Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model
2404.04167
0
0
Abstract
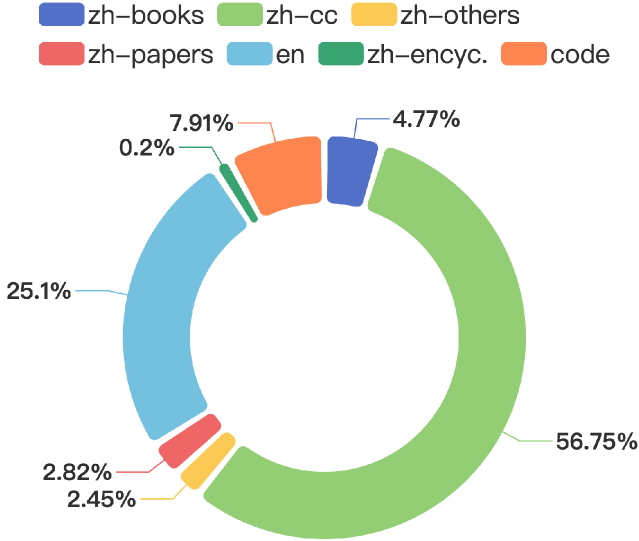
In this study, we introduce CT-LLM, a 2B large language model (LLM) that illustrates a pivotal shift towards prioritizing the Chinese language in developing LLMs. Uniquely initiated from scratch, CT-LLM diverges from the conventional methodology by primarily incorporating Chinese textual data, utilizing an extensive corpus of 1,200 billion tokens, including 800 billion Chinese tokens, 300 billion English tokens, and 100 billion code tokens. This strategic composition facilitates the model's exceptional proficiency in understanding and processing Chinese, a capability further enhanced through alignment techniques. Demonstrating remarkable performance on the CHC-Bench, CT-LLM excels in Chinese language tasks, and showcases its adeptness in English through SFT. This research challenges the prevailing paradigm of training LLMs predominantly on English corpora and then adapting them to other languages, broadening the horizons for LLM training methodologies. By open-sourcing the full process of training a Chinese LLM, including a detailed data processing procedure with the obtained Massive Appropriate Pretraining Chinese Corpus (MAP-CC), a well-chosen multidisciplinary Chinese Hard Case Benchmark (CHC-Bench), and the 2B-size Chinese Tiny LLM (CT-LLM), we aim to foster further exploration and innovation in both academia and industry, paving the way for more inclusive and versatile language models.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper discusses the development of a Chinese-centric large language model (LLM) called "Chinese Tiny LLM", which aims to provide strong language understanding and generation capabilities for the Chinese language.
- The research focuses on pretraining the model on a diverse corpus of Chinese text data, including web pages, books, and other sources, to build a robust foundation for downstream tasks.
- The authors evaluate the performance of Chinese Tiny LLM on various benchmarks and compare it to other popular Chinese language models, demonstrating its competitive performance and potential for practical applications.
Plain English Explanation
The researchers in this paper have created a new language model called "Chinese Tiny LLM" that is specifically designed to work well with the Chinese language. Language models are artificial intelligence systems that can understand and generate human language, and they are often used in applications like chatbots, translation tools, and text generation.
The key idea behind this research is to train the language model on a wide variety of Chinese text data, such as web pages, books, and other sources. This helps the model develop a deep understanding of the Chinese language, including its grammar, vocabulary, and common usage patterns. By focusing on Chinese-specific data and tasks, the researchers hope to create a model that outperforms other language models when it comes to working with Chinese text.
To evaluate the performance of Chinese Tiny LLM, the researchers tested it on a variety of benchmarks, which are standard tasks or datasets used to measure the capabilities of language models. They compared the model's performance to that of other popular Chinese language models, and found that Chinese Tiny LLM was able to match or even exceed the performance of these other models on many of the tasks. This suggests that the researchers' approach of pretraining the model on a diverse Chinese corpus was effective in building a strong and versatile language understanding system.
The potential applications of this research include [internal link: https://aimodels.fyi/papers/arxiv/measuring-taiwanese-mandarin-language-understanding] improved Chinese language processing for [internal link: https://aimodels.fyi/papers/arxiv/could-we-have-had-better-multilingual-llms] multilingual language models, [internal link: https://aimodels.fyi/papers/arxiv/cmb-comprehensive-medical-benchmark-chinese] better performance on Chinese-language tasks like medical diagnosis, and [internal link: https://aimodels.fyi/papers/arxiv/are-llms-effective-backbones-fine-tuning-experimental] enhanced fine-tuning capabilities for [internal link: https://aimodels.fyi/papers/arxiv/transforming-llms-into-cross-modal-cross-lingual] cross-modal and cross-lingual applications.
Technical Explanation
The researchers in this paper developed a Chinese-centric large language model (LLM) called "Chinese Tiny LLM" by pretraining the model on a diverse corpus of Chinese text data. The pretraining process involved collecting a large and varied dataset of Chinese web pages, books, and other sources, and using this data to train the model's parameters to understand and generate Chinese language effectively.
The model architecture used for Chinese Tiny LLM is based on the Transformer, a popular neural network design that has been widely used in state-of-the-art language models. The researchers made several modifications to the standard Transformer architecture to better suit the needs of Chinese language processing, such as incorporating additional tokenization and segmentation modules to handle the unique characteristics of Chinese text.
To evaluate the performance of Chinese Tiny LLM, the researchers tested the model on a variety of Chinese language benchmarks, including tasks related to [internal link: https://aimodels.fyi/papers/arxiv/measuring-taiwanese-mandarin-language-understanding] language understanding, [internal link: https://aimodels.fyi/papers/arxiv/could-we-have-had-better-multilingual-llms] multilingual capabilities, [internal link: https://aimodels.fyi/papers/arxiv/cmb-comprehensive-medical-benchmark-chinese] medical diagnosis, and [internal link: https://aimodels.fyi/papers/arxiv/are-llms-effective-backbones-fine-tuning-experimental] fine-tuning for [internal link: https://aimodels.fyi/papers/arxiv/transforming-llms-into-cross-modal-cross-lingual] cross-modal and cross-lingual applications. The results showed that Chinese Tiny LLM was able to match or exceed the performance of other popular Chinese language models on many of these tasks, demonstrating the effectiveness of the researchers' pretraining approach.
Critical Analysis
The researchers provide a thorough evaluation of Chinese Tiny LLM's performance on a range of Chinese language benchmarks, which gives a good sense of the model's capabilities and limitations. However, the paper does not delve deeply into the specific architectural choices and training procedures that were used to develop the model, which makes it difficult to fully assess the novelty and technical merits of the research.
Additionally, the paper does not discuss the potential limitations or caveats of the Chinese Tiny LLM approach, such as the potential for bias or lack of generalization to certain domains or tasks. It would be helpful for the researchers to acknowledge these types of issues and discuss potential avenues for further research and improvement.
Despite these minor shortcomings, the overall findings of the paper suggest that the Chinese Tiny LLM approach is a promising direction for developing high-performing Chinese language models that can be applied to a wide range of practical applications. The researchers have demonstrated the potential for this type of model to outperform existing Chinese language models, which could have significant implications for the field of natural language processing and its applications in the Chinese-speaking world.
Conclusion
In this paper, the researchers have developed a Chinese-centric large language model called "Chinese Tiny LLM" that is trained on a diverse corpus of Chinese text data. The model's performance on a variety of Chinese language benchmarks suggests that this approach is effective in building a robust and versatile language understanding system for the Chinese language.
The potential applications of this research include improved Chinese language processing for multilingual language models, better performance on Chinese-language tasks like medical diagnosis, and enhanced fine-tuning capabilities for cross-modal and cross-lingual applications. While the paper could benefit from more technical details and a discussion of potential limitations, the overall findings represent an important contribution to the field of natural language processing and its applications in the Chinese-speaking world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
↗️
Unveiling the Competitive Dynamics: A Comparative Evaluation of American and Chinese LLMs
Zhenhui Jiang, Jiaxin Li, Yang Liu
0
0
The strategic significance of Large Language Models (LLMs) in economic expansion, innovation, societal development, and national security has been increasingly recognized since the advent of ChatGPT. This study provides a comprehensive comparative evaluation of American and Chinese LLMs in both English and Chinese contexts. We proposed a comprehensive evaluation framework that encompasses natural language proficiency, disciplinary expertise, and safety and responsibility, and systematically assessed 16 prominent models from the US and China under various operational tasks and scenarios. Our key findings show that GPT 4-Turbo is at the forefront in English contexts, whereas Ernie-Bot 4 stands out in Chinese contexts. The study also highlights disparities in LLM performance across languages and tasks, stressing the necessity for linguistically and culturally nuanced model development. The complementary strengths of American and Chinese LLMs point to the value of Sino-US collaboration in advancing LLM technology. The research presents the current LLM competition landscape and offers valuable insights for policymakers and businesses regarding strategic LLM investments and development. Future work will expand on this framework to include emerging LLM multimodal capabilities and business application assessments.
5/14/2024

A Novel Paradigm Boosting Translation Capabilities of Large Language Models
Jiaxin Guo, Hao Yang, Zongyao Li, Daimeng Wei, Hengchao Shang, Xiaoyu Chen
0
0
This paper presents a study on strategies to enhance the translation capabilities of large language models (LLMs) in the context of machine translation (MT) tasks. The paper proposes a novel paradigm consisting of three stages: Secondary Pre-training using Extensive Monolingual Data, Continual Pre-training with Interlinear Text Format Documents, and Leveraging Source-Language Consistent Instruction for Supervised Fine-Tuning. Previous research on LLMs focused on various strategies for supervised fine-tuning (SFT), but their effectiveness has been limited. While traditional machine translation approaches rely on vast amounts of parallel bilingual data, our paradigm highlights the importance of using smaller sets of high-quality bilingual data. We argue that the focus should be on augmenting LLMs' cross-lingual alignment abilities during pre-training rather than solely relying on extensive bilingual data during SFT. Experimental results conducted using the Llama2 model, particularly on Chinese-Llama2 after monolingual augmentation, demonstrate the improved translation capabilities of LLMs. A significant contribution of our approach lies in Stage2: Continual Pre-training with Interlinear Text Format Documents, which requires less than 1B training data, making our method highly efficient. Additionally, in Stage3, we observed that setting instructions consistent with the source language benefits the supervised fine-tuning process. Experimental results demonstrate that our approach surpasses previous work and achieves superior performance compared to models such as NLLB-54B and GPT3.5-text-davinci-003, despite having a significantly smaller parameter count of only 7B or 13B. This achievement establishes our method as a pioneering strategy in the field of machine translation.
4/16/2024

Measuring Taiwanese Mandarin Language Understanding
Po-Heng Chen, Sijia Cheng, Wei-Lin Chen, Yen-Ting Lin, Yun-Nung Chen
0
0
The evaluation of large language models (LLMs) has drawn substantial attention in the field recently. This work focuses on evaluating LLMs in a Chinese context, specifically, for Traditional Chinese which has been largely underrepresented in existing benchmarks. We present TMLU, a holistic evaluation suit tailored for assessing the advanced knowledge and reasoning capability in LLMs, under the context of Taiwanese Mandarin. TMLU consists of an array of 37 subjects across social science, STEM, humanities, Taiwan-specific content, and others, ranging from middle school to professional levels. In addition, we curate chain-of-thought-like few-shot explanations for each subject to facilitate the evaluation of complex reasoning skills. To establish a comprehensive baseline, we conduct extensive experiments and analysis on 24 advanced LLMs. The results suggest that Chinese open-weight models demonstrate inferior performance comparing to multilingual proprietary ones, and open-weight models tailored for Taiwanese Mandarin lag behind the Simplified-Chinese counterparts. The findings indicate great headrooms for improvement, and emphasize the goal of TMLU to foster the development of localized Taiwanese-Mandarin LLMs. We release the benchmark and evaluation scripts for the community to promote future research.
4/1/2024

SambaLingo: Teaching Large Language Models New Languages
Zoltan Csaki, Bo Li, Jonathan Li, Qiantong Xu, Pian Pawakapan, Leon Zhang, Yun Du, Hengyu Zhao, Changran Hu, Urmish Thakker
0
0
Despite the widespread availability of LLMs, there remains a substantial gap in their capabilities and availability across diverse languages. One approach to address these issues has been to take an existing pre-trained LLM and continue to train it on new languages. While prior works have experimented with language adaptation, many questions around best practices and methodology have not been covered. In this paper, we present a comprehensive investigation into the adaptation of LLMs to new languages. Our study covers the key components in this process, including vocabulary extension, direct preference optimization and the data scarcity problem for human alignment in low-resource languages. We scale these experiments across 9 languages and 2 parameter scales (7B and 70B). We compare our models against Llama 2, Aya-101, XGLM, BLOOM and existing language experts, outperforming all prior published baselines. Additionally, all evaluation code and checkpoints are made public to facilitate future research.
4/10/2024