CIMRL: Combining IMitiation and Reinforcement Learning for Safe Autonomous Driving
2406.08878
0
0

Abstract
Modern approaches to autonomous driving rely heavily on learned components trained with large amounts of human driving data via imitation learning. However, these methods require large amounts of expensive data collection and even then face challenges with safely handling long-tail scenarios and compounding errors over time. At the same time, pure Reinforcement Learning (RL) methods can fail to learn performant policies in sparse, constrained, and challenging-to-define reward settings like driving. Both of these challenges make deploying purely cloned policies in safety critical applications like autonomous vehicles challenging. In this paper we propose Combining IMitation and Reinforcement Learning (CIMRL) approach - a framework that enables training driving policies in simulation through leveraging imitative motion priors and safety constraints. CIMRL does not require extensive reward specification and improves on the closed loop behavior of pure cloning methods. By combining RL and imitation, we demonstrate that our method achieves state-of-the-art results in closed loop simulation driving benchmarks.
Create account to get full access
Overview
- This paper presents CIMRL, a framework that combines imitation learning and reinforcement learning for safe autonomous driving.
- The approach aims to leverage the strengths of both learning techniques to achieve more robust and reliable self-driving capabilities.
- The authors conduct experiments in simulation and on real-world road scenarios to evaluate the performance of CIMRL.
Plain English Explanation
The paper discusses a new approach called CIMRL that blends two machine learning techniques - imitation learning and reinforcement learning - to help self-driving cars navigate roads safely.
Imitation learning works by having the car mimic the actions of human drivers, learning from their expertise. Reinforcement learning, on the other hand, involves the car experimenting and learning through trial-and-error to figure out the best actions to take.
CIMRL tries to combine the benefits of both approaches. By having the car first learn from human drivers through imitation, it can develop a strong foundation of safe driving skills. Then, the reinforcement learning component allows the car to further refine and optimize its driving behavior through continued practice and feedback.
The researchers test CIMRL in simulated environments as well as on real roads to see how well it performs compared to other autonomous driving systems. The goal is to create self-driving cars that can navigate roads reliably and safely, even in complex or unexpected situations.
Technical Explanation
The paper introduces CIMRL, a framework that integrates imitation learning and reinforcement learning for autonomous driving. Imitation learning allows the vehicle to mimic the actions of expert human drivers, while reinforcement learning enables it to further optimize its behavior through trial-and-error.
The authors design a neural network architecture that takes in sensory inputs like camera images and vehicle state, and outputs steering and throttle commands. During the imitation learning phase, the network is trained to match the actions of human drivers in a dataset of driving demonstrations.
Then, the reinforcement learning component is introduced, where the vehicle explores the environment and receives rewards/penalties based on metrics like distance traveled, safety, and smoothness of driving. This allows the vehicle to refine its policy and learn more optimal behaviors beyond just imitating human drivers.
The paper evaluates CIMRL in both simulated and real-world driving scenarios. The results show that CIMRL outperforms baselines that use only imitation or reinforcement learning alone, demonstrating the benefits of the combined approach.
Critical Analysis
The paper provides a compelling argument for leveraging both imitation and reinforcement learning to create more capable autonomous driving systems. By seeding the vehicle's initial policy with human expertise and then fine-tuning it through self-exploration, CIMRL seems to offer a promising path forward.
However, the paper does not deeply address potential limitations or safety concerns that may arise from this approach. For example, if the initial imitation learning phase leads to suboptimal behaviors, the reinforcement learning component may have difficulty overcoming those biases.
Additionally, the evaluation is primarily conducted in simulation, which may not fully capture the complexity and unpredictability of real-world driving scenarios. More extensive real-world testing would be needed to validate the practical effectiveness and safety of CIMRL.
Further research could also explore ways to seamlessly integrate the imitation and reinforcement learning components, potentially through methods like multi-task learning or hierarchical policies, to create a more coherent and effective autonomous driving system.
Conclusion
The CIMRL framework presented in this paper offers a novel approach to autonomous driving, combining the strengths of imitation and reinforcement learning. By leveraging human expertise and then allowing the vehicle to refine its behaviors through self-exploration, the authors demonstrate promising results in both simulated and real-world environments.
While the paper highlights the potential benefits of this combined learning strategy, it also raises important questions about safety, robustness, and the limitations of the current evaluation. Continued research and development in this area could lead to significant advancements in the field of autonomous driving, paving the way for safer and more reliable self-driving vehicles.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
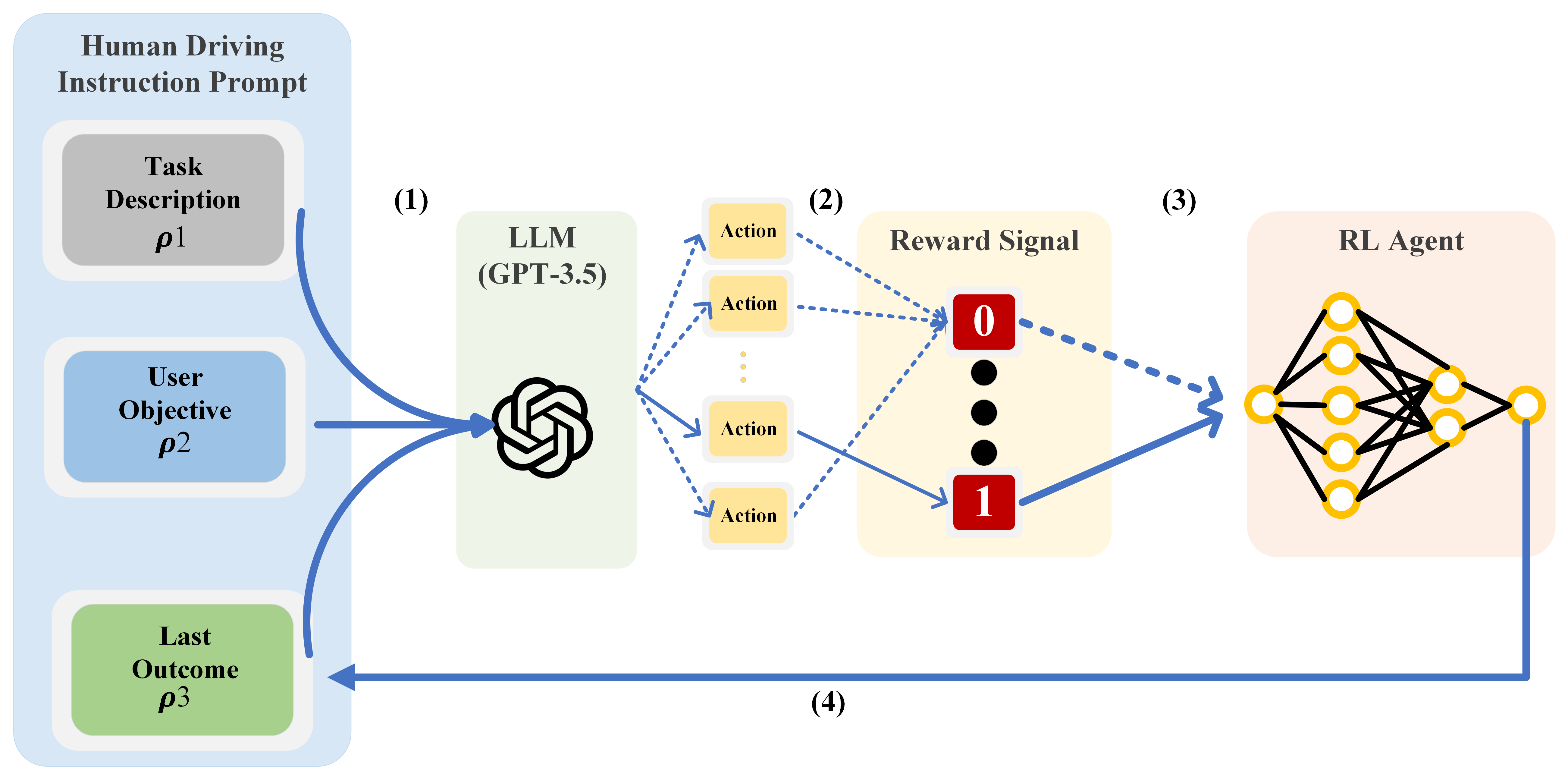
In-context Learning for Automated Driving Scenarios
Ziqi Zhou, Jingyue Zhang, Jingyuan Zhang, Boyue Wang, Tianyu Shi, Alaa Khamis
0
0
One of the key challenges in current Reinforcement Learning (RL)-based Automated Driving (AD) agents is achieving flexible, precise, and human-like behavior cost-effectively. This paper introduces an innovative approach utilizing Large Language Models (LLMs) to intuitively and effectively optimize RL reward functions in a human-centric way. We developed a framework where instructions and dynamic environment descriptions are input into the LLM. The LLM then utilizes this information to assist in generating rewards, thereby steering the behavior of RL agents towards patterns that more closely resemble human driving. The experimental results demonstrate that this approach not only makes RL agents more anthropomorphic but also reaches better performance. Additionally, various strategies for reward-proxy and reward-shaping are investigated, revealing the significant impact of prompt design on shaping an AD vehicle's behavior. These findings offer a promising direction for the development of more advanced and human-like automated driving systems. Our experimental data and source code can be found here.
5/8/2024
🏅
Simulation-based reinforcement learning for real-world autonomous driving
B{l}a.zej Osi'nski, Adam Jakubowski, Piotr Mi{l}o's, Pawe{l} Zik{e}cina, Christopher Galias, Silviu Homoceanu, Henryk Michalewski
0
0
We use reinforcement learning in simulation to obtain a driving system controlling a full-size real-world vehicle. The driving policy takes RGB images from a single camera and their semantic segmentation as input. We use mostly synthetic data, with labelled real-world data appearing only in the training of the segmentation network. Using reinforcement learning in simulation and synthetic data is motivated by lowering costs and engineering effort. In real-world experiments we confirm that we achieved successful sim-to-real policy transfer. Based on the extensive evaluation, we analyze how design decisions about perception, control, and training impact the real-world performance.
4/4/2024

HAIM-DRL: Enhanced Human-in-the-loop Reinforcement Learning for Safe and Efficient Autonomous Driving
Zilin Huang, Zihao Sheng, Chengyuan Ma, Sikai Chen
0
0
Despite significant progress in autonomous vehicles (AVs), the development of driving policies that ensure both the safety of AVs and traffic flow efficiency has not yet been fully explored. In this paper, we propose an enhanced human-in-the-loop reinforcement learning method, termed the Human as AI mentor-based deep reinforcement learning (HAIM-DRL) framework, which facilitates safe and efficient autonomous driving in mixed traffic platoon. Drawing inspiration from the human learning process, we first introduce an innovative learning paradigm that effectively injects human intelligence into AI, termed Human as AI mentor (HAIM). In this paradigm, the human expert serves as a mentor to the AI agent. While allowing the agent to sufficiently explore uncertain environments, the human expert can take control in dangerous situations and demonstrate correct actions to avoid potential accidents. On the other hand, the agent could be guided to minimize traffic flow disturbance, thereby optimizing traffic flow efficiency. In detail, HAIM-DRL leverages data collected from free exploration and partial human demonstrations as its two training sources. Remarkably, we circumvent the intricate process of manually designing reward functions; instead, we directly derive proxy state-action values from partial human demonstrations to guide the agents' policy learning. Additionally, we employ a minimal intervention technique to reduce the human mentor's cognitive load. Comparative results show that HAIM-DRL outperforms traditional methods in driving safety, sampling efficiency, mitigation of traffic flow disturbance, and generalizability to unseen traffic scenarios. The code and demo videos for this paper can be accessed at: https://zilin-huang.github.io/HAIM-DRL-website/
6/18/2024
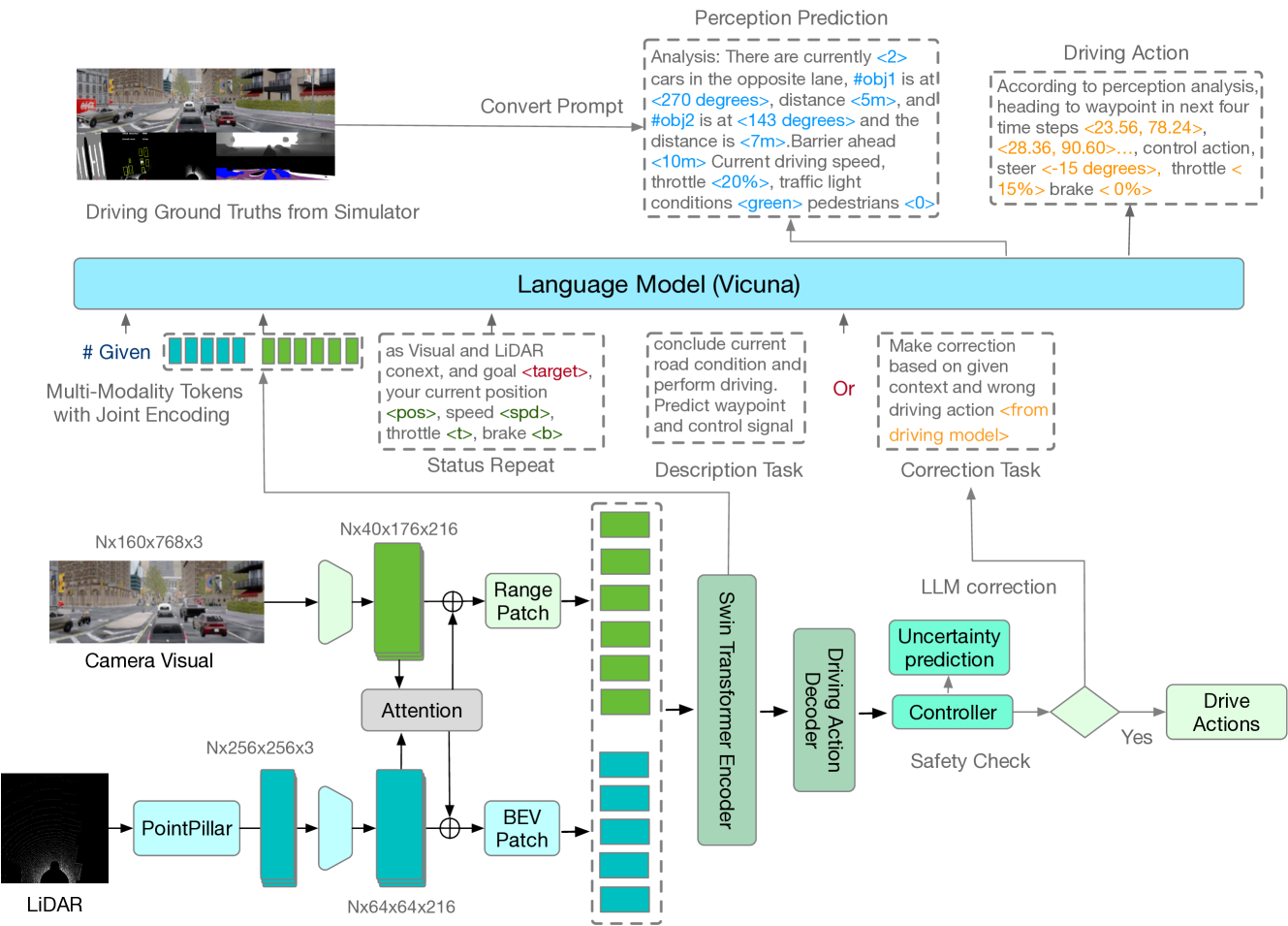
Prompting Multi-Modal Tokens to Enhance End-to-End Autonomous Driving Imitation Learning with LLMs
Yiqun Duan, Qiang Zhang, Renjing Xu
0
0
The utilization of Large Language Models (LLMs) within the realm of reinforcement learning, particularly as planners, has garnered a significant degree of attention in recent scholarly literature. However, a substantial proportion of existing research predominantly focuses on planning models for robotics that transmute the outputs derived from perception models into linguistic forms, thus adopting a `pure-language' strategy. In this research, we propose a hybrid End-to-End learning framework for autonomous driving by combining basic driving imitation learning with LLMs based on multi-modality prompt tokens. Instead of simply converting perception results from the separated train model into pure language input, our novelty lies in two aspects. 1) The end-to-end integration of visual and LiDAR sensory input into learnable multi-modality tokens, thereby intrinsically alleviating description bias by separated pre-trained perception models. 2) Instead of directly letting LLMs drive, this paper explores a hybrid setting of letting LLMs help the driving model correct mistakes and complicated scenarios. The results of our experiments suggest that the proposed methodology can attain driving scores of 49.21%, coupled with an impressive route completion rate of 91.34% in the offline evaluation conducted via CARLA. These performance metrics are comparable to the most advanced driving models.
4/9/2024