CliBench: Multifaceted Evaluation of Large Language Models in Clinical Decisions on Diagnoses, Procedures, Lab Tests Orders and Prescriptions
2406.09923
0
0
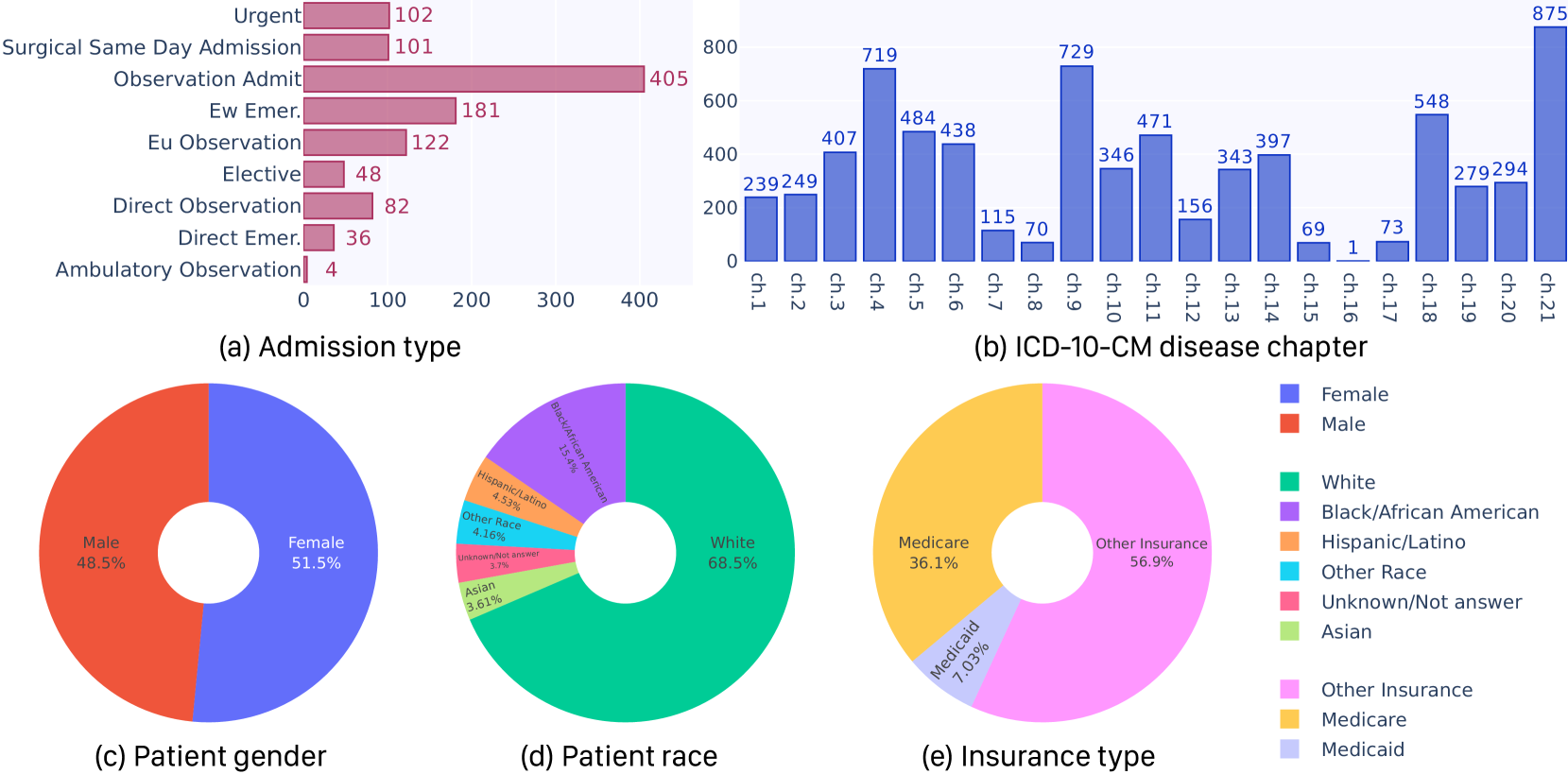
Abstract
The integration of Artificial Intelligence (AI), especially Large Language Models (LLMs), into the clinical diagnosis process offers significant potential to improve the efficiency and accessibility of medical care. While LLMs have shown some promise in the medical domain, their application in clinical diagnosis remains underexplored, especially in real-world clinical practice, where highly sophisticated, patient-specific decisions need to be made. Current evaluations of LLMs in this field are often narrow in scope, focusing on specific diseases or specialties and employing simplified diagnostic tasks. To bridge this gap, we introduce CliBench, a novel benchmark developed from the MIMIC IV dataset, offering a comprehensive and realistic assessment of LLMs' capabilities in clinical diagnosis. This benchmark not only covers diagnoses from a diverse range of medical cases across various specialties but also incorporates tasks of clinical significance: treatment procedure identification, lab test ordering and medication prescriptions. Supported by structured output ontologies, CliBench enables a precise and multi-granular evaluation, offering an in-depth understanding of LLM's capability on diverse clinical tasks of desired granularity. We conduct a zero-shot evaluation of leading LLMs to assess their proficiency in clinical decision-making. Our preliminary results shed light on the potential and limitations of current LLMs in clinical settings, providing valuable insights for future advancements in LLM-powered healthcare.
Create account to get full access
Overview
- This paper introduces CliBench, a comprehensive benchmark for evaluating the performance of large language models (LLMs) in making clinical decisions on diagnoses, procedures, lab tests, and prescriptions.
- The benchmark covers a wide range of clinical tasks, reflecting the diverse needs of healthcare professionals.
- The authors provide a detailed analysis of the performance of several state-of-the-art LLMs on CliBench, offering insights into the strengths and limitations of these models in the healthcare domain.
Plain English Explanation
The paper presents a new tool called CliBench that can be used to test how well large language models (LLMs) - a type of artificial intelligence that can understand and generate human-like text - perform on a variety of healthcare-related tasks. These tasks include making diagnoses, recommending medical procedures, ordering lab tests, and prescribing treatments.
The researchers behind CliBench recognized that as LLMs become more advanced, they could potentially be used to assist healthcare providers in making clinical decisions. However, it's important to carefully evaluate how well these models perform on realistic medical tasks before deploying them in real-world settings. CliBench aims to provide a comprehensive and rigorous way to assess the capabilities of LLMs in the healthcare domain.
The paper shows the results of testing several state-of-the-art LLMs on CliBench. This analysis provides insights into the strengths and limitations of these models when it comes to making healthcare-related decisions. For example, the models may excel at certain tasks, like generating summaries of medical records, but struggle with others, like accurately diagnosing rare conditions.
By providing this detailed evaluation, the researchers hope to inform the development of more capable and reliable LLMs for healthcare applications. They also aim to contribute to the growing body of research on using large language models in medical settings.
Technical Explanation
The paper introduces CliBench, a multifaceted benchmark designed to comprehensively evaluate the performance of large language models (LLMs) in clinical decision-making tasks. CliBench covers a wide range of healthcare-related tasks, including diagnosing conditions, recommending medical procedures, ordering lab tests, and prescribing treatments.
The authors conducted extensive experiments to assess the capabilities of several state-of-the-art LLMs on the CliBench tasks. They used a variety of evaluation metrics to measure the models' performance, such as accuracy, F1 score, and normalized discounted cumulative gain (NDCG).
The results of the experiments revealed both the strengths and limitations of the tested LLMs in the healthcare domain. For example, the models performed well on certain tasks, such as summarizing medical records, but struggled with others, like accurately diagnosing rare conditions.
The authors also discussed the potential implications of their findings for the development of more capable and reliable LLMs for healthcare applications. They highlighted the need for further research to address the identified limitations and to explore the use of LLMs in more diverse and complex medical scenarios.
Critical Analysis
The CliBench benchmark presented in this paper is a valuable contribution to the field of healthcare AI, as it provides a comprehensive and rigorous way to evaluate the performance of large language models in making clinical decisions. The wide range of tasks covered by the benchmark reflects the diverse needs of healthcare professionals, and the authors' use of multiple evaluation metrics ensures a thorough assessment of the models' capabilities.
However, the paper also acknowledges several limitations and areas for further research. For instance, the authors note that the dataset used to train the LLMs may not fully capture the complexity and diversity of real-world medical cases, which could impact the models' performance on the CliBench tasks. Additionally, the paper does not explore the potential biases or fairness issues that may arise when deploying LLMs in healthcare settings, which is an important consideration for the responsible development of these technologies.
Further research is also needed to explore the integration of LLMs with other medical AI systems, such as those used for image analysis or patient monitoring, to develop more comprehensive and integrated clinical decision support tools. The authors also suggest the need to investigate the interpretability and explainability of LLM-based clinical decisions, as this is crucial for building trust and ensuring the accountability of these systems in healthcare settings.
Overall, the CliBench benchmark and the insights provided in this paper represent a valuable contribution to the ongoing efforts to harness the power of large language models in the healthcare domain. However, the authors have rightly identified several areas for further research and development to ensure the safe and effective deployment of these technologies in real-world medical settings.
Conclusion
The CliBench benchmark introduced in this paper provides a comprehensive and rigorous framework for evaluating the performance of large language models (LLMs) in making clinical decisions. The detailed analysis of several state-of-the-art LLMs on a wide range of healthcare-related tasks offers valuable insights into the strengths and limitations of these models in the medical domain.
The findings of this research have important implications for the development of more capable and reliable LLMs for healthcare applications. By highlighting the areas where these models excel and the areas where they struggle, the authors have laid the groundwork for further research and innovation in this rapidly evolving field.
As the use of AI in healthcare continues to grow, it is crucial that these technologies are thoroughly evaluated and held to the highest standards of performance and safety. The CliBench benchmark and the insights provided in this paper represent an important step forward in this direction, and the authors' call for ongoing research and development in this area is well-justified and timely.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Large Language Models in Healthcare: A Comprehensive Benchmark
Andrew Liu, Hongjian Zhou, Yining Hua, Omid Rohanian, Anshul Thakur, Lei Clifton, David A. Clifton
0
0
The adoption of large language models (LLMs) to assist clinicians has attracted remarkable attention. Existing works mainly adopt the close-ended question-answering (QA) task with answer options for evaluation. However, many clinical decisions involve answering open-ended questions without pre-set options. To better understand LLMs in the clinic, we construct a benchmark ClinicBench. We first collect eleven existing datasets covering diverse clinical language generation, understanding, and reasoning tasks. Furthermore, we construct six novel datasets and complex clinical tasks that are close to real-world practice, i.e., referral QA, treatment recommendation, hospitalization (long document) summarization, patient education, pharmacology QA and drug interaction for emerging drugs. We conduct an extensive evaluation of twenty-two LLMs under both zero-shot and few-shot settings. Finally, we invite medical experts to evaluate the clinical usefulness of LLMs.
6/27/2024
💬
Evaluating large language models in medical applications: a survey
Xiaolan Chen, Jiayang Xiang, Shanfu Lu, Yexin Liu, Mingguang He, Danli Shi
0
0
Large language models (LLMs) have emerged as powerful tools with transformative potential across numerous domains, including healthcare and medicine. In the medical domain, LLMs hold promise for tasks ranging from clinical decision support to patient education. However, evaluating the performance of LLMs in medical contexts presents unique challenges due to the complex and critical nature of medical information. This paper provides a comprehensive overview of the landscape of medical LLM evaluation, synthesizing insights from existing studies and highlighting evaluation data sources, task scenarios, and evaluation methods. Additionally, it identifies key challenges and opportunities in medical LLM evaluation, emphasizing the need for continued research and innovation to ensure the responsible integration of LLMs into clinical practice.
5/14/2024

CLUE: A Clinical Language Understanding Evaluation for LLMs
Amin Dada, Marie Bauer, Amanda Butler Contreras, Osman Alperen Korac{s}, Constantin Marc Seibold, Kaleb E Smith, Jens Kleesiek
0
0
Large Language Models (LLMs) are expected to significantly contribute to patient care, diagnostics, and administrative processes. Emerging biomedical LLMs aim to address healthcare-specific challenges, including privacy demands and computational constraints. Assessing the models' suitability for this sensitive application area is of the utmost importance. However, evaluation has primarily been limited to non-clinical tasks, which do not reflect the complexity of practical clinical applications. To fill this gap, we present the Clinical Language Understanding Evaluation (CLUE), a benchmark tailored to evaluate LLMs on clinical tasks. CLUE includes six tasks to test the practical applicability of LLMs in complex healthcare settings. Our evaluation includes a total of $25$ LLMs. In contrast to previous evaluations, CLUE shows a decrease in performance for nine out of twelve biomedical models. Our benchmark represents a step towards a standardized approach to evaluating and developing LLMs in healthcare to align future model development with the real-world needs of clinical application. We open-source all evaluation scripts and datasets for future research at https://github.com/TIO-IKIM/CLUE.
6/26/2024
🤖
New!AI Hospital: Benchmarking Large Language Models in a Multi-agent Medical Interaction Simulator
Zhihao Fan, Jialong Tang, Wei Chen, Siyuan Wang, Zhongyu Wei, Jun Xi, Fei Huang, Jingren Zhou
0
0
Artificial intelligence has significantly advanced healthcare, particularly through large language models (LLMs) that excel in medical question answering benchmarks. However, their real-world clinical application remains limited due to the complexities of doctor-patient interactions. To address this, we introduce textbf{AI Hospital}, a multi-agent framework simulating dynamic medical interactions between emph{Doctor} as player and NPCs including emph{Patient}, emph{Examiner}, emph{Chief Physician}. This setup allows for realistic assessments of LLMs in clinical scenarios. We develop the Multi-View Medical Evaluation (MVME) benchmark, utilizing high-quality Chinese medical records and NPCs to evaluate LLMs' performance in symptom collection, examination recommendations, and diagnoses. Additionally, a dispute resolution collaborative mechanism is proposed to enhance diagnostic accuracy through iterative discussions. Despite improvements, current LLMs exhibit significant performance gaps in multi-turn interactions compared to one-step approaches. Our findings highlight the need for further research to bridge these gaps and improve LLMs' clinical diagnostic capabilities. Our data, code, and experimental results are all open-sourced at url{https://github.com/LibertFan/AI_Hospital}.
6/28/2024