A Closer Look into Mixture-of-Experts in Large Language Models
2406.18219
0
0

Abstract
Mixture-of-experts (MoE) is gaining increasing attention due to its unique properties and remarkable performance, especially for language tasks. By sparsely activating a subset of parameters for each token, MoE architecture could increase the model size without sacrificing computational efficiency, achieving a better trade-off between performance and training costs. However, the underlying mechanism of MoE still lacks further exploration, and its modularization degree remains questionable. In this paper, we make an initial attempt to understand the inner workings of MoE-based large language models. Concretely, we comprehensively study the parametric and behavioral features of three recent MoE-based models and reveal some intriguing observations, including (1) Neurons act like fine-grained experts. (2) The router of MoE usually selects experts with larger output norms. (3) The expert diversity increases as the layer increases, while the last layer is an outlier. Based on the observations, we also provide suggestions for a broad spectrum of MoE practitioners, such as router design and expert allocation. We hope this work could shed light on future research on the MoE framework and other modular architectures. Code is available at https://github.com/kamanphoebe/Look-into-MoEs.
Create account to get full access
Overview
- This paper provides a closer look at the Mixture-of-Experts (MoE) approach used in large language models (LLMs).
- MoE is a technique that allows LLMs to leverage specialized submodules, called "experts," to handle different types of inputs or tasks more effectively.
- The paper explores various aspects of MoE in LLMs, including its benefits, limitations, and potential enhancements.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text, answer questions, and perform a variety of language-related tasks. However, these models can be computationally expensive and may not always perform optimally on specific types of inputs or tasks.
The Mixture-of-Experts (MoE) approach is a technique that aims to address these limitations by allowing the LLM to leverage specialized submodules, called "experts," to handle different types of inputs or tasks more effectively. Instead of relying on a single, monolithic model, the MoE approach divides the model into multiple experts, each of which is trained to excel at a particular task or type of input.
When the LLM receives an input, a "router" module decides which expert or combination of experts should be used to process that input. This allows the LLM to draw upon the strengths of different experts, potentially leading to better performance and efficiency.
The paper explores various aspects of MoE in LLMs, including its benefits, limitations, and potential enhancements. For example, the paper discusses how MoE can improve the model's overall performance, reduce its computational requirements, and enable more targeted capabilities. However, the paper also acknowledges challenges, such as the complexity of training and managing multiple experts, and the potential for suboptimal routing decisions.
The paper also highlights some recent advancements in MoE for LLMs, such as LocMoE, Toward Inference-Optimal Mixture of Experts, HyperMoE, LLaMA-MoE, and LocMoE: Enhanced Router. These approaches aim to further improve the efficiency, flexibility, and performance of MoE in LLMs.
Technical Explanation
The paper provides a detailed technical analysis of the Mixture-of-Experts (MoE) approach used in large language models (LLMs). MoE is a technique that allows LLMs to leverage specialized submodules, called "experts," to handle different types of inputs or tasks more effectively.
The key elements of the paper's technical explanation include:
- Architecture: The MoE architecture typically consists of a "router" module that decides which expert or combination of experts should be used to process a given input, and the experts themselves, which are specialized submodules trained to excel at particular tasks or types of inputs.
- Training: The training process for MoE-based LLMs involves jointly optimizing the router and the experts to ensure effective routing decisions and expert performance.
- Insights: The paper explores various insights into the benefits, limitations, and potential enhancements of the MoE approach, such as improved performance, reduced computational requirements, and the ability to enable more targeted capabilities.
The paper also discusses several recent advancements in MoE for LLMs, including LocMoE, Toward Inference-Optimal Mixture of Experts, HyperMoE, LLaMA-MoE, and LocMoE: Enhanced Router. These approaches aim to further improve the efficiency, flexibility, and performance of MoE in LLMs.
Critical Analysis
The paper provides a thorough and insightful analysis of the Mixture-of-Experts (MoE) approach in large language models (LLMs). However, the authors also acknowledge several caveats and limitations of the MoE approach:
- Complexity: The management and training of multiple expert submodules can be significantly more complex than training a single, monolithic model. This complexity may introduce additional challenges, such as ensuring consistent performance and coherence across the experts.
- Routing Decisions: The effectiveness of the MoE approach heavily depends on the quality of the routing decisions made by the router module. Suboptimal routing decisions could lead to subpar performance or inefficient resource utilization.
- Interpretability: The modular nature of MoE-based LLMs may make it more challenging to interpret and understand the decision-making process, potentially limiting the transparency and explainability of the model's outputs.
The paper also suggests areas for further research, such as exploring more advanced routing mechanisms, developing techniques to better coordinate the experts, and investigating ways to improve the overall efficiency and scalability of MoE-based LLMs.
While the paper provides a comprehensive overview of the MoE approach, it would be valuable for future research to further address these limitations and explore ways to enhance the robustness and applicability of MoE in real-world LLM deployments.
Conclusion
This paper provides a closer look at the Mixture-of-Experts (MoE) approach used in large language models (LLMs). MoE is a technique that allows LLMs to leverage specialized submodules, called "experts," to handle different types of inputs or tasks more effectively.
The paper explores the benefits of the MoE approach, such as improved performance, reduced computational requirements, and the ability to enable more targeted capabilities. However, it also discusses the challenges, including the complexity of training and managing multiple experts, as well as the potential for suboptimal routing decisions.
The paper highlights several recent advancements in MoE for LLMs, such as LocMoE, Toward Inference-Optimal Mixture of Experts, HyperMoE, LLaMA-MoE, and LocMoE: Enhanced Router, which aim to further improve the efficiency, flexibility, and performance of MoE in LLMs.
Overall, the paper provides a comprehensive and insightful analysis of the MoE approach, highlighting its potential benefits and limitations, and suggesting areas for future research. As the field of LLMs continues to evolve, the insights and advancements discussed in this paper may play a crucial role in driving the development of more efficient, flexible, and capable language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
LocMoE: A Low-Overhead MoE for Large Language Model Training
Jing Li, Zhijie Sun, Xuan He, Li Zeng, Yi Lin, Entong Li, Binfan Zheng, Rongqian Zhao, Xin Chen
0
0
The Mixtures-of-Experts (MoE) model is a widespread distributed and integrated learning method for large language models (LLM), which is favored due to its ability to sparsify and expand models efficiently. However, the performance of MoE is limited by load imbalance and high latency of All-to-All communication, along with relatively redundant computation owing to large expert capacity. Load imbalance may result from existing routing policies that consistently tend to select certain experts. The frequent inter-node communication in the All-to-All procedure also significantly prolongs the training time. To alleviate the above performance problems, we propose a novel routing strategy that combines load balance and locality by converting partial inter-node communication to that of intra-node. Notably, we elucidate that there is a minimum threshold for expert capacity, calculated through the maximal angular deviation between the gating weights of the experts and the assigned tokens. We port these modifications on the PanGu-Sigma model based on the MindSpore framework with multi-level routing and conduct experiments on Ascend clusters. The experiment results demonstrate that the proposed LocMoE reduces training time per epoch by 12.68% to 22.24% compared to classical routers, such as hash router and switch router, without impacting the model accuracy.
5/24/2024
Toward Inference-optimal Mixture-of-Expert Large Language Models
Longfei Yun, Yonghao Zhuang, Yao Fu, Eric P Xing, Hao Zhang
0
0
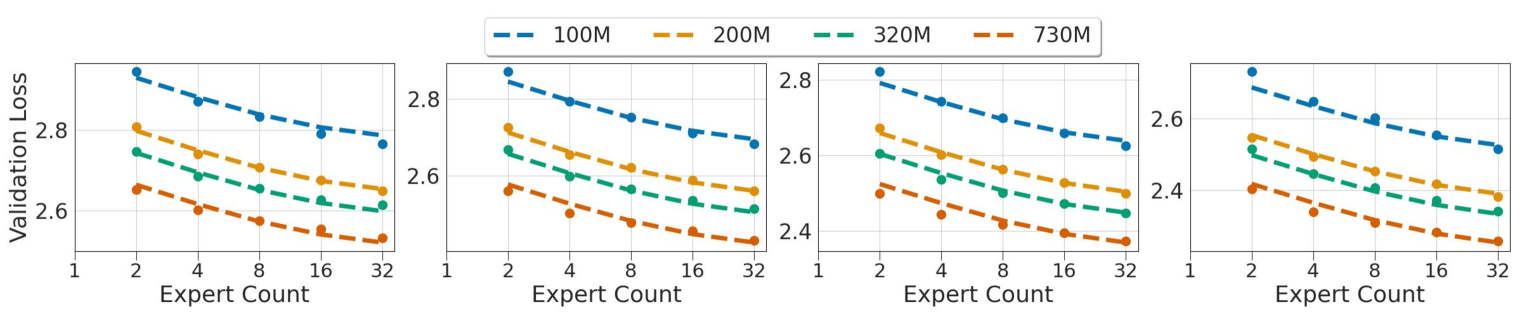
Mixture-of-Expert (MoE) based large language models (LLMs), such as the recent Mixtral and DeepSeek-MoE, have shown great promise in scaling model size without suffering from the quadratic growth of training cost of dense transformers. Like dense models, training MoEs requires answering the same question: given a training budget, what is the optimal allocation on the model size and number of tokens? We study the scaling law of MoE-based LLMs regarding the relations between the model performance, model size, dataset size, and the expert degree. Echoing previous research studying MoE in different contexts, we observe the diminishing return of increasing the number of experts, but this seems to suggest we should scale the number of experts until saturation, as the training cost would remain constant, which is problematic during inference time. We propose to amend the scaling law of MoE by introducing inference efficiency as another metric besides the validation loss. We find that MoEs with a few (4/8) experts are the most serving efficient solution under the same performance, but costs 2.5-3.5x more in training. On the other hand, training a (16/32) expert MoE much smaller (70-85%) than the loss-optimal solution, but with a larger training dataset is a promising setup under a training budget.
4/4/2024
HyperMoE: Towards Better Mixture of Experts via Transferring Among Experts
Hao Zhao, Zihan Qiu, Huijia Wu, Zili Wang, Zhaofeng He, Jie Fu
0
0
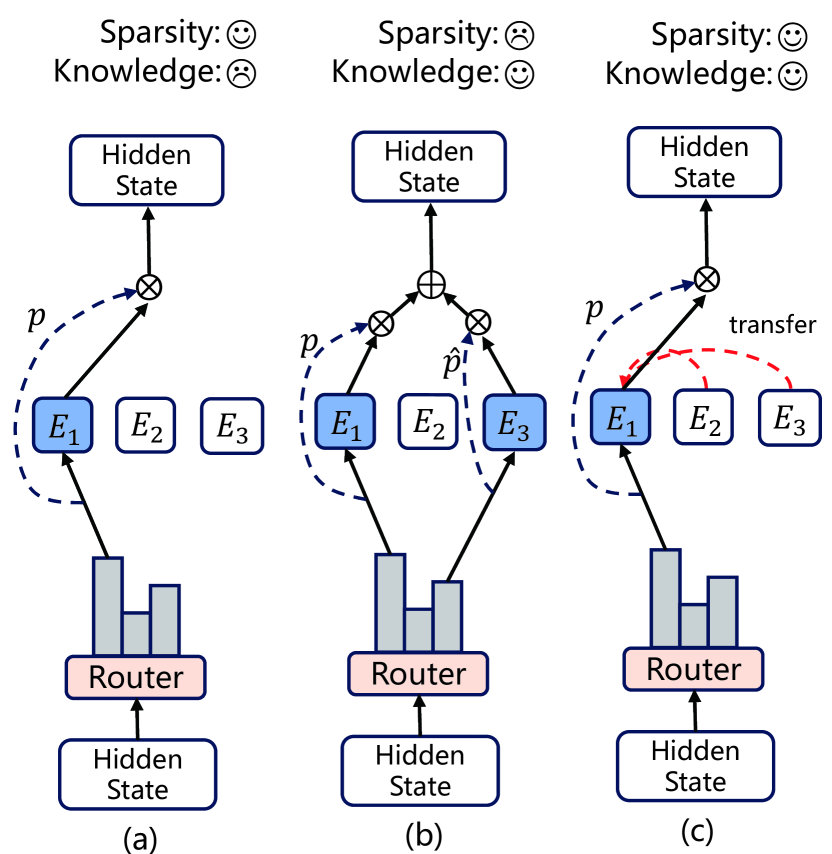
The Mixture of Experts (MoE) for language models has been proven effective in augmenting the capacity of models by dynamically routing each input token to a specific subset of experts for processing. Despite the success, most existing methods face a challenge for balance between sparsity and the availability of expert knowledge: enhancing performance through increased use of expert knowledge often results in diminishing sparsity during expert selection. To mitigate this contradiction, we propose HyperMoE, a novel MoE framework built upon Hypernetworks. This framework integrates the computational processes of MoE with the concept of knowledge transferring in multi-task learning. Specific modules generated based on the information of unselected experts serve as supplementary information, which allows the knowledge of experts not selected to be used while maintaining selection sparsity. Our comprehensive empirical evaluations across multiple datasets and backbones establish that HyperMoE significantly outperforms existing MoE methods under identical conditions concerning the number of experts.
5/22/2024

LLaMA-MoE: Building Mixture-of-Experts from LLaMA with Continual Pre-training
Tong Zhu, Xiaoye Qu, Daize Dong, Jiacheng Ruan, Jingqi Tong, Conghui He, Yu Cheng
0
0
Mixture-of-Experts (MoE) has gained increasing popularity as a promising framework for scaling up large language models (LLMs). However, training MoE from scratch in a large-scale setting still suffers from data-hungry and instability problems. Motivated by this limit, we investigate building MoE models from existing dense large language models. Specifically, based on the well-known LLaMA-2 7B model, we obtain an MoE model by: (1) Expert Construction, which partitions the parameters of original Feed-Forward Networks (FFNs) into multiple experts; (2) Continual Pre-training, which further trains the transformed MoE model and additional gate networks. In this paper, we comprehensively explore different methods for expert construction and various data sampling strategies for continual pre-training. After these stages, our LLaMA-MoE models could maintain language abilities and route the input tokens to specific experts with part of the parameters activated. Empirically, by training 200B tokens, LLaMA-MoE-3.5B models significantly outperform dense models that contain similar activation parameters. The source codes and models are available at https://github.com/pjlab-sys4nlp/llama-moe .
6/26/2024