A Novel Paradigm Boosting Translation Capabilities of Large Language Models
2403.11430
0
0

Abstract
This paper presents a study on strategies to enhance the translation capabilities of large language models (LLMs) in the context of machine translation (MT) tasks. The paper proposes a novel paradigm consisting of three stages: Secondary Pre-training using Extensive Monolingual Data, Continual Pre-training with Interlinear Text Format Documents, and Leveraging Source-Language Consistent Instruction for Supervised Fine-Tuning. Previous research on LLMs focused on various strategies for supervised fine-tuning (SFT), but their effectiveness has been limited. While traditional machine translation approaches rely on vast amounts of parallel bilingual data, our paradigm highlights the importance of using smaller sets of high-quality bilingual data. We argue that the focus should be on augmenting LLMs' cross-lingual alignment abilities during pre-training rather than solely relying on extensive bilingual data during SFT. Experimental results conducted using the Llama2 model, particularly on Chinese-Llama2 after monolingual augmentation, demonstrate the improved translation capabilities of LLMs. A significant contribution of our approach lies in Stage2: Continual Pre-training with Interlinear Text Format Documents, which requires less than 1B training data, making our method highly efficient. Additionally, in Stage3, we observed that setting instructions consistent with the source language benefits the supervised fine-tuning process. Experimental results demonstrate that our approach surpasses previous work and achieves superior performance compared to models such as NLLB-54B and GPT3.5-text-davinci-003, despite having a significantly smaller parameter count of only 7B or 13B. This achievement establishes our method as a pioneering strategy in the field of machine translation.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a novel paradigm for boosting the translation capabilities of large language models (LLMs).
- The authors propose a new approach that leverages existing translation datasets and techniques to fine-tune LLMs, resulting in significant improvements in their translation performance.
- The paper also explores the potential of this paradigm shift to shape the future of machine translation, with implications for the development of more capable multilingual LLMs.
Plain English Explanation
The paper describes a new way to make large language models (LLMs) better at translating between different languages. LLMs are powerful AI systems that can understand and generate human language, but they often struggle with translation tasks.
The researchers developed a new technique that uses existing translation datasets and methods to "fine-tune" or further train the LLMs. This fine-tuning process helps the models learn the nuances of translation, allowing them to translate between languages more accurately and fluently.
The authors argue that this new paradigm, or way of approaching the problem, has the potential to revolutionize machine translation. By leveraging the capabilities of LLMs and combining them with proven translation techniques, they believe we could develop even more advanced multilingual AI systems in the future. This could lead to breakthroughs described in related papers on eliciting translation ability in LLMs, paradigm shifts in machine translation, and teaching LLMs new languages.
Technical Explanation
The paper proposes a novel paradigm for boosting the translation capabilities of large language models (LLMs). The authors leverage existing translation datasets and techniques to fine-tune LLMs, resulting in significant improvements in their translation performance.
The key elements of the research include:
-
Experiment Design: The researchers fine-tuned several state-of-the-art LLMs, such as GPT-3 and T5, on diverse translation datasets covering various language pairs. This fine-tuning process helps the models learn the intricacies of translation, going beyond their initial language understanding capabilities.
-
Architecture: The authors explored different fine-tuning strategies, including prompt-based approaches and more traditional fine-tuning techniques. They also investigated the impact of various architectural choices, such as the use of translation-specific layers or attention mechanisms.
-
Insights: The results demonstrate that the proposed paradigm leads to substantial gains in translation quality across a range of language pairs and domains, as measured by standard evaluation metrics. The authors also provide insights into the translation behaviors of the fine-tuned LLMs and discuss the potential for further improvements through techniques like post-editing guidance or multilingual training.
Critical Analysis
The paper presents a compelling approach to boosting the translation capabilities of large language models, but it also acknowledges several caveats and limitations.
One potential concern is the reliance on existing translation datasets, which may not capture the full breadth of linguistic diversity and real-world translation scenarios. The authors suggest that further research is needed to explore the generalization of the fine-tuned models to less common language pairs or specialized domains.
Additionally, the paper does not delve deeply into the computational and resource requirements of the fine-tuning process. Scaling this approach to a wide range of LLMs and language pairs may pose challenges in terms of training time and computational resources, which could limit its practical adoption.
While the results are promising, the paper also highlights the need for continued research and innovation in areas like post-editing guidance and multilingual training to further advance the state-of-the-art in machine translation.
Conclusion
This paper presents a novel paradigm for boosting the translation capabilities of large language models. By leveraging existing translation datasets and techniques, the researchers demonstrate significant improvements in the models' ability to translate between languages accurately and fluently.
The authors argue that this paradigm shift has the potential to shape the future of machine translation, paving the way for the development of even more advanced multilingual AI systems. While the approach has its limitations, the insights and techniques described in this paper, along with related research on eliciting translation ability, paradigm shifts in machine translation, and teaching LLMs new languages, represent an important step forward in the field of natural language processing and machine translation.
Related Papers
💬
Eliciting the Translation Ability of Large Language Models via Multilingual Finetuning with Translation Instructions
Jiahuan Li, Hao Zhou, Shujian Huang, Shanbo Cheng, Jiajun Chen
0
0
Large-scale Pretrained Language Models (LLMs), such as ChatGPT and GPT4, have shown strong abilities in multilingual translations, without being explicitly trained on parallel corpora. It is interesting how the LLMs obtain their ability to carry out translation instructions for different languages. In this paper, we present a detailed analysis by finetuning a multilingual pretrained language model, XGLM-7B, to perform multilingual translation following given instructions. Firstly, we show that multilingual LLMs have stronger translation abilities than previously demonstrated. For a certain language, the performance depends on its similarity to English and the amount of data used in the pretraining phase. Secondly, we find that LLMs' ability to carry out translation instructions relies on the understanding of translation instructions and the alignment among different languages. With multilingual finetuning, LLMs could learn to perform the translation task well even for those language pairs unseen during the instruction tuning phase.
4/16/2024
💬
A Paradigm Shift: The Future of Machine Translation Lies with Large Language Models
Chenyang Lyu, Zefeng Du, Jitao Xu, Yitao Duan, Minghao Wu, Teresa Lynn, Alham Fikri Aji, Derek F. Wong, Siyou Liu, Longyue Wang
0
0
Machine Translation (MT) has greatly advanced over the years due to the developments in deep neural networks. However, the emergence of Large Language Models (LLMs) like GPT-4 and ChatGPT is introducing a new phase in the MT domain. In this context, we believe that the future of MT is intricately tied to the capabilities of LLMs. These models not only offer vast linguistic understandings but also bring innovative methodologies, such as prompt-based techniques, that have the potential to further elevate MT. In this paper, we provide an overview of the significant enhancements in MT that are influenced by LLMs and advocate for their pivotal role in upcoming MT research and implementations. We highlight several new MT directions, emphasizing the benefits of LLMs in scenarios such as Long-Document Translation, Stylized Translation, and Interactive Translation. Additionally, we address the important concern of privacy in LLM-driven MT and suggest essential privacy-preserving strategies. By showcasing practical instances, we aim to demonstrate the advantages that LLMs offer, particularly in tasks like translating extended documents. We conclude by emphasizing the critical role of LLMs in guiding the future evolution of MT and offer a roadmap for future exploration in the sector.
4/3/2024

SambaLingo: Teaching Large Language Models New Languages
Zoltan Csaki, Bo Li, Jonathan Li, Qiantong Xu, Pian Pawakapan, Leon Zhang, Yun Du, Hengyu Zhao, Changran Hu, Urmish Thakker
0
0
Despite the widespread availability of LLMs, there remains a substantial gap in their capabilities and availability across diverse languages. One approach to address these issues has been to take an existing pre-trained LLM and continue to train it on new languages. While prior works have experimented with language adaptation, many questions around best practices and methodology have not been covered. In this paper, we present a comprehensive investigation into the adaptation of LLMs to new languages. Our study covers the key components in this process, including vocabulary extension, direct preference optimization and the data scarcity problem for human alignment in low-resource languages. We scale these experiments across 9 languages and 2 parameter scales (7B and 70B). We compare our models against Llama 2, Aya-101, XGLM, BLOOM and existing language experts, outperforming all prior published baselines. Additionally, all evaluation code and checkpoints are made public to facilitate future research.
4/10/2024
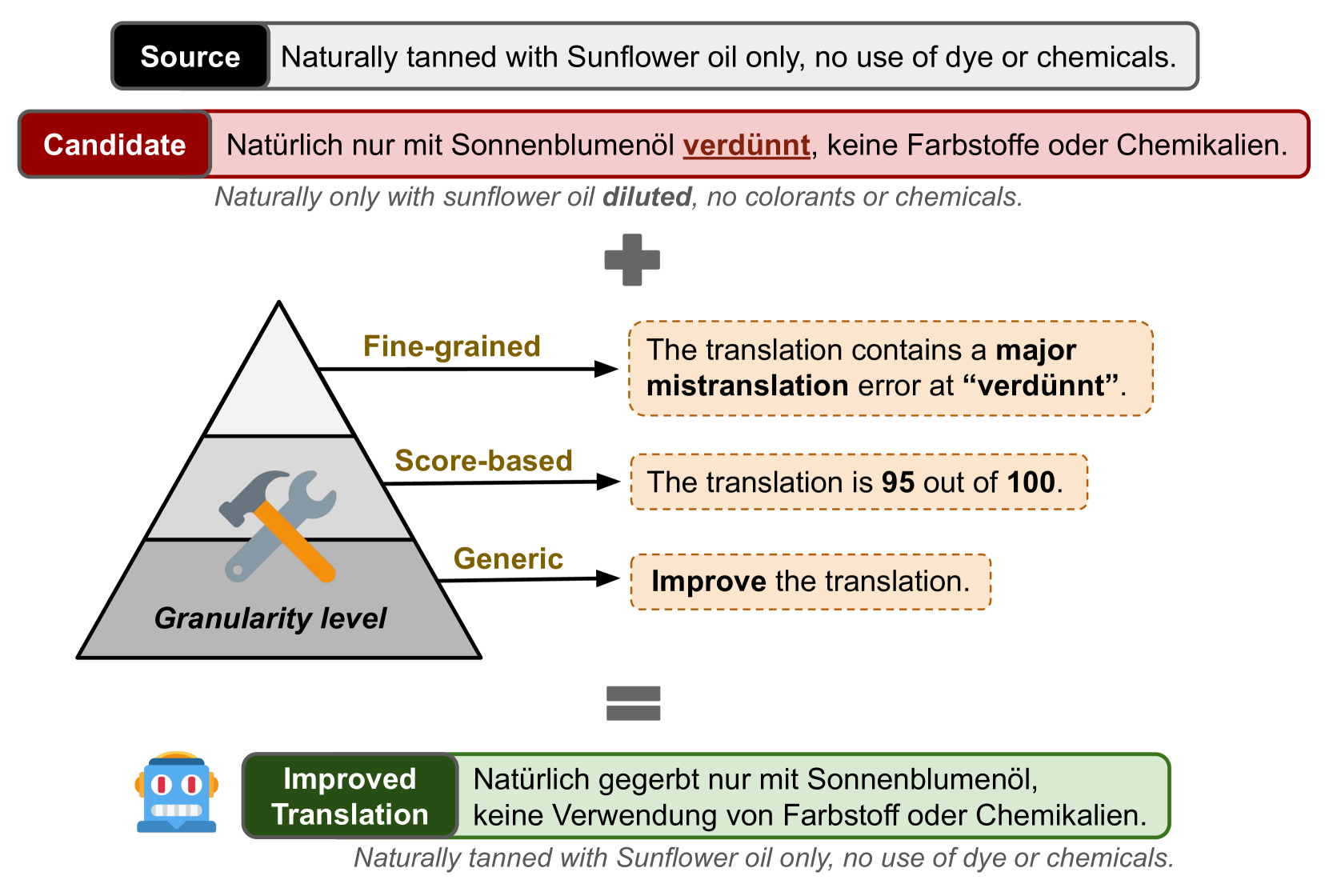
Guiding Large Language Models to Post-Edit Machine Translation with Error Annotations
Dayeon Ki, Marine Carpuat
0
0
Machine Translation (MT) remains one of the last NLP tasks where large language models (LLMs) have not yet replaced dedicated supervised systems. This work exploits the complementary strengths of LLMs and supervised MT by guiding LLMs to automatically post-edit MT with external feedback on its quality, derived from Multidimensional Quality Metric (MQM) annotations. Working with LLaMA-2 models, we consider prompting strategies varying the nature of feedback provided and then fine-tune the LLM to improve its ability to exploit the provided guidance. Through experiments on Chinese-English, English-German, and English-Russian MQM data, we demonstrate that prompting LLMs to post-edit MT improves TER, BLEU and COMET scores, although the benefits of fine-grained feedback are not clear. Fine-tuning helps integrate fine-grained feedback more effectively and further improves translation quality based on both automatic and human evaluation.
4/12/2024