ClassDiffusion: More Aligned Personalization Tuning with Explicit Class Guidance
2405.17532
0
0

Abstract
Recent text-to-image customization works have been proven successful in generating images of given concepts by fine-tuning the diffusion models on a few examples. However, these methods tend to overfit the concepts, resulting in failure to create the concept under multiple conditions (e.g. headphone is missing when generating a dog wearing a headphone'). Interestingly, we notice that the base model before fine-tuning exhibits the capability to compose the base concept with other elements (e.g. a dog wearing a headphone) implying that the compositional ability only disappears after personalization tuning. Inspired by this observation, we present ClassDiffusion, a simple technique that leverages a semantic preservation loss to explicitly regulate the concept space when learning the new concept. Despite its simplicity, this helps avoid semantic drift when fine-tuning on the target concepts. Extensive qualitative and quantitative experiments demonstrate that the use of semantic preservation loss effectively improves the compositional abilities of the fine-tune models. In response to the ineffective evaluation of CLIP-T metrics, we introduce BLIP2-T metric, a more equitable and effective evaluation metric for this particular domain. We also provide in-depth empirical study and theoretical analysis to better understand the role of the proposed loss. Lastly, we also extend our ClassDiffusion to personalized video generation, demonstrating its flexibility.
Create account to get full access
Overview
- This paper introduces "ClassDiffusion," a novel approach to personalization tuning in diffusion models that provides explicit class guidance.
- The key idea is to incorporate class-specific information during the diffusion process, which can help align the generated content more closely with the user's preferences and needs.
- The paper demonstrates the effectiveness of ClassDiffusion on various tasks, including customized text-to-image generation and personalized image segmentation and retrieval.
Plain English Explanation
Diffusion models are a type of AI system that can generate new images, text, or other content by learning from existing data. However, these models can sometimes struggle to generate content that is truly personalized to an individual user's preferences and needs.
The ClassDiffusion approach aims to address this challenge by incorporating explicit class-specific information into the diffusion process. This means that the model is not only learning from the general dataset, but is also incorporating guidance about the specific types of content the user is interested in.
For example, if a user is interested in architecture, the ClassDiffusion model could use information about different architectural styles and features to guide the generation of new architectural images or designs. This can help ensure that the generated content is more closely aligned with the user's interests and preferences.
Similarly, in tasks like image segmentation and retrieval, the ClassDiffusion approach can use class-specific information to help the model better understand the user's needs and provide more personalized results.
Overall, the key innovation of ClassDiffusion is its ability to harness explicit class guidance during the diffusion process, which can lead to more aligned and personalized content generation. This could have important applications in areas like creative design, e-commerce, and personalized assistants.
Technical Explanation
The ClassDiffusion approach builds on the success of diffusion models in generating diverse and high-quality content. However, it recognizes that standard diffusion models may struggle to generate content that is truly personalized to the user's preferences and needs.
To address this, the ClassDiffusion approach incorporates class-specific information into the diffusion process. Specifically, the model takes in not only the input data (e.g., an image or text prompt), but also a class label that indicates the type of content the user is interested in (e.g., architecture, nature, or portraits).
This class information is then used to guide the diffusion process, ensuring that the generated content aligns more closely with the user's preferences. The authors demonstrate the effectiveness of this approach on a variety of tasks, including customized text-to-image generation, personalized image segmentation, and personalized image retrieval.
Importantly, the ClassDiffusion approach can be applied to both conditional and unconditional diffusion models, making it a versatile technique that can be integrated into a wide range of diffusion-based systems.
Critical Analysis
The ClassDiffusion approach is a promising step towards more personalized and aligned content generation using diffusion models. By incorporating explicit class guidance, the model is able to better tailor the generated content to the user's preferences and needs.
However, the paper does not address the potential limitations of this approach. For example, it's unclear how well the ClassDiffusion model would handle cases where the user's preferences are more complex or nuanced, or where their interests span multiple classes.
Additionally, the paper does not discuss the potential ethical implications of more personalized content generation, such as the risk of filter bubbles or the amplification of biases. These are important considerations that should be addressed as the field of personalized AI continues to evolve.
Despite these caveats, the ClassDiffusion approach represents an important advancement in the field of diffusion-based content generation, and its potential applications in areas like creative design, e-commerce, and personalized assistants are significant. As the research in this area continues to progress, it will be important for the community to carefully consider both the benefits and the potential risks of these technologies.
Conclusion
The ClassDiffusion paper introduces a novel approach to personalization tuning in diffusion models that incorporates explicit class guidance. By leveraging class-specific information during the diffusion process, the model is able to generate content that is more closely aligned with the user's preferences and needs.
The authors demonstrate the effectiveness of this approach on a variety of tasks, including customized text-to-image generation, personalized image segmentation, and personalized image retrieval. This represents a significant advancement in the field of diffusion-based content generation, with important implications for a wide range of applications.
As the research in this area continues to progress, it will be important for the community to carefully consider both the benefits and the potential risks of these personalized AI technologies, and to work towards developing them in a responsible and ethical manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
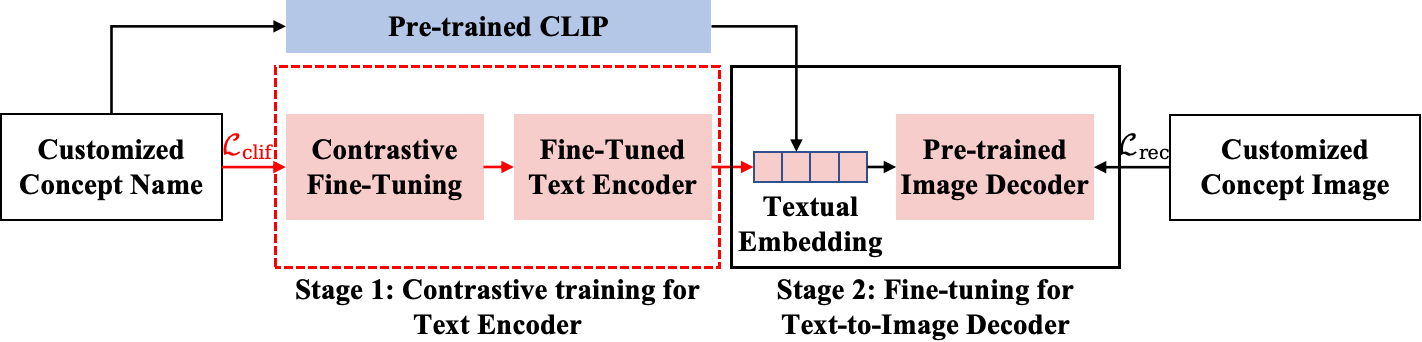
Non-confusing Generation of Customized Concepts in Diffusion Models
Wang Lin, Jingyuan Chen, Jiaxin Shi, Yichen Zhu, Chen Liang, Junzhong Miao, Tao Jin, Zhou Zhao, Fei Wu, Shuicheng Yan, Hanwang Zhang
0
0
We tackle the common challenge of inter-concept visual confusion in compositional concept generation using text-guided diffusion models (TGDMs). It becomes even more pronounced in the generation of customized concepts, due to the scarcity of user-provided concept visual examples. By revisiting the two major stages leading to the success of TGDMs -- 1) contrastive image-language pre-training (CLIP) for text encoder that encodes visual semantics, and 2) training TGDM that decodes the textual embeddings into pixels -- we point that existing customized generation methods only focus on fine-tuning the second stage while overlooking the first one. To this end, we propose a simple yet effective solution called CLIF: contrastive image-language fine-tuning. Specifically, given a few samples of customized concepts, we obtain non-confusing textual embeddings of a concept by fine-tuning CLIP via contrasting a concept and the over-segmented visual regions of other concepts. Experimental results demonstrate the effectiveness of CLIF in preventing the confusion of multi-customized concept generation.
5/14/2024

Investigating and Defending Shortcut Learning in Personalized Diffusion Models
Yixin Liu, Ruoxi Chen, Lichao Sun
0
0
Personalized diffusion models have gained popularity for adapting pre-trained text-to-image models to generate images of specific topics with only a few images. However, recent studies find that these models are vulnerable to minor adversarial perturbation, and the fine-tuning performance is largely degraded on corrupted datasets. Such characteristics are further exploited to craft protective perturbation on sensitive images like portraits that prevent unauthorized generation. In response, diffusion-based purification methods have been proposed to remove these perturbations and retain generation performance. However, existing works lack detailed analysis of the fundamental shortcut learning vulnerability of personalized diffusion models and also turn to over-purifying the images cause information loss. In this paper, we take a closer look at the fine-tuning process of personalized diffusion models through the lens of shortcut learning and propose a hypothesis that could explain the underlying manipulation mechanisms of existing perturbation methods. Specifically, we find that the perturbed images are greatly shifted from their original paired prompt in the CLIP-based latent space. As a result, training with this mismatched image-prompt pair creates a construction that causes the models to dump their out-of-distribution noisy patterns to the identifier, thus causing serious performance degradation. Based on this observation, we propose a systematic approach to retain the training performance with purification that realigns the latent image and its semantic meaning and also introduces contrastive learning with a negative token to decouple the learning of wanted clean identity and the unwanted noisy pattern, that shows strong potential capacity against further adaptive perturbation.
6/28/2024

Using diffusion model as constraint: Empower Image Restoration Network Training with Diffusion Model
Jiangtong Tan, Feng Zhao
0
0
Image restoration has made marvelous progress with the advent of deep learning. Previous methods usually rely on designing powerful network architecture to elevate performance, however, the natural visual effect of the restored results is limited by color and texture distortions. Besides the visual perceptual quality, the semantic perception recovery is an important but often overlooked perspective of restored image, which is crucial for the deployment in high-level tasks. In this paper, we propose a new perspective to resort these issues by introducing a naturalness-oriented and semantic-aware optimization mechanism, dubbed DiffLoss. Specifically, inspired by the powerful distribution coverage capability of the diffusion model for natural image generation, we exploit the Markov chain sampling property of diffusion model and project the restored results of existing networks into the sampling space. Besides, we reveal that the bottleneck feature of diffusion models, also dubbed h-space feature, is a natural high-level semantic space. We delve into this property and propose a semantic-aware loss to further unlock its potential of semantic perception recovery, which paves the way to connect image restoration task and downstream high-level recognition task. With these two strategies, the DiffLoss can endow existing restoration methods with both more natural and semantic-aware results. We verify the effectiveness of our method on substantial common image restoration tasks and benchmarks. Code will be available at https://github.com/JosephTiTan/DiffLoss.
6/28/2024
🛸
Subject-Diffusion:Open Domain Personalized Text-to-Image Generation without Test-time Fine-tuning
Jian Ma, Junhao Liang, Chen Chen, Haonan Lu
0
0
Recent progress in personalized image generation using diffusion models has been significant. However, development in the area of open-domain and non-fine-tuning personalized image generation is proceeding rather slowly. In this paper, we propose Subject-Diffusion, a novel open-domain personalized image generation model that, in addition to not requiring test-time fine-tuning, also only requires a single reference image to support personalized generation of single- or multi-subject in any domain. Firstly, we construct an automatic data labeling tool and use the LAION-Aesthetics dataset to construct a large-scale dataset consisting of 76M images and their corresponding subject detection bounding boxes, segmentation masks and text descriptions. Secondly, we design a new unified framework that combines text and image semantics by incorporating coarse location and fine-grained reference image control to maximize subject fidelity and generalization. Furthermore, we also adopt an attention control mechanism to support multi-subject generation. Extensive qualitative and quantitative results demonstrate that our method outperforms other SOTA frameworks in single, multiple, and human customized image generation. Please refer to our href{https://oppo-mente-lab.github.io/subject_diffusion/}{project page}
5/21/2024