LLaMA-MoE: Building Mixture-of-Experts from LLaMA with Continual Pre-training
2406.16554
0
0

Abstract
Mixture-of-Experts (MoE) has gained increasing popularity as a promising framework for scaling up large language models (LLMs). However, training MoE from scratch in a large-scale setting still suffers from data-hungry and instability problems. Motivated by this limit, we investigate building MoE models from existing dense large language models. Specifically, based on the well-known LLaMA-2 7B model, we obtain an MoE model by: (1) Expert Construction, which partitions the parameters of original Feed-Forward Networks (FFNs) into multiple experts; (2) Continual Pre-training, which further trains the transformed MoE model and additional gate networks. In this paper, we comprehensively explore different methods for expert construction and various data sampling strategies for continual pre-training. After these stages, our LLaMA-MoE models could maintain language abilities and route the input tokens to specific experts with part of the parameters activated. Empirically, by training 200B tokens, LLaMA-MoE-3.5B models significantly outperform dense models that contain similar activation parameters. The source codes and models are available at https://github.com/pjlab-sys4nlp/llama-moe .
Create account to get full access
Overview
- This paper presents LLaMA-MoE, a method for building a Mixture-of-Experts (MoE) model from the LLaMA language model through continual pre-training.
- The authors aim to scale up the capabilities of LLaMA by leveraging the benefits of the MoE architecture, which allows for more efficient and specialized language modeling.
- The research explores how to effectively adapt the LLaMA model to the MoE setup, and the impacts of this approach on model performance and efficiency.
Plain English Explanation
The paper is about a new way to improve the capabilities of a popular language model called LLaMA. The researchers wanted to make LLaMA even more powerful and efficient by using a special architecture called Mixture-of-Experts (MoE).
In a normal language model, there's a single neural network that tries to handle all the different tasks and knowledge that the model needs. With a MoE model, the work is split across multiple "expert" networks, each of which specializes in a different area. This allows the model to be more efficient and perform better on a wider range of tasks.
The key challenge the researchers tackled was how to take the existing LLaMA model and adapt it to work with the MoE architecture. They developed a method called "continual pre-training" to do this, which involves further training the model on new data to help it learn the MoE setup.
The end result is LLaMA-MoE, a more powerful and versatile language model that can take on a broader range of tasks and do so more efficiently than the original LLaMA. This could lead to significant improvements in areas like natural language processing, text generation, and question answering.
Technical Explanation
The paper introduces LLaMA-MoE, a method for building a Mixture-of-Experts (MoE) model from the LLaMA language model through continual pre-training. The goal is to scale up the capabilities of LLaMA by leveraging the benefits of the MoE architecture, which allows for more efficient and specialized language modeling.
The key technical contributions are:
- Adapting LLaMA to MoE: The authors develop a method to effectively adapt the LLaMA model to the MoE setup, overcoming challenges like parameter sharing and expert assignment.
- Continual Pre-training: The researchers use a continual pre-training approach to train the LLaMA-MoE model, building on the original LLaMA checkpoint and further fine-tuning it on new data.
- Evaluating Performance and Efficiency: The paper presents extensive experiments comparing the performance and efficiency of LLaMA-MoE to the baseline LLaMA model across a range of language tasks.
The results show that LLaMA-MoE can significantly outperform the original LLaMA model in terms of both task performance and computational efficiency, highlighting the potential of this approach for scaling up large language models.
Critical Analysis
The paper provides a compelling approach for improving the capabilities of the LLaMA language model through the use of a Mixture-of-Experts (MoE) architecture. The authors' focus on continual pre-training to adapt the LLaMA model to the MoE setup is a clever and practical solution to the technical challenges involved.
However, the paper does acknowledge some limitations and areas for further research. For example, the authors note that the continual pre-training process can be computationally expensive and may require careful hyperparameter tuning. Additionally, the paper does not explore the impact of the MoE approach on the model's robustness, interpretability, or potential biases.
Uni-MoE and LocMoE are two other recent papers that have explored MoE architectures for large language models, and it would be interesting to see how LLaMA-MoE compares to these alternative approaches.
Additionally, the paper does not address potential ethical concerns around the use of ever-more powerful language models, such as the risk of generating harmful or biased content. Future research in this area should consider these important societal implications.
Overall, the LLaMA-MoE approach represents an exciting step forward in scaling up the capabilities of large language models, but there is still significant work to be done to fully understand the implications and ensure these models are developed and deployed responsibly.
Conclusion
The LLaMA-MoE paper presents a novel method for building a Mixture-of-Experts (MoE) model from the LLaMA language model through continual pre-training. The key innovation is the researchers' approach to effectively adapting the LLaMA model to the MoE setup, which allows for significant improvements in both performance and efficiency compared to the original LLaMA model.
This work has important implications for the field of large language models, as it demonstrates the potential benefits of using specialized expert networks to scale up model capabilities. The LLaMA-MoE model could lead to advancements in a wide range of natural language processing tasks, from text generation to question answering.
However, the research also highlights the need for further exploration of the ethical considerations surrounding the development and deployment of ever-more powerful language models. As these models become more capable, it is crucial that we consider their potential for misuse and work to ensure they are used in a responsible and beneficial manner.
Overall, the LLaMA-MoE paper represents an important contribution to the ongoing effort to push the boundaries of what is possible with large language models. By combining cutting-edge techniques like MoE with careful model adaptation, the researchers have paved the way for exciting new advancements in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Closer Look into Mixture-of-Experts in Large Language Models
Ka Man Lo, Zeyu Huang, Zihan Qiu, Zili Wang, Jie Fu
0
0
Mixture-of-experts (MoE) is gaining increasing attention due to its unique properties and remarkable performance, especially for language tasks. By sparsely activating a subset of parameters for each token, MoE architecture could increase the model size without sacrificing computational efficiency, achieving a better trade-off between performance and training costs. However, the underlying mechanism of MoE still lacks further exploration, and its modularization degree remains questionable. In this paper, we make an initial attempt to understand the inner workings of MoE-based large language models. Concretely, we comprehensively study the parametric and behavioral features of three recent MoE-based models and reveal some intriguing observations, including (1) Neurons act like fine-grained experts. (2) The router of MoE usually selects experts with larger output norms. (3) The expert diversity increases as the layer increases, while the last layer is an outlier. Based on the observations, we also provide suggestions for a broad spectrum of MoE practitioners, such as router design and expert allocation. We hope this work could shed light on future research on the MoE framework and other modular architectures. Code is available at https://github.com/kamanphoebe/Look-into-MoEs.
6/27/2024
Toward Inference-optimal Mixture-of-Expert Large Language Models
Longfei Yun, Yonghao Zhuang, Yao Fu, Eric P Xing, Hao Zhang
0
0
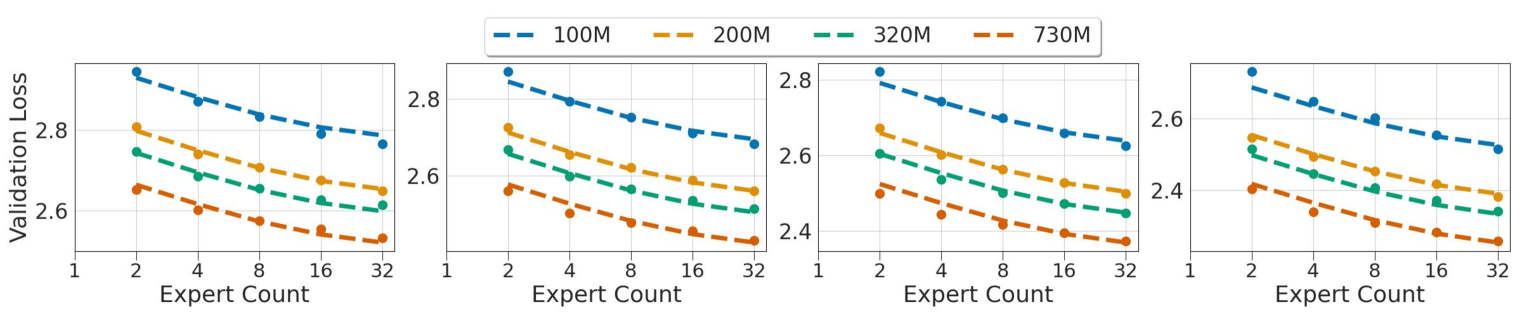
Mixture-of-Expert (MoE) based large language models (LLMs), such as the recent Mixtral and DeepSeek-MoE, have shown great promise in scaling model size without suffering from the quadratic growth of training cost of dense transformers. Like dense models, training MoEs requires answering the same question: given a training budget, what is the optimal allocation on the model size and number of tokens? We study the scaling law of MoE-based LLMs regarding the relations between the model performance, model size, dataset size, and the expert degree. Echoing previous research studying MoE in different contexts, we observe the diminishing return of increasing the number of experts, but this seems to suggest we should scale the number of experts until saturation, as the training cost would remain constant, which is problematic during inference time. We propose to amend the scaling law of MoE by introducing inference efficiency as another metric besides the validation loss. We find that MoEs with a few (4/8) experts are the most serving efficient solution under the same performance, but costs 2.5-3.5x more in training. On the other hand, training a (16/32) expert MoE much smaller (70-85%) than the loss-optimal solution, but with a larger training dataset is a promising setup under a training budget.
4/4/2024
Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts
Yunxin Li, Shenyuan Jiang, Baotian Hu, Longyue Wang, Wanqi Zhong, Wenhan Luo, Lin Ma, Min Zhang
0
0
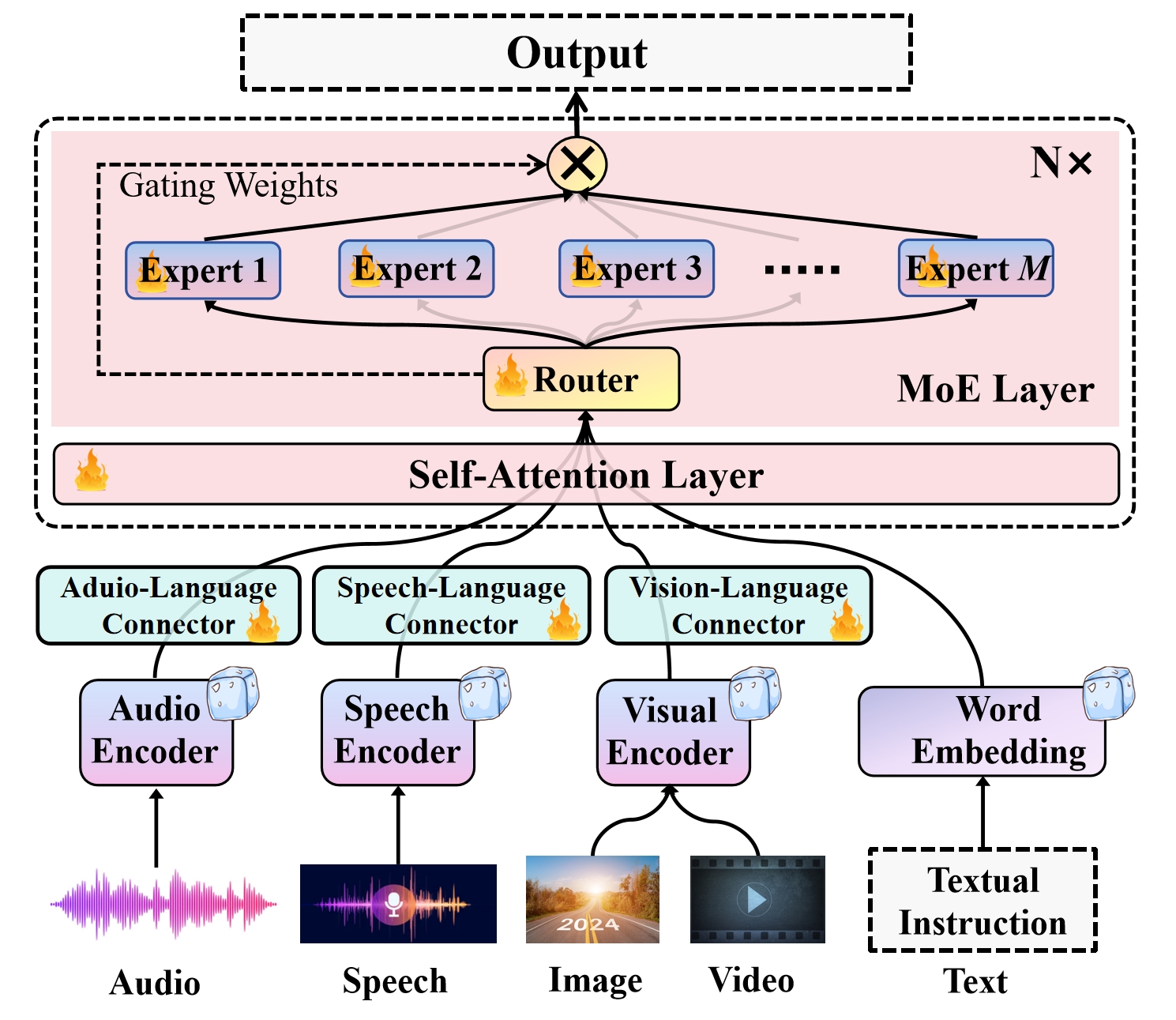
Recent advancements in Multimodal Large Language Models (MLLMs) underscore the significance of scalable models and data to boost performance, yet this often incurs substantial computational costs. Although the Mixture of Experts (MoE) architecture has been employed to efficiently scale large language and image-text models, these efforts typically involve fewer experts and limited modalities. To address this, our work presents the pioneering attempt to develop a unified MLLM with the MoE architecture, named Uni-MoE that can handle a wide array of modalities. Specifically, it features modality-specific encoders with connectors for a unified multimodal representation. We also implement a sparse MoE architecture within the LLMs to enable efficient training and inference through modality-level data parallelism and expert-level model parallelism. To enhance the multi-expert collaboration and generalization, we present a progressive training strategy: 1) Cross-modality alignment using various connectors with different cross-modality data, 2) Training modality-specific experts with cross-modality instruction data to activate experts' preferences, and 3) Tuning the Uni-MoE framework utilizing Low-Rank Adaptation (LoRA) on mixed multimodal instruction data. We evaluate the instruction-tuned Uni-MoE on a comprehensive set of multimodal datasets. The extensive experimental results demonstrate Uni-MoE's principal advantage of significantly reducing performance bias in handling mixed multimodal datasets, alongside improved multi-expert collaboration and generalization. Our findings highlight the substantial potential of MoE frameworks in advancing MLLMs and the code is available at https://github.com/HITsz-TMG/UMOE-Scaling-Unified-Multimodal-LLMs.
5/21/2024
LocMoE: A Low-Overhead MoE for Large Language Model Training
Jing Li, Zhijie Sun, Xuan He, Li Zeng, Yi Lin, Entong Li, Binfan Zheng, Rongqian Zhao, Xin Chen
0
0
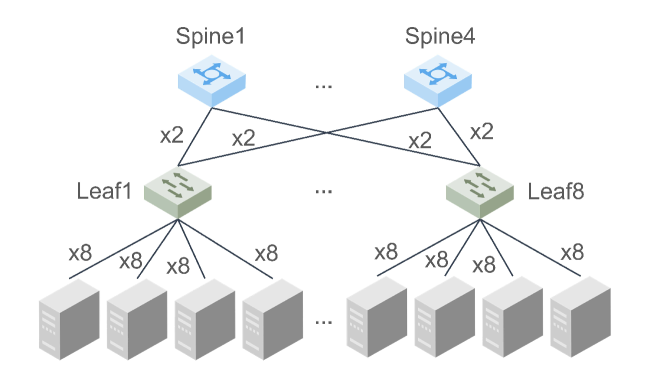
The Mixtures-of-Experts (MoE) model is a widespread distributed and integrated learning method for large language models (LLM), which is favored due to its ability to sparsify and expand models efficiently. However, the performance of MoE is limited by load imbalance and high latency of All-to-All communication, along with relatively redundant computation owing to large expert capacity. Load imbalance may result from existing routing policies that consistently tend to select certain experts. The frequent inter-node communication in the All-to-All procedure also significantly prolongs the training time. To alleviate the above performance problems, we propose a novel routing strategy that combines load balance and locality by converting partial inter-node communication to that of intra-node. Notably, we elucidate that there is a minimum threshold for expert capacity, calculated through the maximal angular deviation between the gating weights of the experts and the assigned tokens. We port these modifications on the PanGu-Sigma model based on the MindSpore framework with multi-level routing and conduct experiments on Ascend clusters. The experiment results demonstrate that the proposed LocMoE reduces training time per epoch by 12.68% to 22.24% compared to classical routers, such as hash router and switch router, without impacting the model accuracy.
5/24/2024