract insights from complicated machine learning models. A high-dimensional distribution of conditional average treatment effects may give accurate, individual-level estimates, but it can be hard to understand the underlying patterns; hard to know what the implications of the analysis are. This paper proposes the Distilled Causal Tree, a method for distilling a single, interpretable causal tree from a causal forest. This compares well to existing methods of extracting a single tree, particularly in noisy data or high-dimensional data where there are many correlated features. Here it even outperforms the base causal forest in most simulations. Its estimates are doubly robust and asymptotically normal just as those of the causal forest are.
Read more8/6/2024

0
CURLS: Causal Rule Learning for Subgroups with Significant Treatment Effect
Jiehui Zhou, Linxiao Yang, Xingyu Liu, Xinyue Gu, Liang Sun, Wei Chen
In causal inference, estimating heterogeneous treatment effects (HTE) is critical for identifying how different subgroups respond to interventions, with broad applications in fields such as precision medicine and personalized advertising. Although HTE estimation methods aim to improve accuracy, how to provide explicit subgroup descriptions remains unclear, hindering data interpretation and strategic intervention management. In this paper, we propose CURLS, a novel rule learning method leveraging HTE, which can effectively describe subgroups with significant treatment effects. Specifically, we frame causal rule learning as a discrete optimization problem, finely balancing treatment effect with variance and considering the rule interpretability. We design an iterative procedure based on the minorize-maximization algorithm and solve a submodular lower bound as an approximation for the original. Quantitative experiments and qualitative case studies verify that compared with state-of-the-art methods, CURLS can find subgroups where the estimated and true effects are 16.1% and 13.8% higher and the variance is 12.0% smaller, while maintaining similar or better estimation accuracy and rule interpretability. Code is available at https://osf.io/zwp2k/.
Read more7/2/2024
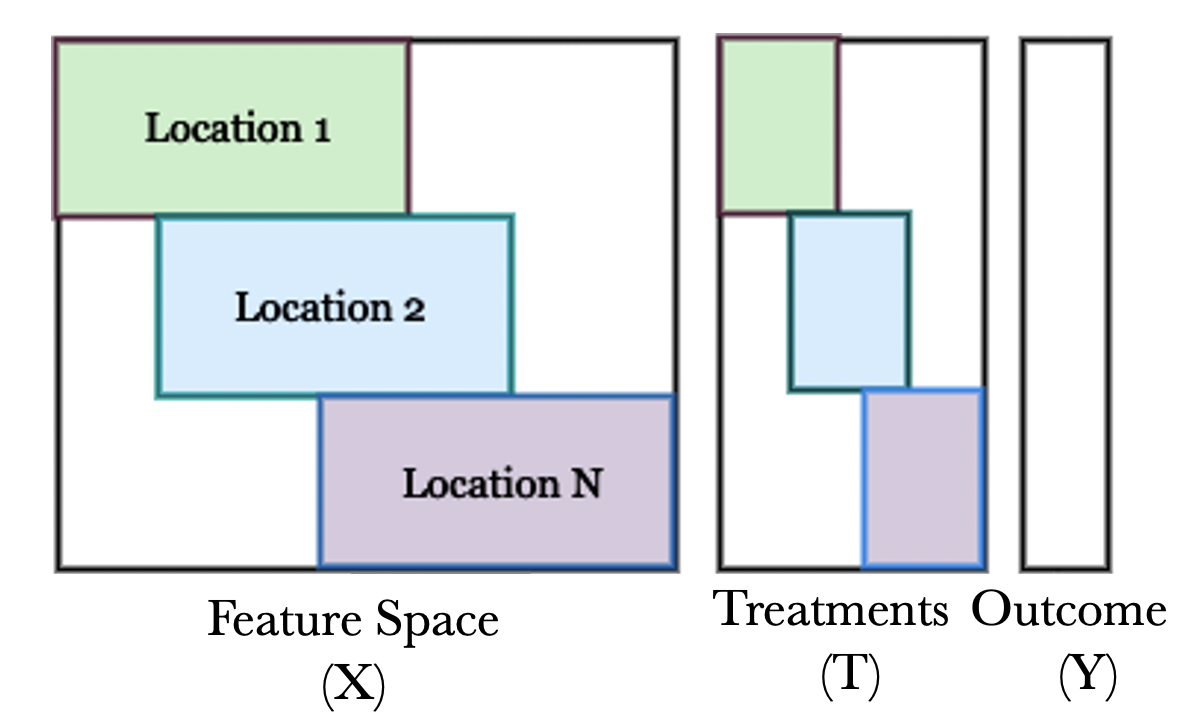
0
Federated Learning for Estimating Heterogeneous Treatment Effects
Disha Makhija, Joydeep Ghosh, Yejin Kim
Machine learning methods for estimating heterogeneous treatment effects (HTE) facilitate large-scale personalized decision-making across various domains such as healthcare, policy making, education, and more. Current machine learning approaches for HTE require access to substantial amounts of data per treatment, and the high costs associated with interventions makes centrally collecting so much data for each intervention a formidable challenge. To overcome this obstacle, in this work, we propose a novel framework for collaborative learning of HTE estimators across institutions via Federated Learning. We show that even under a diversity of interventions and subject populations across clients, one can jointly learn a common feature representation, while concurrently and privately learning the specific predictive functions for outcomes under distinct interventions across institutions. Our framework and the associated algorithm are based on this insight, and leverage tabular transformers to map multiple input data to feature representations which are then used for outcome prediction via multi-task learning. We also propose a novel way of federated training of personalised transformers that can work with heterogeneous input feature spaces. Experimental results on real-world clinical trial data demonstrate the effectiveness of our method.
Read more6/26/2024