Certifiable Black-Box Attacks with Randomized Adversarial Examples: Breaking Defenses with Provable Confidence

0
✅
Sign in to get full access
Overview
- Black-box adversarial attacks can subvert machine learning models, but existing attacks can be mitigated by state-of-the-art defenses.
- This paper proposes a new paradigm of "certifiable black-box attacks" that can guarantee the attack success probability of adversarial examples without querying the target model.
- This unveils significant vulnerabilities of machine learning models compared to traditional black-box attacks.
Plain English Explanation
Machine learning models, such as those used for image recognition or speech-to-text, can be tricked into making mistakes through adversarial attacks. These are small, carefully crafted changes to input data that cause the model to output an incorrect result, even though the changes are barely noticeable to humans.
Existing "black-box" adversarial attacks craft these adversarial examples by repeatedly querying the target model and observing its responses. They can also leverage a "surrogate" model that behaves similarly to the target model. However, recent defenses have been able to detect and mitigate these types of attacks.
This paper proposes a new approach: "certifiable black-box attacks." Rather than querying the target model, these attacks can theoretically guarantee the probability of successfully fooling the model, without ever interacting with it. This reveals significant vulnerabilities in machine learning models that go beyond what traditional black-box attacks have shown.
For example, these certifiable attacks can break strong defenses with a guaranteed level of confidence. They can also construct a wide space of potential adversarial examples that all have a high probability of success, without needing to check each one.
Technical Explanation
The key innovation in this paper is a novel theoretical foundation for ensuring the attack success probability (ASP) of black-box adversarial examples, without querying the target model.
The researchers establish a framework for generating "randomized" adversarial examples, where small, random perturbations are added to the input. They prove that by carefully designing these randomized perturbations, they can guarantee a minimum level of ASP, even without testing the examples on the target model.
Building on this theory, the paper proposes several techniques to craft these randomized adversarial examples while minimizing the size of the perturbations, to make the examples more imperceptible to humans.
The researchers comprehensively evaluate their certifiable black-box attacks on benchmark datasets like CIFAR-10/100, ImageNet, and LibriSpeech. They benchmark against 16 state-of-the-art empirical black-box attacks and test against various defense mechanisms in computer vision and speech recognition.
Both the theoretical analysis and experimental results demonstrate the significant capabilities of this new class of certifiable black-box attacks, which can outperform traditional approaches in terms of attack strength and robustness to defenses.
Critical Analysis
The paper makes a compelling case for the power of certifiable black-box attacks, but it's important to consider some potential limitations and caveats.
While the theoretical foundations are rigorous, the practical implementation still requires certain assumptions, such as having access to a good surrogate model. In a true "black-box" scenario, obtaining such a model may be challenging.
Additionally, the experiments focus on standard benchmark datasets and defenses. Further research would be needed to evaluate the real-world applicability and impact of these attacks on production machine learning systems.
It's also worth considering the ethical implications of developing more powerful adversarial attack techniques. While the research aims to uncover vulnerabilities, the techniques could potentially be misused by bad actors. Responsible disclosure and thoughtful deployment of defenses will be crucial.
Conclusion
This paper presents a novel paradigm of "certifiable black-box attacks" that can guarantee the attack success probability of adversarial examples without querying the target model. This unveils significant vulnerabilities in modern machine learning systems, going beyond what traditional black-box attacks have shown.
The theoretical foundations and experimental results demonstrate the power of this new attack approach, which can break strong defenses and construct a wide space of high-probability adversarial examples. While further research is needed to address practical limitations, this work represents an important advance in our understanding of the security and robustness of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✅
0
Certifiable Black-Box Attacks with Randomized Adversarial Examples: Breaking Defenses with Provable Confidence
Hanbin Hong, Xinyu Zhang, Binghui Wang, Zhongjie Ba, Yuan Hong
Black-box adversarial attacks have demonstrated strong potential to compromise machine learning models by iteratively querying the target model or leveraging transferability from a local surrogate model. Recently, such attacks can be effectively mitigated by state-of-the-art (SOTA) defenses, e.g., detection via the pattern of sequential queries, or injecting noise into the model. To our best knowledge, we take the first step to study a new paradigm of black-box attacks with provable guarantees -- certifiable black-box attacks that can guarantee the attack success probability (ASP) of adversarial examples before querying over the target model. This new black-box attack unveils significant vulnerabilities of machine learning models, compared to traditional empirical black-box attacks, e.g., breaking strong SOTA defenses with provable confidence, constructing a space of (infinite) adversarial examples with high ASP, and the ASP of the generated adversarial examples is theoretically guaranteed without verification/queries over the target model. Specifically, we establish a novel theoretical foundation for ensuring the ASP of the black-box attack with randomized adversarial examples (AEs). Then, we propose several novel techniques to craft the randomized AEs while reducing the perturbation size for better imperceptibility. Finally, we have comprehensively evaluated the certifiable black-box attacks on the CIFAR10/100, ImageNet, and LibriSpeech datasets, while benchmarking with 16 SOTA black-box attacks, against various SOTA defenses in the domains of computer vision and speech recognition. Both theoretical and experimental results have validated the significance of the proposed attack. The code and all the benchmarks are available at url{https://github.com/datasec-lab/CertifiedAttack}.
Read more9/9/2024
0
From Attack to Defense: Insights into Deep Learning Security Measures in Black-Box Settings
Firuz Juraev, Mohammed Abuhamad, Eric Chan-Tin, George K. Thiruvathukal, Tamer Abuhmed
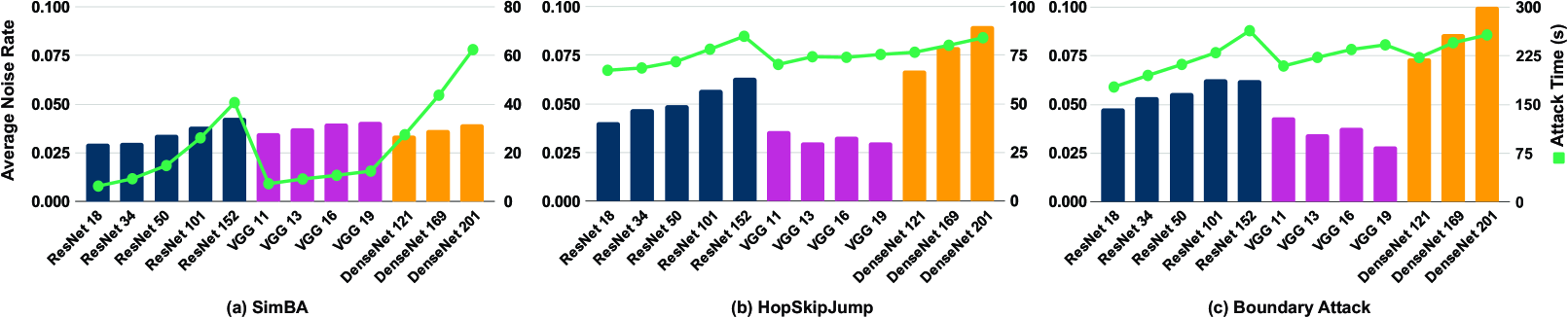
Deep Learning (DL) is rapidly maturing to the point that it can be used in safety- and security-crucial applications. However, adversarial samples, which are undetectable to the human eye, pose a serious threat that can cause the model to misbehave and compromise the performance of such applications. Addressing the robustness of DL models has become crucial to understanding and defending against adversarial attacks. In this study, we perform comprehensive experiments to examine the effect of adversarial attacks and defenses on various model architectures across well-known datasets. Our research focuses on black-box attacks such as SimBA, HopSkipJump, MGAAttack, and boundary attacks, as well as preprocessor-based defensive mechanisms, including bits squeezing, median smoothing, and JPEG filter. Experimenting with various models, our results demonstrate that the level of noise needed for the attack increases as the number of layers increases. Moreover, the attack success rate decreases as the number of layers increases. This indicates that model complexity and robustness have a significant relationship. Investigating the diversity and robustness relationship, our experiments with diverse models show that having a large number of parameters does not imply higher robustness. Our experiments extend to show the effects of the training dataset on model robustness. Using various datasets such as ImageNet-1000, CIFAR-100, and CIFAR-10 are used to evaluate the black-box attacks. Considering the multiple dimensions of our analysis, e.g., model complexity and training dataset, we examined the behavior of black-box attacks when models apply defenses. Our results show that applying defense strategies can significantly reduce attack effectiveness. This research provides in-depth analysis and insight into the robustness of DL models against various attacks, and defenses.
Read more5/6/2024
🔎
0
Distributed Black-box Attack: Do Not Overestimate Black-box Attacks
Han Wu, Sareh Rowlands, Johan Wahlstrom
Black-box adversarial attacks can fool image classifiers into misclassifying images without requiring access to model structure and weights. Recent studies have reported attack success rates of over 95% with less than 1,000 queries. The question then arises of whether black-box attacks have become a real threat against IoT devices that rely on cloud APIs to achieve image classification. To shed some light on this, note that prior research has primarily focused on increasing the success rate and reducing the number of queries. However, another crucial factor for black-box attacks against cloud APIs is the time required to perform the attack. This paper applies black-box attacks directly to cloud APIs rather than to local models, thereby avoiding mistakes made in prior research that applied the perturbation before image encoding and pre-processing. Further, we exploit load balancing to enable distributed black-box attacks that can reduce the attack time by a factor of about five for both local search and gradient estimation methods.
Read more7/8/2024
🧠
0
Et Tu Certifications: Robustness Certificates Yield Better Adversarial Examples
Andrew C. Cullen, Shijie Liu, Paul Montague, Sarah M. Erfani, Benjamin I. P. Rubinstein
In guaranteeing the absence of adversarial examples in an instance's neighbourhood, certification mechanisms play an important role in demonstrating neural net robustness. In this paper, we ask if these certifications can compromise the very models they help to protect? Our new emph{Certification Aware Attack} exploits certifications to produce computationally efficient norm-minimising adversarial examples $74 %$ more often than comparable attacks, while reducing the median perturbation norm by more than $10%$. While these attacks can be used to assess the tightness of certification bounds, they also highlight that releasing certifications can paradoxically reduce security.
Read more6/13/2024