Non-confusing Generation of Customized Concepts in Diffusion Models
2405.06914
0
0
Abstract
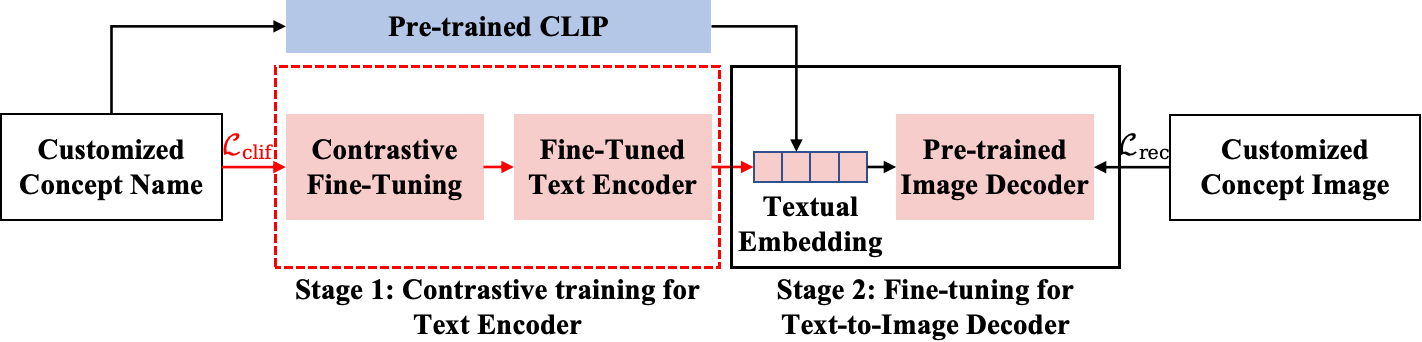
We tackle the common challenge of inter-concept visual confusion in compositional concept generation using text-guided diffusion models (TGDMs). It becomes even more pronounced in the generation of customized concepts, due to the scarcity of user-provided concept visual examples. By revisiting the two major stages leading to the success of TGDMs -- 1) contrastive image-language pre-training (CLIP) for text encoder that encodes visual semantics, and 2) training TGDM that decodes the textual embeddings into pixels -- we point that existing customized generation methods only focus on fine-tuning the second stage while overlooking the first one. To this end, we propose a simple yet effective solution called CLIF: contrastive image-language fine-tuning. Specifically, given a few samples of customized concepts, we obtain non-confusing textual embeddings of a concept by fine-tuning CLIP via contrasting a concept and the over-segmented visual regions of other concepts. Experimental results demonstrate the effectiveness of CLIF in preventing the confusion of multi-customized concept generation.
Create account to get full access
Overview
- This paper proposes a novel approach to generate customized concepts in diffusion models, which are a type of generative AI model.
- The key idea is to enable the model to generate images that incorporate specific concepts, while avoiding confusion with unrelated concepts.
- The authors introduce several techniques to achieve this, including Concept Weaver, Infusion, and Attention Calibration.
Plain English Explanation
Diffusion models are a powerful type of AI that can generate images from scratch. However, it can be challenging to control the specific concepts that are included in the generated images. This paper addresses this by introducing new techniques to enable the model to incorporate desired concepts, while avoiding unrelated ones that could be confusing.
The key idea is to give the model more fine-grained control over the concepts it uses when generating an image. For example, if you want an image of a dog wearing a hat, the model should be able to accurately incorporate both the dog and the hat concepts, without accidentally including irrelevant things like a tree or a car.
The authors propose several methods to achieve this. Concept Weaver allows the model to blend multiple concepts together, like dog and hat. Infusion prevents the model from straying too far from the desired concepts. And Attention Calibration helps the model focus on the right aspects of the image.
By using these techniques, the model can generate images that clearly incorporate the specific concepts you want, without getting confused and including unrelated things. This could be useful for all kinds of AI-powered image generation applications, from creative tools to educational resources.
Technical Explanation
The authors first identify the key challenge of concept confusion in diffusion models - the tendency for the model to generate images that incorporate unrelated concepts, in addition to the desired ones. To address this, they propose several novel techniques:
-
Concept Weaver: This module allows the model to seamlessly blend multiple concepts (e.g. dog and hat) when generating an image. It learns to fuse the representations of different concepts in a way that enables their coherent integration.
-
Infusion: The authors introduce an "infusion" mechanism that prevents the diffusion process from straying too far from the desired concepts. This helps ensure the generated images remain faithful to the target concepts.
-
Attention Calibration: This method calibrates the attention mechanism in the diffusion model to focus on the relevant aspects of the image for each concept, rather than spreading attention too broadly.
The authors evaluate their techniques on various benchmarks and find that they significantly improve the model's ability to generate images that incorporate the target concepts, while avoiding concept confusion. They also demonstrate the flexibility of their approach by applying it to personalized text-to-image generation.
Critical Analysis
The authors provide a comprehensive set of techniques to address the important challenge of concept confusion in diffusion models. By giving the model more fine-grained control over the concepts it uses, they enable the generation of images that clearly reflect the desired semantic content.
However, the paper does not delve into potential limitations or drawbacks of the proposed methods. For example, it's unclear how the techniques scale to a larger number of concepts, or how they handle more complex, abstract, or subjective concepts. Additionally, the computational overhead of the added modules is not discussed.
Furthermore, the paper does not explore the broader implications of this work, such as its potential impact on the responsible development of generative AI systems. Concepts like erasing concepts and improving concept alignment could be relevant to consider.
Overall, the techniques proposed in this paper represent a valuable contribution to the field of diffusion models, but further research is needed to fully understand their limitations and broader implications.
Conclusion
This paper introduces a novel approach to generating customized concepts in diffusion models, addressing the challenge of concept confusion. By incorporating techniques like Concept Weaver, Infusion, and Attention Calibration, the authors enable diffusion models to generate images that clearly reflect the target concepts, without incorporating unrelated content.
These advancements could have significant implications for a wide range of AI-powered image generation applications, from creative tools to educational resources. By giving users more control over the specific concepts included in the generated images, the proposed methods could lead to more meaningful and useful outputs.
However, the broader implications of this work, as well as its potential limitations, warrant further exploration. As the field of generative AI continues to evolve, it will be crucial to consider the responsible development and deployment of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

ClassDiffusion: More Aligned Personalization Tuning with Explicit Class Guidance
Jiannan Huang, Jun Hao Liew, Hanshu Yan, Yuyang Yin, Yao Zhao, Yunchao Wei
0
0
Recent text-to-image customization works have been proven successful in generating images of given concepts by fine-tuning the diffusion models on a few examples. However, these methods tend to overfit the concepts, resulting in failure to create the concept under multiple conditions (e.g. headphone is missing when generating a dog wearing a headphone'). Interestingly, we notice that the base model before fine-tuning exhibits the capability to compose the base concept with other elements (e.g. a dog wearing a headphone) implying that the compositional ability only disappears after personalization tuning. Inspired by this observation, we present ClassDiffusion, a simple technique that leverages a semantic preservation loss to explicitly regulate the concept space when learning the new concept. Despite its simplicity, this helps avoid semantic drift when fine-tuning on the target concepts. Extensive qualitative and quantitative experiments demonstrate that the use of semantic preservation loss effectively improves the compositional abilities of the fine-tune models. In response to the ineffective evaluation of CLIP-T metrics, we introduce BLIP2-T metric, a more equitable and effective evaluation metric for this particular domain. We also provide in-depth empirical study and theoretical analysis to better understand the role of the proposed loss. Lastly, we also extend our ClassDiffusion to personalized video generation, demonstrating its flexibility.
5/29/2024
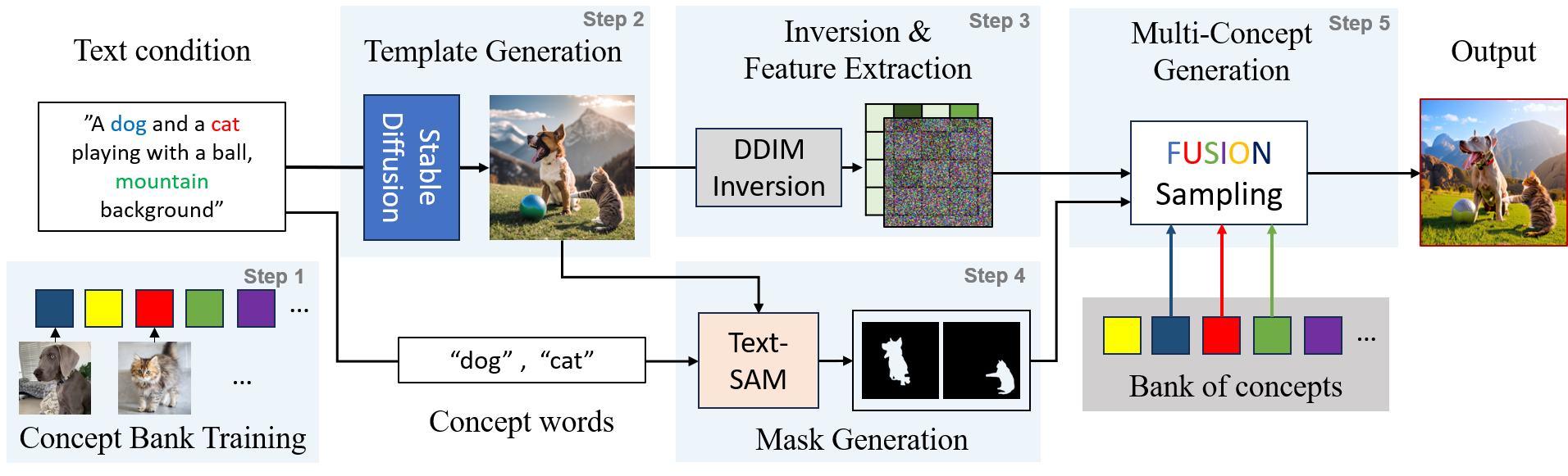
Concept Weaver: Enabling Multi-Concept Fusion in Text-to-Image Models
Gihyun Kwon, Simon Jenni, Dingzeyu Li, Joon-Young Lee, Jong Chul Ye, Fabian Caba Heilbron
0
0
While there has been significant progress in customizing text-to-image generation models, generating images that combine multiple personalized concepts remains challenging. In this work, we introduce Concept Weaver, a method for composing customized text-to-image diffusion models at inference time. Specifically, the method breaks the process into two steps: creating a template image aligned with the semantics of input prompts, and then personalizing the template using a concept fusion strategy. The fusion strategy incorporates the appearance of the target concepts into the template image while retaining its structural details. The results indicate that our method can generate multiple custom concepts with higher identity fidelity compared to alternative approaches. Furthermore, the method is shown to seamlessly handle more than two concepts and closely follow the semantic meaning of the input prompt without blending appearances across different subjects.
4/8/2024

Infusion: Preventing Customized Text-to-Image Diffusion from Overfitting
Weili Zeng, Yichao Yan, Qi Zhu, Zhuo Chen, Pengzhi Chu, Weiming Zhao, Xiaokang Yang
0
0
Text-to-image (T2I) customization aims to create images that embody specific visual concepts delineated in textual descriptions. However, existing works still face a main challenge, concept overfitting. To tackle this challenge, we first analyze overfitting, categorizing it into concept-agnostic overfitting, which undermines non-customized concept knowledge, and concept-specific overfitting, which is confined to customize on limited modalities, i.e, backgrounds, layouts, styles. To evaluate the overfitting degree, we further introduce two metrics, i.e, Latent Fisher divergence and Wasserstein metric to measure the distribution changes of non-customized and customized concept respectively. Drawing from the analysis, we propose Infusion, a T2I customization method that enables the learning of target concepts to avoid being constrained by limited training modalities, while preserving non-customized knowledge. Remarkably, Infusion achieves this feat with remarkable efficiency, requiring a mere 11KB of trained parameters. Extensive experiments also demonstrate that our approach outperforms state-of-the-art methods in both single and multi-concept customized generation.
4/23/2024
🖼️
FreeCustom: Tuning-Free Customized Image Generation for Multi-Concept Composition
Ganggui Ding, Canyu Zhao, Wen Wang, Zhen Yang, Zide Liu, Hao Chen, Chunhua Shen
0
0
Benefiting from large-scale pre-trained text-to-image (T2I) generative models, impressive progress has been achieved in customized image generation, which aims to generate user-specified concepts. Existing approaches have extensively focused on single-concept customization and still encounter challenges when it comes to complex scenarios that involve combining multiple concepts. These approaches often require retraining/fine-tuning using a few images, leading to time-consuming training processes and impeding their swift implementation. Furthermore, the reliance on multiple images to represent a singular concept increases the difficulty of customization. To this end, we propose FreeCustom, a novel tuning-free method to generate customized images of multi-concept composition based on reference concepts, using only one image per concept as input. Specifically, we introduce a new multi-reference self-attention (MRSA) mechanism and a weighted mask strategy that enables the generated image to access and focus more on the reference concepts. In addition, MRSA leverages our key finding that input concepts are better preserved when providing images with context interactions. Experiments show that our method's produced images are consistent with the given concepts and better aligned with the input text. Our method outperforms or performs on par with other training-based methods in terms of multi-concept composition and single-concept customization, but is simpler. Codes can be found at https://github.com/aim-uofa/FreeCustom.
5/24/2024