Characterization of Large Language Model Development in the Datacenter
2403.07648
1
0

Abstract
Large Language Models (LLMs) have presented impressive performance across several transformative tasks. However, it is non-trivial to efficiently utilize large-scale cluster resources to develop LLMs, often riddled with numerous challenges such as frequent hardware failures, intricate parallelization strategies, and imbalanced resource utilization. In this paper, we present an in-depth characterization study of a six-month LLM development workload trace collected from our GPU datacenter Acme. Specifically, we investigate discrepancies between LLMs and prior task-specific Deep Learning (DL) workloads, explore resource utilization patterns, and identify the impact of various job failures. Our analysis summarizes hurdles we encountered and uncovers potential opportunities to optimize systems tailored for LLMs. Furthermore, we introduce our system efforts: (1) fault-tolerant pretraining, which enhances fault tolerance through LLM-involved failure diagnosis and automatic recovery. (2) decoupled scheduling for evaluation, which achieves timely performance feedback via trial decomposition and scheduling optimization.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper characterizes the development and training of large language models (LLMs) in data centers, focusing on the computational resources and processes involved.
- The researchers analyze the hardware, software, and workflow used to create and refine these powerful AI models that underpin many modern language applications.
- Key insights include the immense scale of computing power required, the iterative nature of the model development cycle, and the significant energy and environmental costs associated with LLM training.
Plain English Explanation
Large language models, or LLMs, are a type of artificial intelligence that can understand and generate human-like text. These models have become incredibly powerful and are used in a wide range of language-based applications, from chatbots to content creation tools.
However, the process of developing and training these LLMs is extremely resource-intensive. This paper takes a close look at what goes on behind the scenes in data centers where LLMs are created.
The researchers found that training a single LLM requires an immense amount of computing power - thousands of powerful graphics processing units (GPUs) working in parallel for weeks or even months. The process is highly iterative, with the models being trained, tested, refined, and retrained over and over again to achieve the desired capabilities.
All of this computational work comes at a significant cost, both in terms of the energy consumed and the environmental impact. The sheer scale of the data centers housing the LLM development infrastructure is staggering, with rows upon rows of servers and cooling systems that collectively use enormous amounts of electricity.
The researchers hope that by shedding light on the realities of LLM development, they can inspire efforts to make the process more sustainable and efficient as these models become increasingly central to our digital lives.
Technical Explanation
The paper begins by outlining the key stages of the LLM development pipeline, which includes data curation, model architecture design, training, and iterative fine-tuning. The authors then provide a detailed characterization of the computational resources required at each step.
They find that training a single LLM model can require the use of thousands of high-performance GPUs working in parallel for weeks or months. The models undergo constant refinement through a cyclical process of training, evaluation, and further fine-tuning. This iterative workflow is essential for achieving the desired performance and capabilities.
In addition to the immense computational power, the researchers also analyze the energy consumption and environmental impact of LLM development. They estimate that the data centers housing this infrastructure can use the equivalent electricity of thousands of homes, with a corresponding carbon footprint.
The paper concludes by discussing the implications of these findings, highlighting the need for more sustainable approaches to LLM development as these models become increasingly ubiquitous in various industries and applications.
Critical Analysis
The researchers provide a comprehensive and insightful characterization of the computational resources and processes involved in LLM development. By quantifying the scale of the required hardware, energy consumption, and iterative nature of the training workflow, the paper sheds valuable light on the hidden costs and challenges associated with creating these powerful AI models.
One potential limitation of the study is the scope - it focuses on a specific set of LLM development practices and may not fully capture the diversity of approaches used by different organizations or research teams. Additionally, the energy and environmental impact estimates are based on certain assumptions and may vary depending on the specific data center infrastructure and energy sources.
Further research could explore alternative LLM development strategies that aim to reduce the computational and energy footprint, such as more efficient model architectures, data-efficient learning algorithms, or the use of renewable energy sources in data centers. Investigating the trade-offs between model performance, development costs, and environmental sustainability would be a valuable area for future study.
Overall, this paper makes a significant contribution to our understanding of the real-world challenges and implications of large-scale LLM development, which is an important consideration as these models become increasingly integral to our digital landscape.
Conclusion
This paper provides a detailed characterization of the computational resources and processes involved in the development of large language models (LLMs) within data centers. The researchers shed light on the immense scale of the required hardware, the iterative nature of the training workflow, and the significant energy and environmental costs associated with LLM development.
By quantifying these aspects of the LLM creation process, the authors hope to inspire efforts towards more sustainable and efficient approaches as these powerful AI models become increasingly central to our digital lives. The insights from this study can inform the design of future LLM development infrastructure and motivate the exploration of alternative strategies to reduce the environmental impact of these transformative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
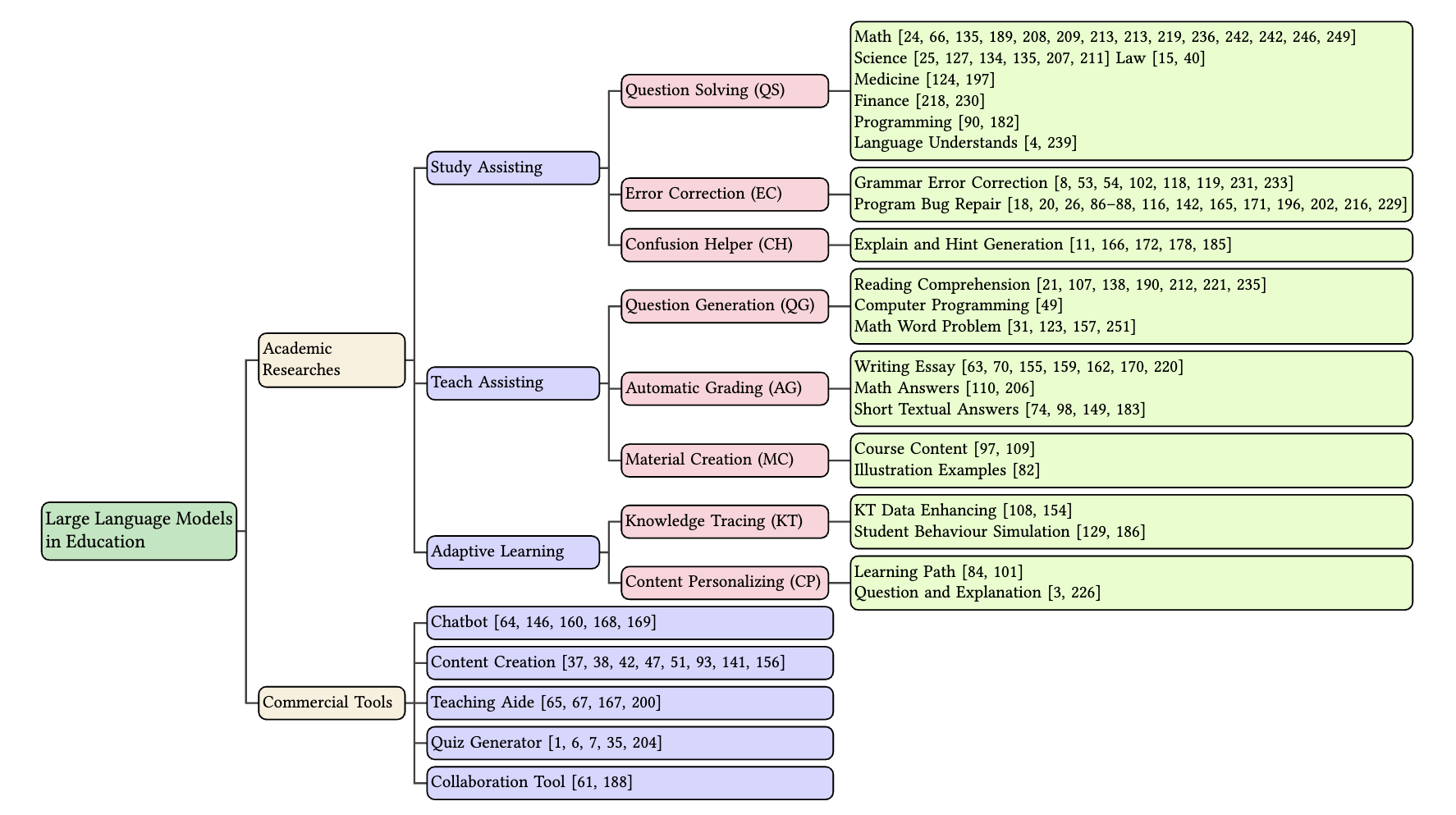
Large Language Models for Education: A Survey and Outlook
Shen Wang, Tianlong Xu, Hang Li, Chaoli Zhang, Joleen Liang, Jiliang Tang, Philip S. Yu, Qingsong Wen
0
0
The advent of Large Language Models (LLMs) has brought in a new era of possibilities in the realm of education. This survey paper summarizes the various technologies of LLMs in educational settings from multifaceted perspectives, encompassing student and teacher assistance, adaptive learning, and commercial tools. We systematically review the technological advancements in each perspective, organize related datasets and benchmarks, and identify the risks and challenges associated with deploying LLMs in education. Furthermore, we outline future research opportunities, highlighting the potential promising directions. Our survey aims to provide a comprehensive technological picture for educators, researchers, and policymakers to harness the power of LLMs to revolutionize educational practices and foster a more effective personalized learning environment.
4/3/2024
💬
Exploring the landscape of large language models: Foundations, techniques, and challenges
Milad Moradi, Ke Yan, David Colwell, Matthias Samwald, Rhona Asgari
0
0
In this review paper, we delve into the realm of Large Language Models (LLMs), covering their foundational principles, diverse applications, and nuanced training processes. The article sheds light on the mechanics of in-context learning and a spectrum of fine-tuning approaches, with a special focus on methods that optimize efficiency in parameter usage. Additionally, it explores how LLMs can be more closely aligned with human preferences through innovative reinforcement learning frameworks and other novel methods that incorporate human feedback. The article also examines the emerging technique of retrieval augmented generation, integrating external knowledge into LLMs. The ethical dimensions of LLM deployment are discussed, underscoring the need for mindful and responsible application. Concluding with a perspective on future research trajectories, this review offers a succinct yet comprehensive overview of the current state and emerging trends in the evolving landscape of LLMs, serving as an insightful guide for both researchers and practitioners in artificial intelligence.
4/19/2024
💬
Large Human Language Models: A Need and the Challenges
Nikita Soni, H. Andrew Schwartz, Jo~ao Sedoc, Niranjan Balasubramanian
0
0
As research in human-centered NLP advances, there is a growing recognition of the importance of incorporating human and social factors into NLP models. At the same time, our NLP systems have become heavily reliant on LLMs, most of which do not model authors. To build NLP systems that can truly understand human language, we must better integrate human contexts into LLMs. This brings to the fore a range of design considerations and challenges in terms of what human aspects to capture, how to represent them, and what modeling strategies to pursue. To address these, we advocate for three positions toward creating large human language models (LHLMs) using concepts from psychological and behavioral sciences: First, LM training should include the human context. Second, LHLMs should recognize that people are more than their group(s). Third, LHLMs should be able to account for the dynamic and temporally-dependent nature of the human context. We refer to relevant advances and present open challenges that need to be addressed and their possible solutions in realizing these goals.
5/10/2024
💬
Apprentices to Research Assistants: Advancing Research with Large Language Models
M. Namvarpour, A. Razi
0
0
Large Language Models (LLMs) have emerged as powerful tools in various research domains. This article examines their potential through a literature review and firsthand experimentation. While LLMs offer benefits like cost-effectiveness and efficiency, challenges such as prompt tuning, biases, and subjectivity must be addressed. The study presents insights from experiments utilizing LLMs for qualitative analysis, highlighting successes and limitations. Additionally, it discusses strategies for mitigating challenges, such as prompt optimization techniques and leveraging human expertise. This study aligns with the 'LLMs as Research Tools' workshop's focus on integrating LLMs into HCI data work critically and ethically. By addressing both opportunities and challenges, our work contributes to the ongoing dialogue on their responsible application in research.
4/10/2024